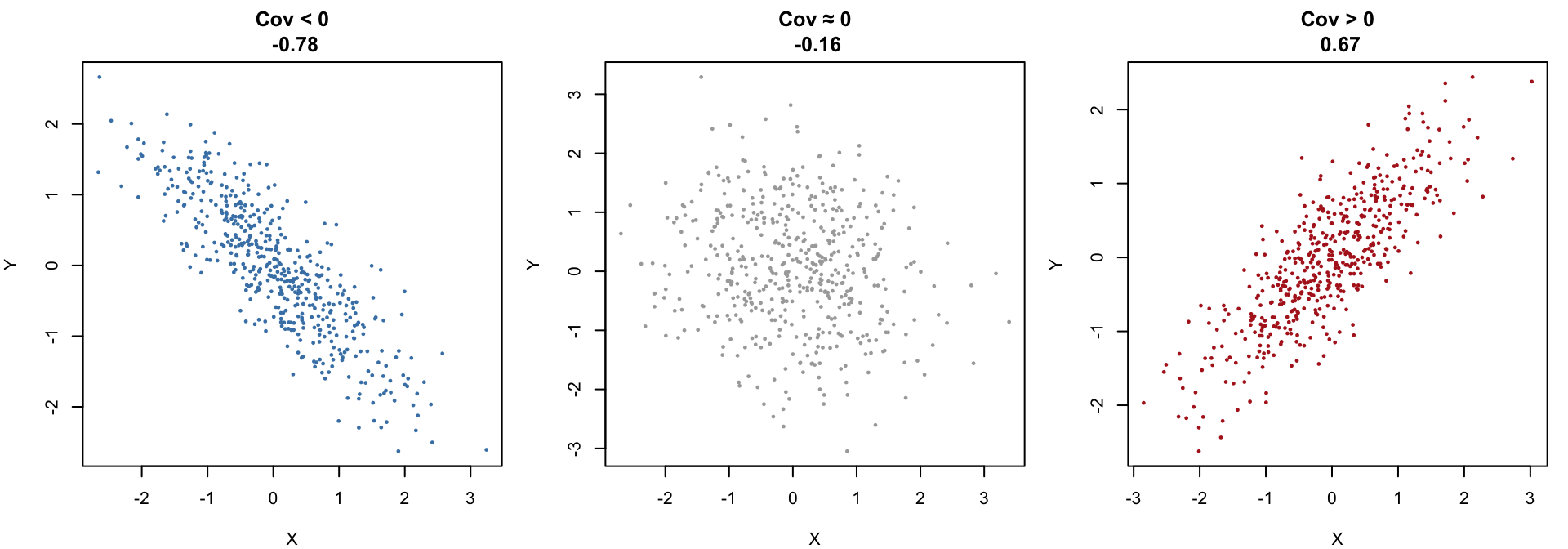
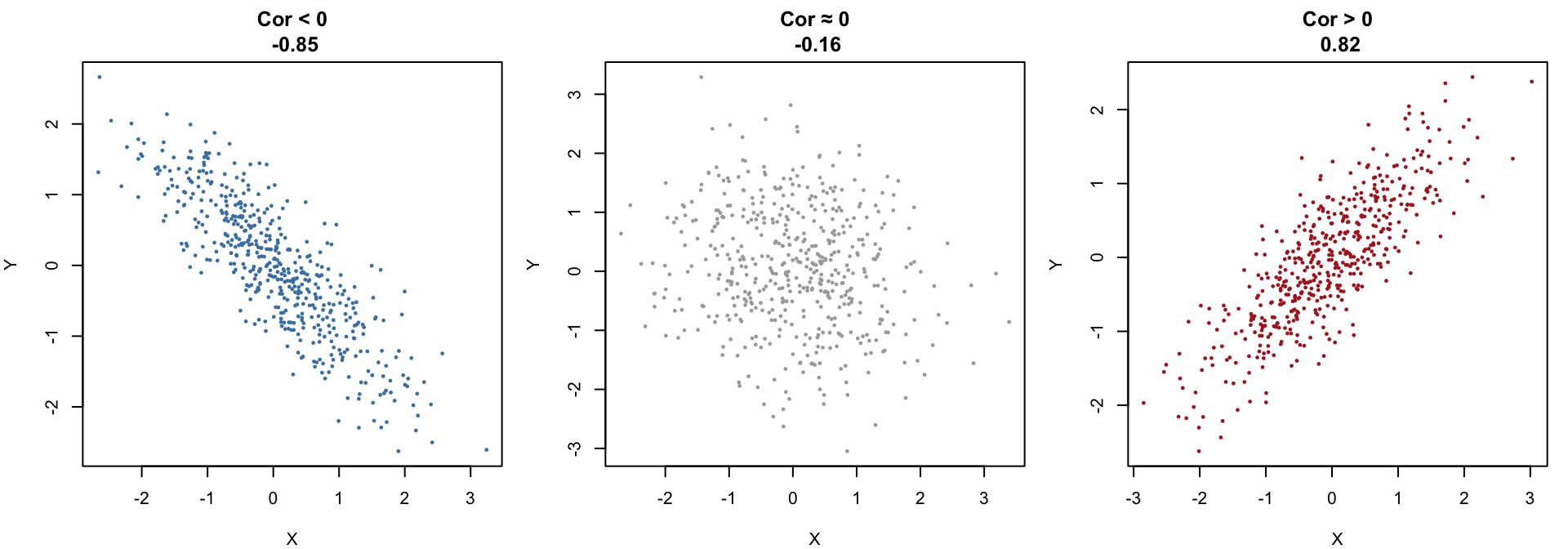
library(mvtnorm)
# Grid for evaluation
x <- seq(-3, 3, length = 50)
y <- seq(-3, 3, length = 50)
grid <- expand.grid(x = x, y = y)
# Function to compute BVN density matrix
bvn_matrix <- function(rho) {
Sigma <- matrix(c(1, rho, rho, 1), 2, 2)
z <- dmvnorm(grid, mean = c(0, 0), sigma = Sigma)
matrix(z, nrow = length(x), ncol = length(y))
}
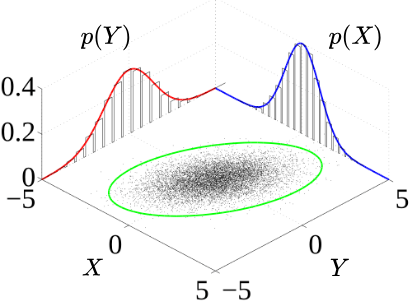
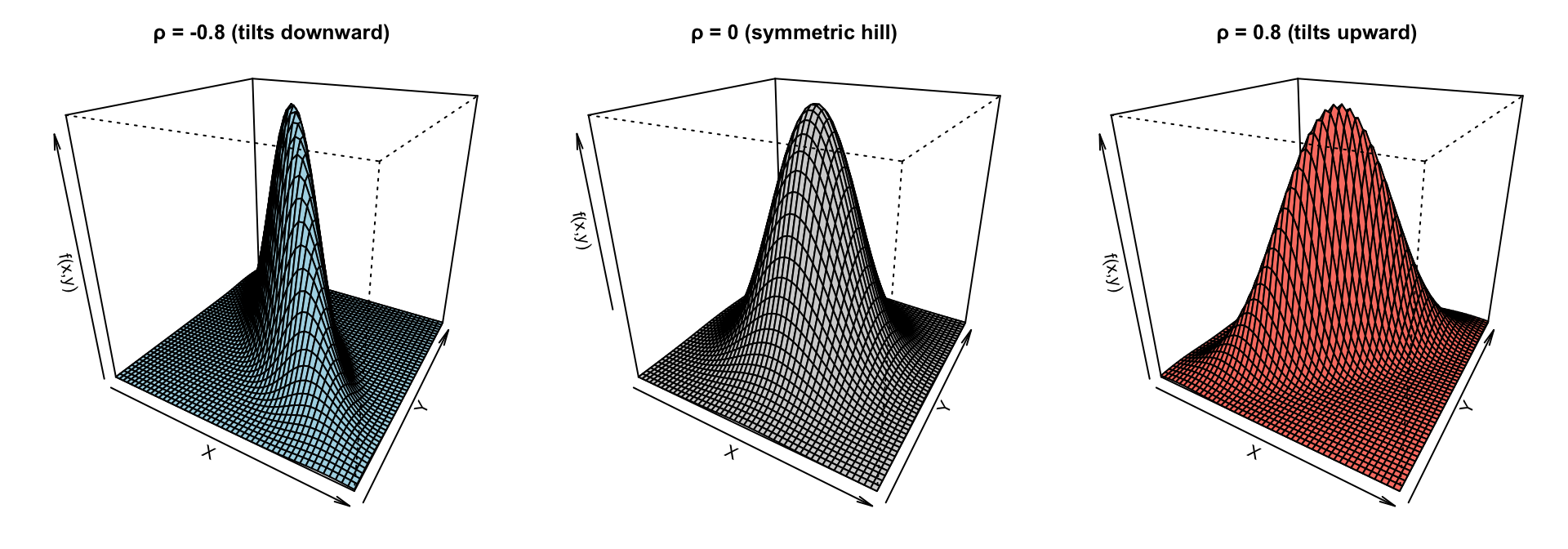
z_neg <- bvn_matrix(-0.8)
z_zero <- bvn_matrix(0)
z_pos <- bvn_matrix(0.8)
par(mfrow = c(1, 3), mar = c(2, 2, 3, 1))
# 1. Negative correlation
persp(x, y, z_neg,
theta = 30, phi = 25,
col = "lightblue",
main = "ρ = -0.8 (tilts downward)",
xlab = "X", ylab = "Y", zlab = "f(x,y)")
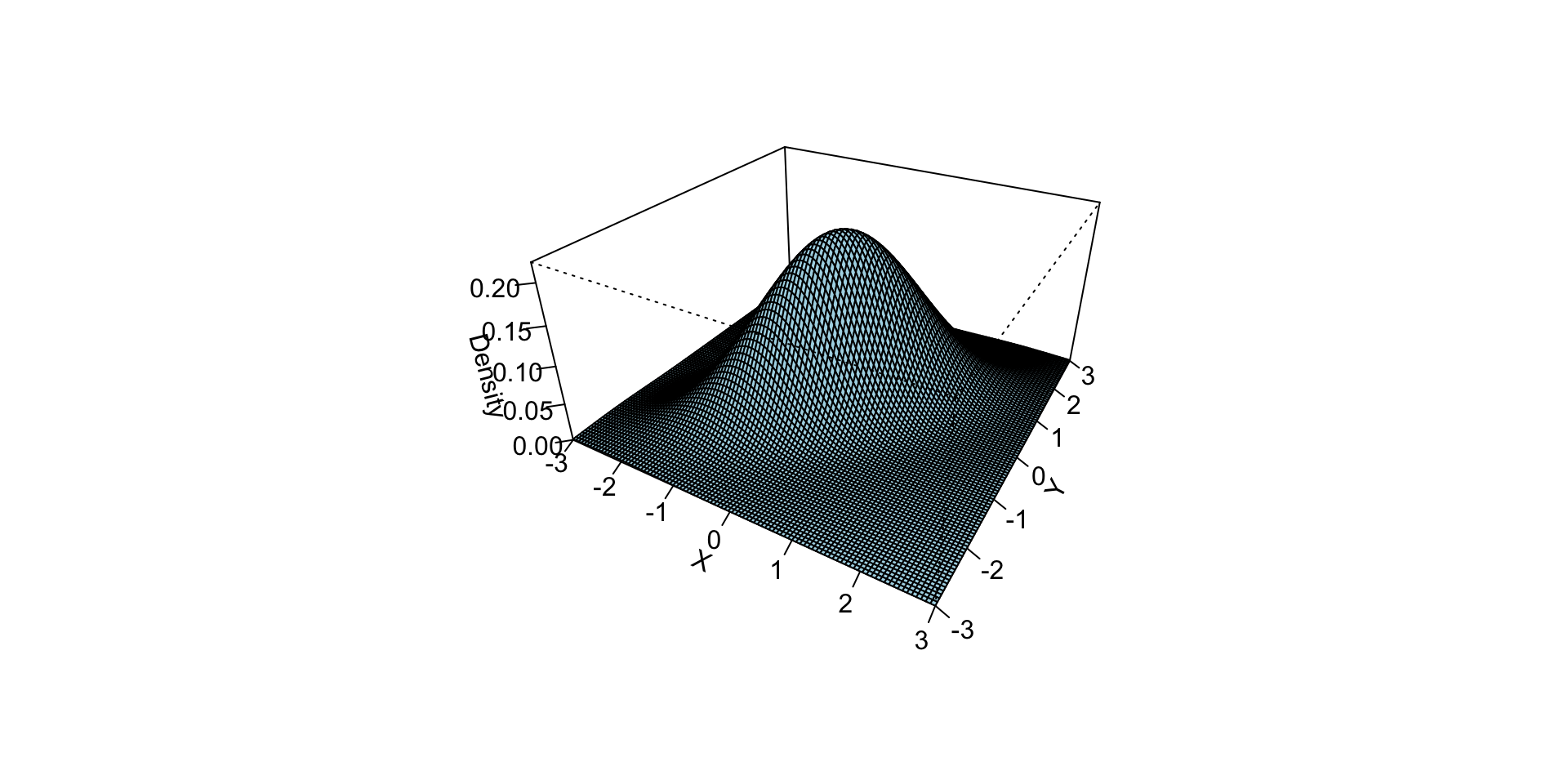
# 2. Zero correlation
persp(x, y, z_zero,
theta = 30, phi = 25,
col = "lightgray",
main = "ρ = 0 (symmetric hill)",
xlab = "X", ylab = "Y", zlab = "f(x,y)")
# 3. Positive correlation
persp(x, y, z_pos,
theta = 30, phi = 25,
col = "salmon",
main = "ρ = 0.8 (tilts upward)",
xlab = "X", ylab = "Y", zlab = "f(x,y)")
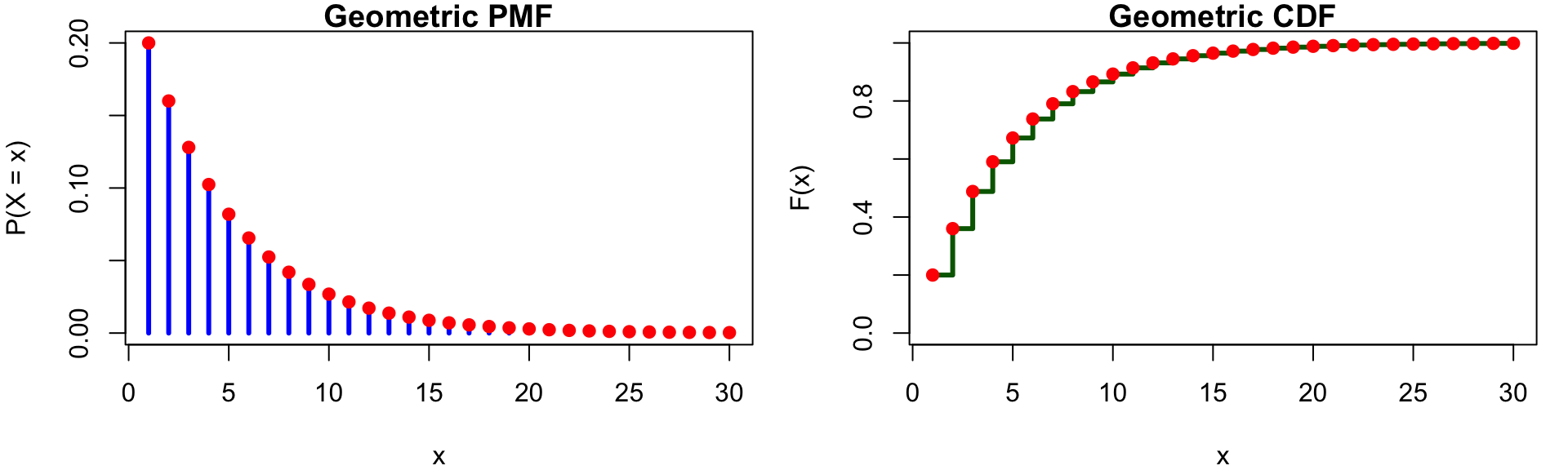
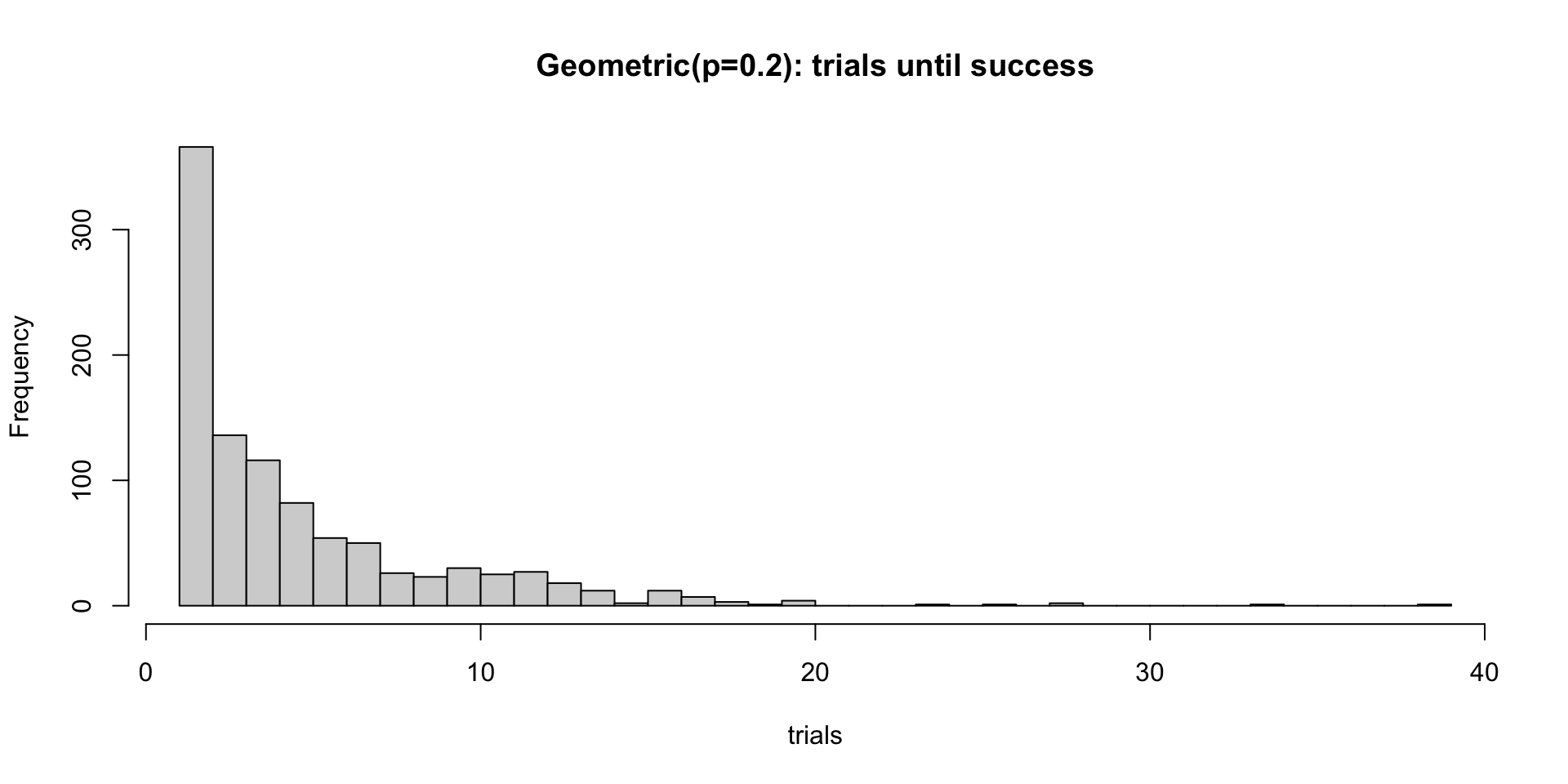
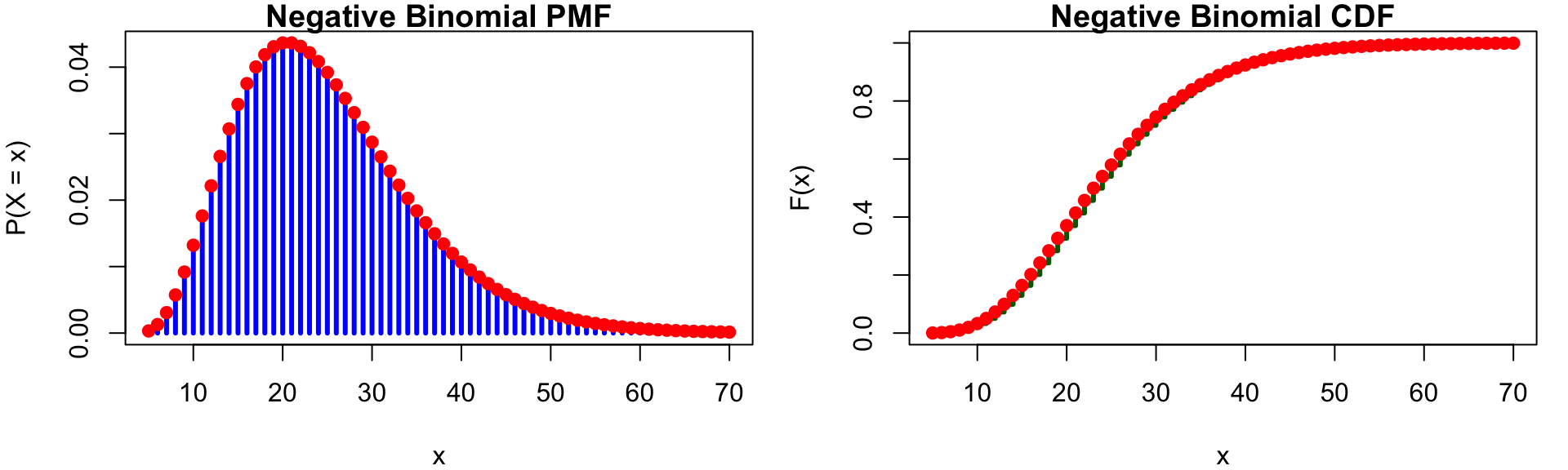
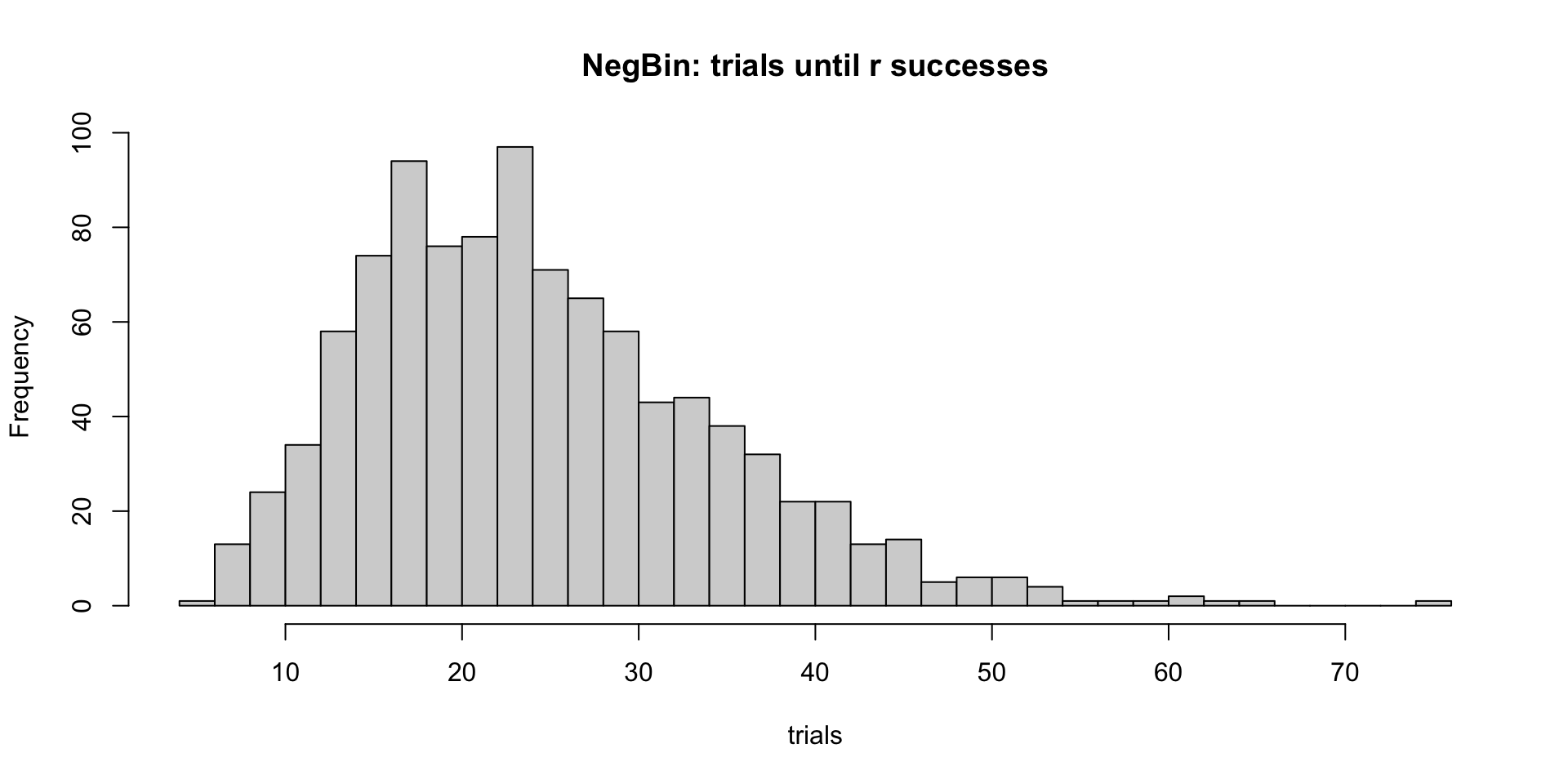
{kind=link}