%%{init: {'flowchart': {'nodeSpacing': 10, 'rankSpacing': 10}}}%%
flowchart TB
A[Formulate<br/>problem] --> B[Data &<br/>Assumption] --> C([Assumptions<br/>OK?])
C -->|Yes| D[ Program<br/>model] --> E([Model<br/>OK?])
E -->|Yes| F[Analyse] --> G[Conclusion]
C -->|No| R((Revise))
E -->|No| R
R --> A
R --> B
STAT2005 Computer Simulation
Lecture 1 — Introduction to Computer Simulation
19 Feb 2026
In the mid-1940s…
Stanisław Ulam 

“What is the probability that a solitaire game can be won?”
“Why not just play a thousand times and count how often I win?”
John Von Neumann 
“If we can solve solitaire this way, we can solve anything this way.”
- Humans can’t repeat a process thousands of times quickly enough.
- Machines can.
ENIAC
(Electronic Numerical Integrator and Computer)

Together, Ulam and von Neumann developed a new method:
- simulate randomness
- repeat the process thousands of times
- let the pattern emerge from noise
- They named it Monte Carlo, after the famous casino.
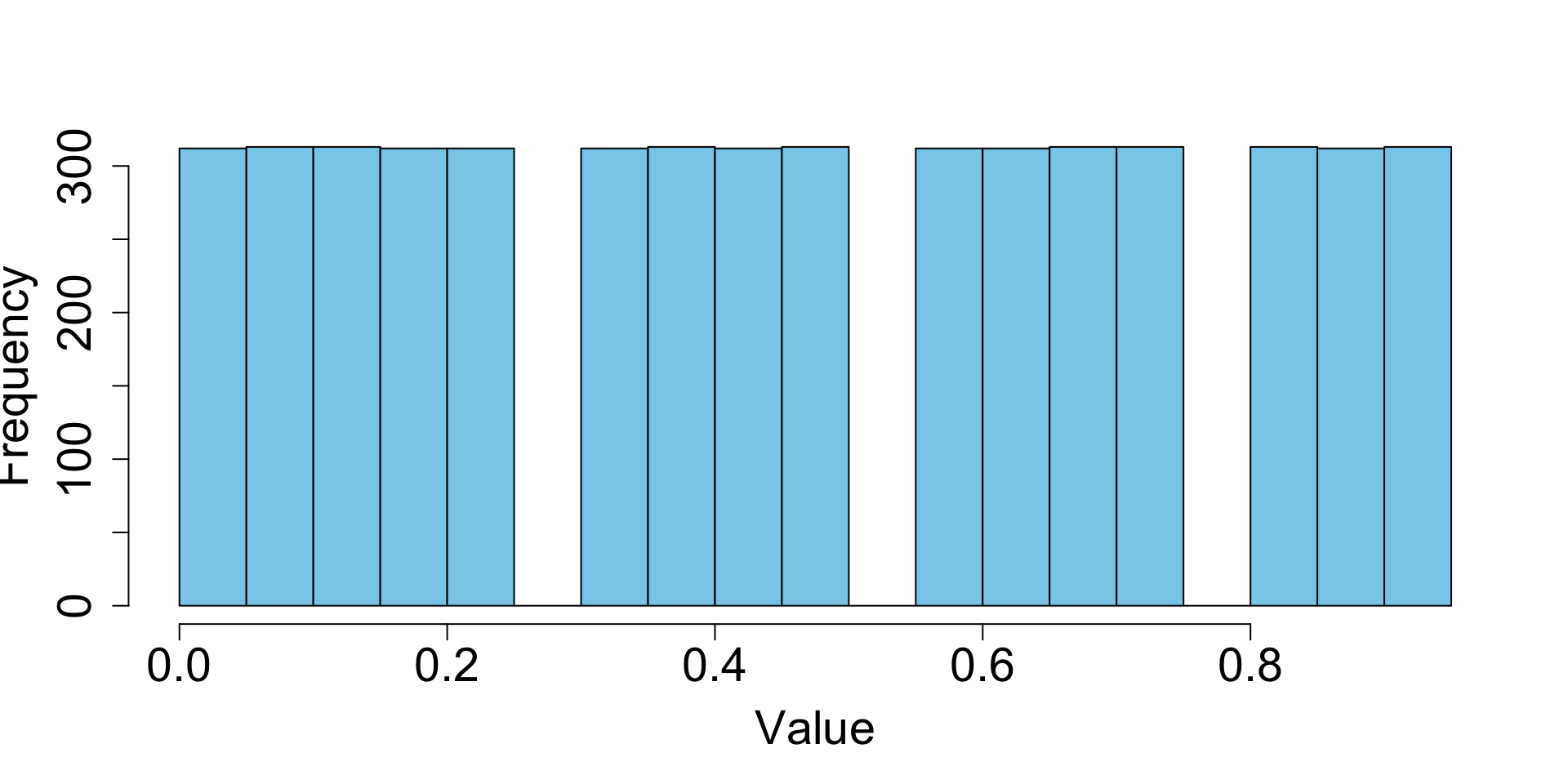
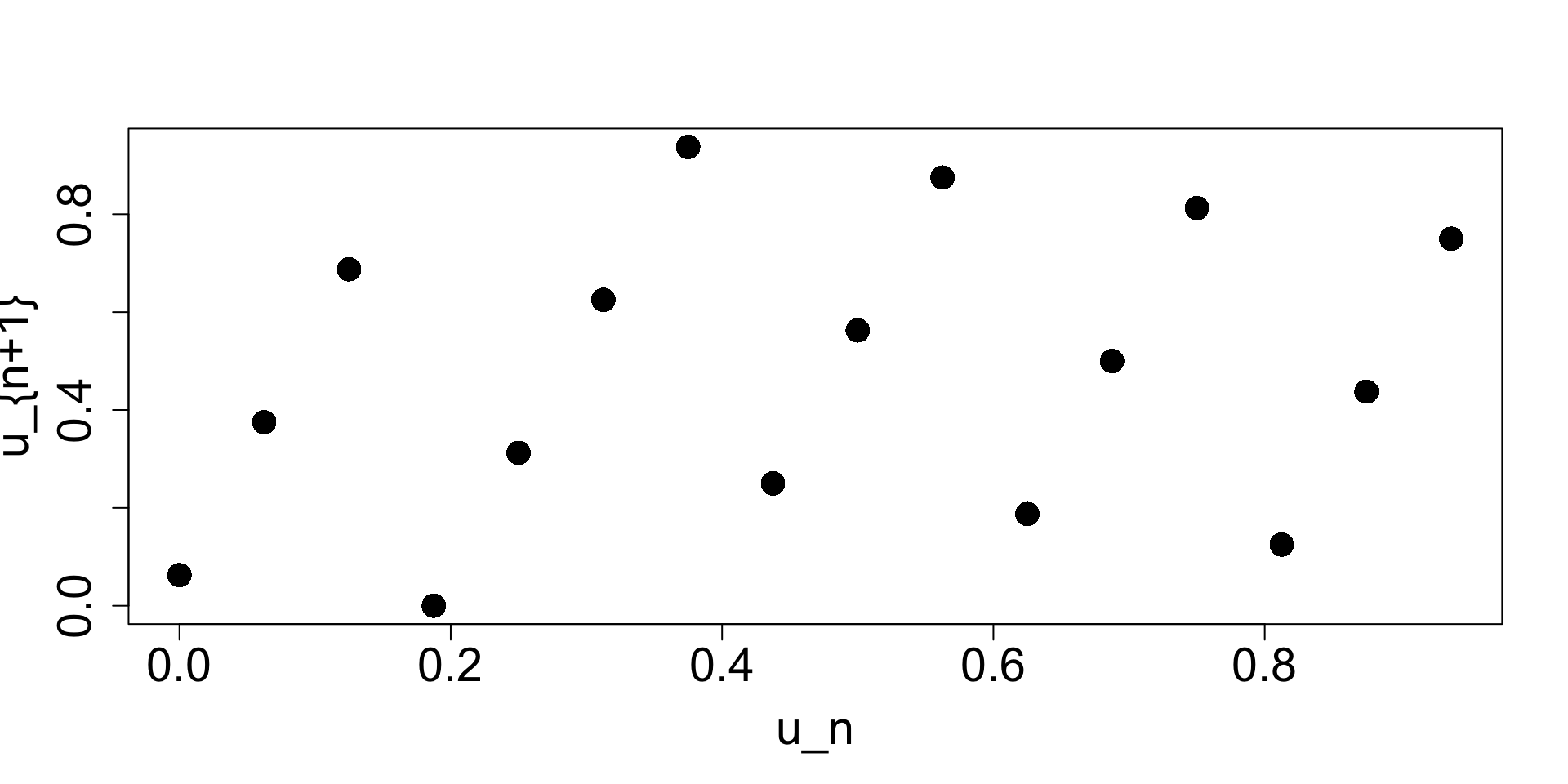
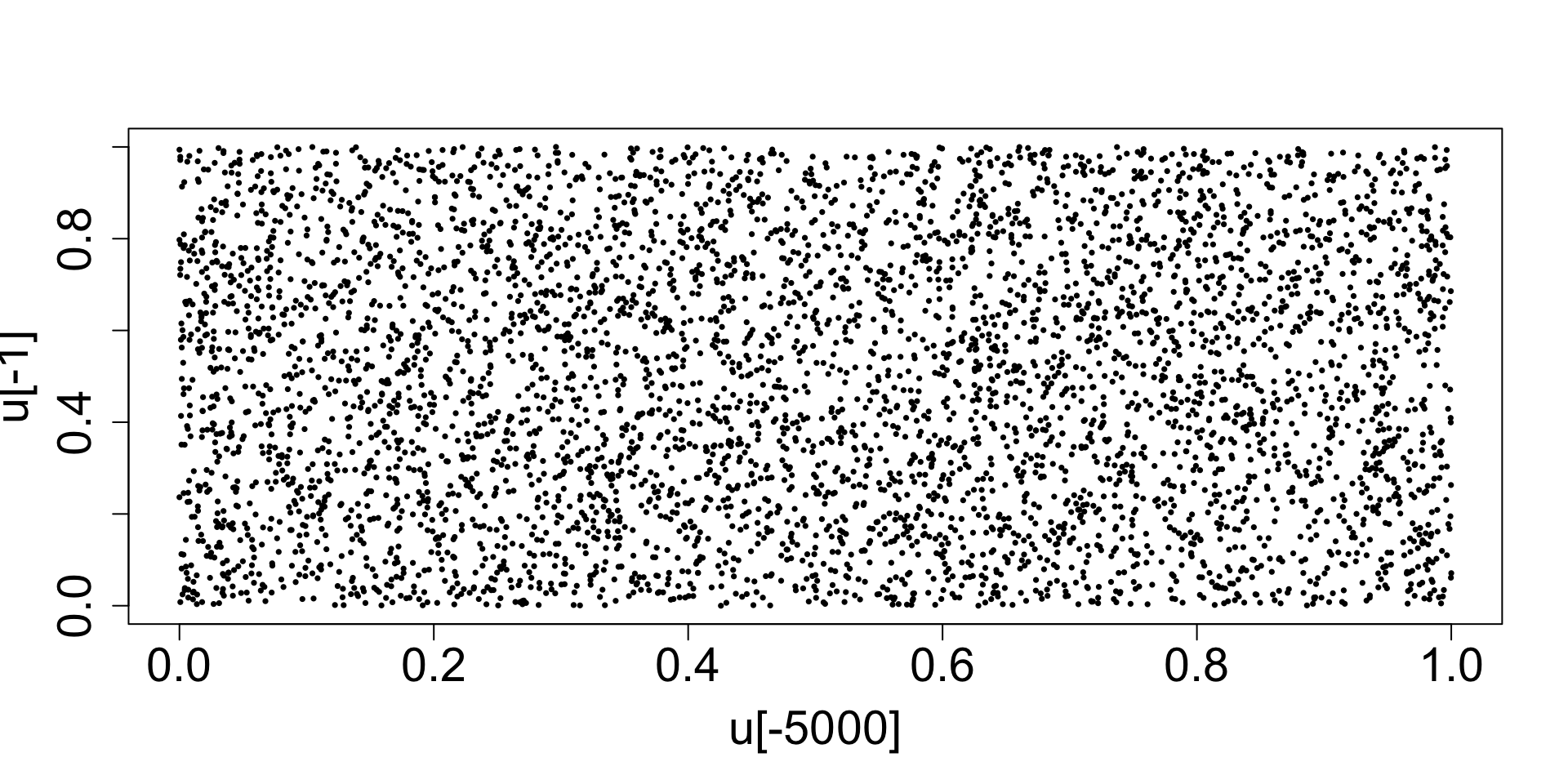
The nature of modulo arithmetic means the sequence will eventually repeat itself. Therefore, LCGs have structural weaknesses: short periods, visible lattice patterns, poor performance in high-dimensional simulations.
# Good LCG
lcg <- function(n, seed, a, c, m, as.uniform = TRUE) {
x <- numeric(n)
x[1] <- seed
for (i in 2:n) {
x[i] <- (a * x[i - 1] + c) %% m
}
if (as.uniform) {
return(x / m) # convert to Uniform(0,1)
} else {
return(x) # return raw integers
}
}
set.seed(123); u <- lcg(n=5000, seed=1, a=1664525, c=1013904223, m=2^32)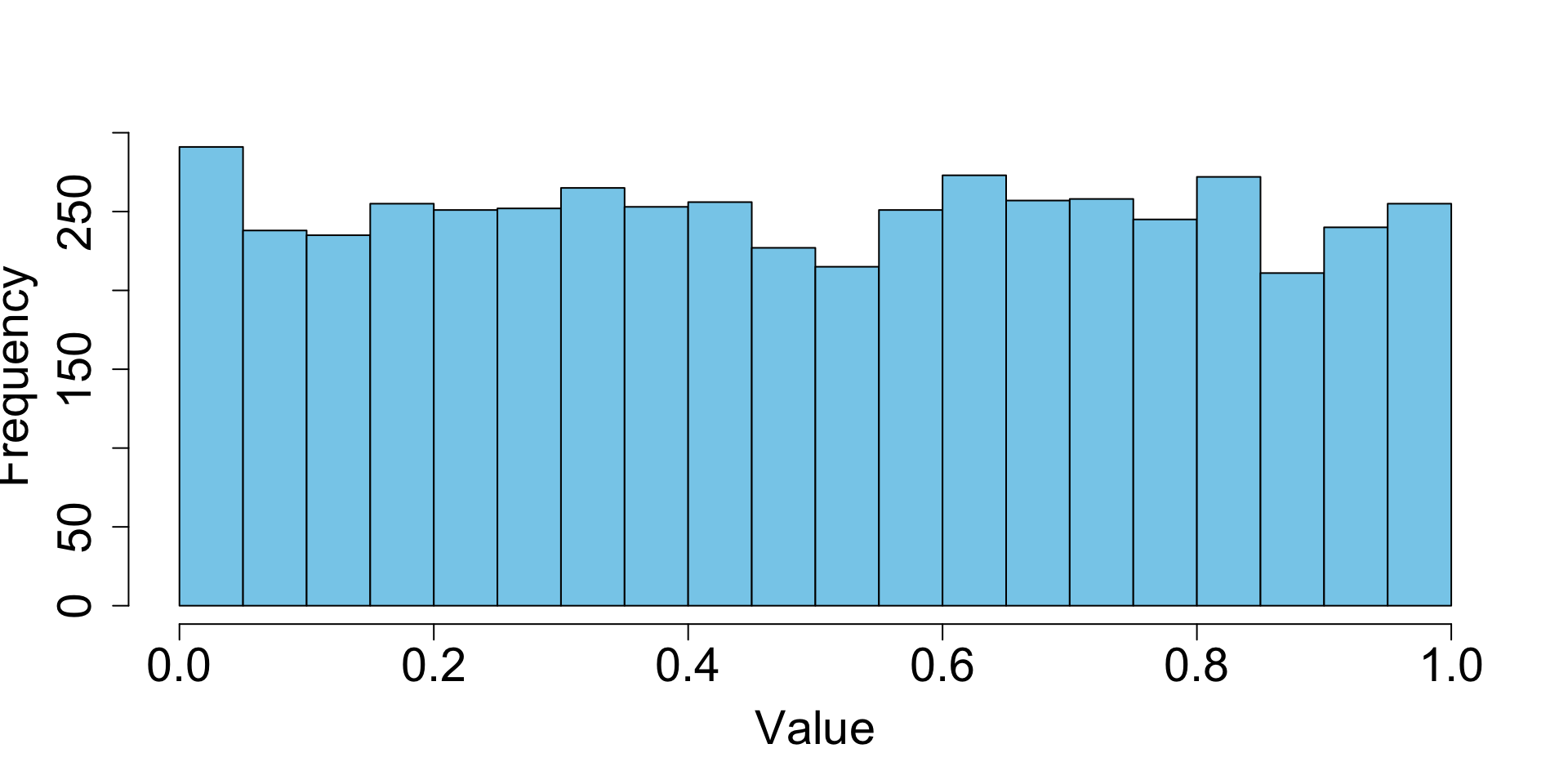
1.4.2 Uniform(0,1) Random Number (Mersenne Twister)
Mersenne Twister is the modern default pseudorandom number generator in R, Python, NumPy, MATLAB, Julia, and many other systems. It’s designed to produce high‑quality Uniform(0,1) values for simulation.
\[ U \sim Uniform(0,1) \]
- Equally likely takes values between 0 and 1
- Imagine repeatedly picking a point at random on the interval (0,1) for a thousand time.
- Over many draws, the points spread out evenly
%20Scatter-1.png)
%20Histogram-1.png)
set.seed(123)
# Step 1: generate Uniform(0,1) values
u <- runif(1000)
# Step 2: transform them into Exponential(lambda)
lambda <- 2 # rate parameter
x <- -log(1 - u) / lambda
# Step 3: Plot and compare with R's built-in rexp()
x_builtin <- rexp(1000, rate = lambda)
hist(x, breaks = 30, col = rgb(0,0,1,0.4), freq = FALSE,
main = "Comparison of PDF of exponential distribution: Transform vs rexp()")
hist(x_builtin, breaks = 30, col = rgb(1,0,0,0.4), freq = FALSE, add = TRUE)
legend("topright", legend = c("Transform", "rexp()"),
fill = c(rgb(0,0,1,0.4), rgb(1,0,0,0.4)))1.5.10 Law of Large Numbers (LLNs)
If we repeat the same random experiment many times, the average result stabilises.
Let \(X_1, X_2, \dots, X_n\) be independent, identically distributed (i.i.d.) with mean \(E[X]\).
Then as \(n \to \infty,\) \[ \bar{X}_n=\frac{1}{n}\sum_{i=1}^n X_i \;\longrightarrow\; E[X] \] (in the sense that the average gets closer to the true mean).
Simulation takeaway: more replications \(n \Rightarrow\) more stable estimates (but never perfectly exact).
Flipping a fair coin for 5000 times.
# Demonstrate the LLN with coin tosses
x <- rbinom(5000, size = 1, prob = 0.5) # 1 = Head, 0 = Tail
running_mean <- cumsum(x) / seq_len(n)
plot(running_mean, type = "l",
xlab = "Number of tosses (n)",
ylab = "Running mean (proportion of heads)",
main = "LLNs: Proportion of Heads",
cex.main = 2.2,
cex.lab = 1.8,
cex.axis = 1.8,
)
abline(h = 0.5, lwd = 2) # true mean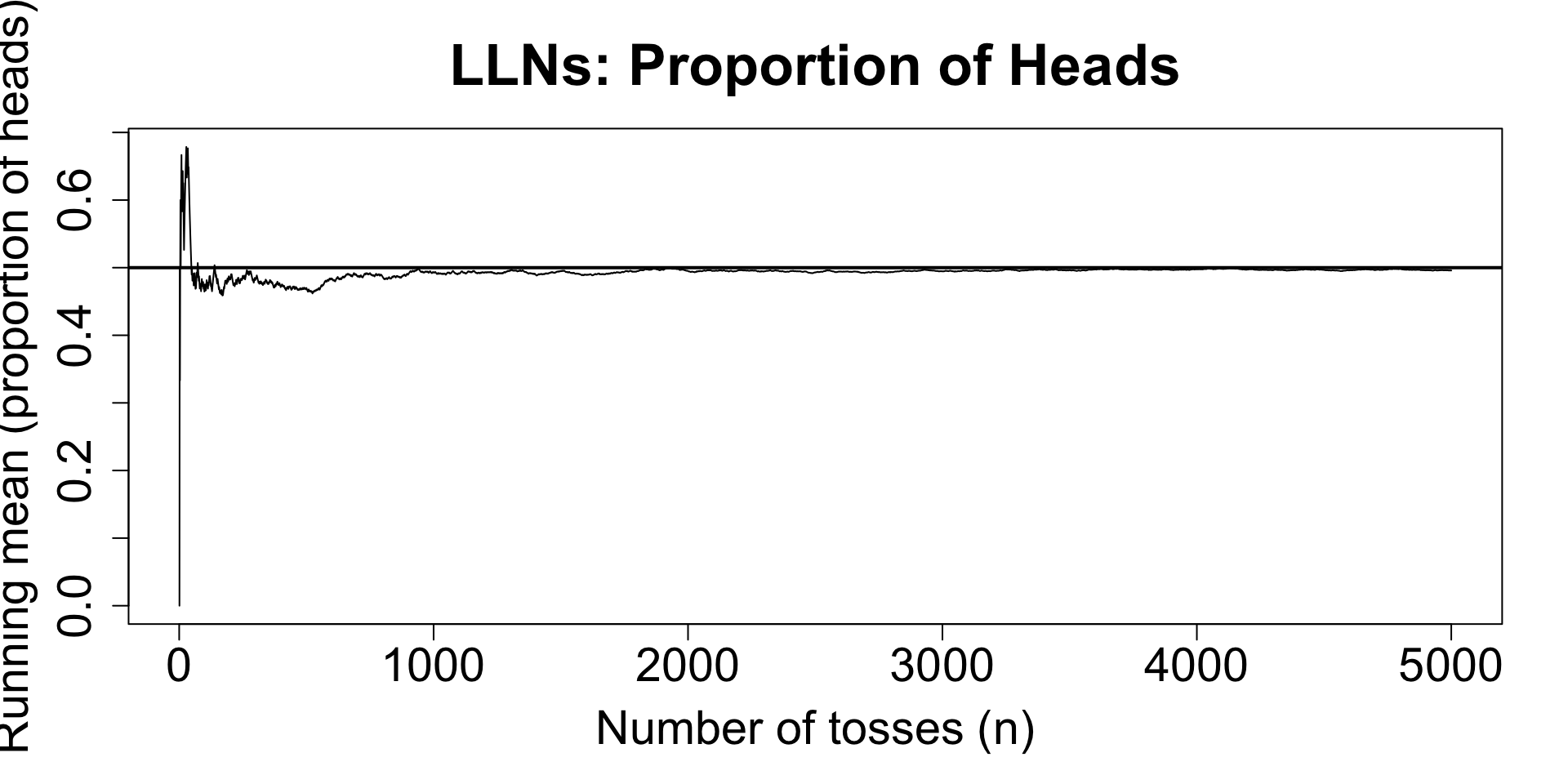
Simulate Exp(1) for 5000 times.
# LLN with an Exponential(1) random variable (true mean = 1)
x <- rexp(n, rate = 1)
running_mean <- cumsum(x) / seq_len(n)
plot(running_mean, type = "l",
xlab = "Number of samples (n)",
ylab = "Running mean",
main = "LLNs: Exponential(1)",
cex.main = 2.2,
cex.lab = 1.8,
cex.axis = 1.8,
)
abline(h = 1, lwd = 2) # true mean-1.png)