[1] -0.01700378STAT2005 Computer Simulation
Lecture 3 — Joint Distributions and Statistical Inference
5 Mar 2026
Joint distributions
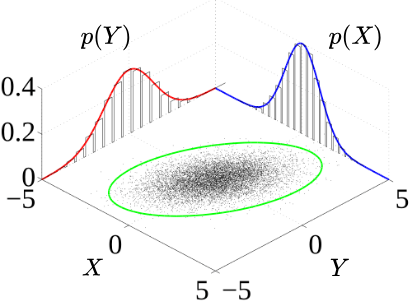
Figure 1: Joint probability distribution samples (black) and marginal densities (blue and red)
- The surface is the joint density \(f_{X,Y}(x,y)\).
- The curves along the axes are the marginals \(f_X(x)\) and \(f_Y(y)\).
- The scatter cloud (in green circle) shows sample points from the joint distribution.
A joint distribution is a multivariate distribution. It is the probability structure that describes how several random variables behave together.
For two variables \(X\) and \(Y\), the joint distribution \(f_{X,Y}(x,y)\) is a bivariate distribution.
For \(k\) variables, \(X_1, \dots, X_k\), the joint distribution \(f_{X_1,\dots ,X_k}(x_1,\dots ,x_k)\) is a multivariate distribution.
Continuous Case Example
Let X and Y be continuous independent random variables \(X\sim \mathcal{N}(0,1)\) and \(Y\sim \mathcal{N}(5,4)\)
Because of independence:
\[f_{X,Y}(x,y)=f_X(x)\, f_Y(y)=\frac{1}{\sqrt{2\pi }}e^{-x^2/2}\times \frac{1}{\sqrt{8\pi }}e^{-(y-5)^2/8}\]
[1] -0.7032966Code
y <- 0:10
pmf_A <- dbinom(y, size = 10, prob = 0.7) # X = 0 (Type A)
pmf_B <- dbinom(y, size = 10, prob = 0.4) # X = 1 (Type B)
# Set up side-by-side plotting area
par(mfrow = c(2, 1), mar = c(4, 4, 0, 1))
# PMF for X = 0
barplot(
pmf_A,
names.arg = y,
col = "steelblue",
main = "",
xlab = "Y",
ylab = "P(Y | X = 0)",
ylim = c(0, max(pmf_A, pmf_B))
)
# PMF for X = 1
barplot(
pmf_B,
names.arg = y,
col = "firebrick",
main = "",
xlab = "Y",
ylab = "P(Y | X = 1)",
ylim = c(0, max(pmf_A, pmf_B))
)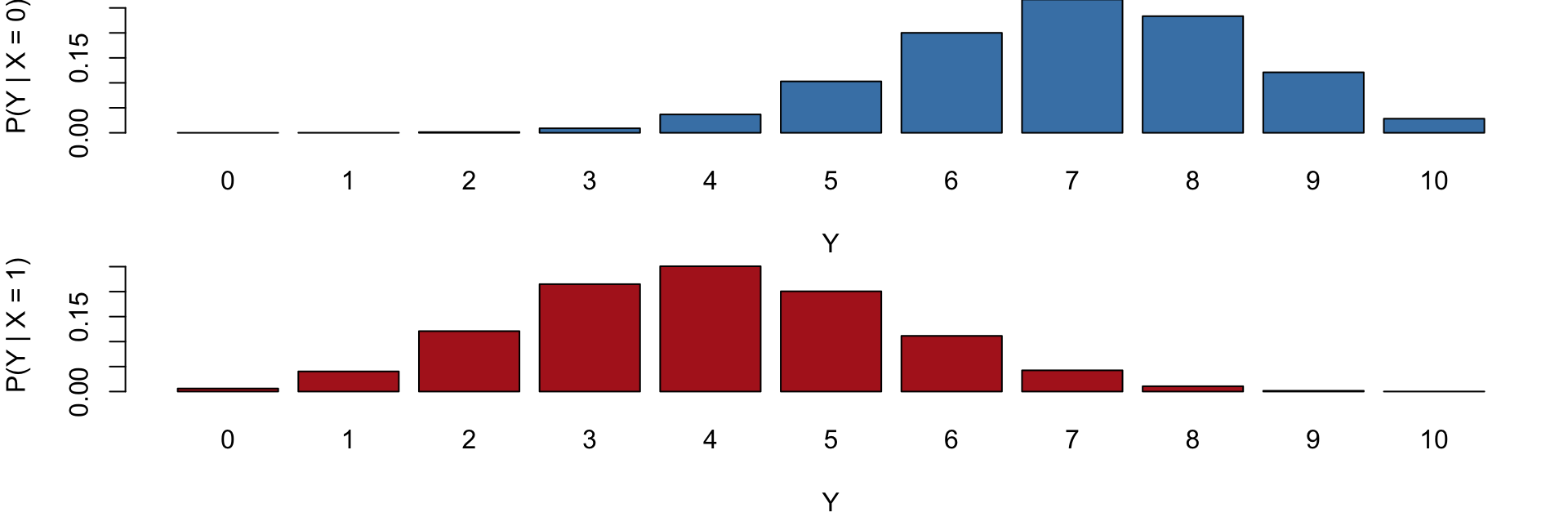
- \(P(Y \mid X=0)\) (Type A) are concentrated at higher values of \(Y \rightarrow\) baristas complete more order on average.
- \(P(Y \mid X=1)\) (Type B) shifts downward, with higher probability on smaller values of \(Y\).
- Note: the value of \(X\) changes the entire shape of the distribution of \(Y\), not just its mean (dependency).
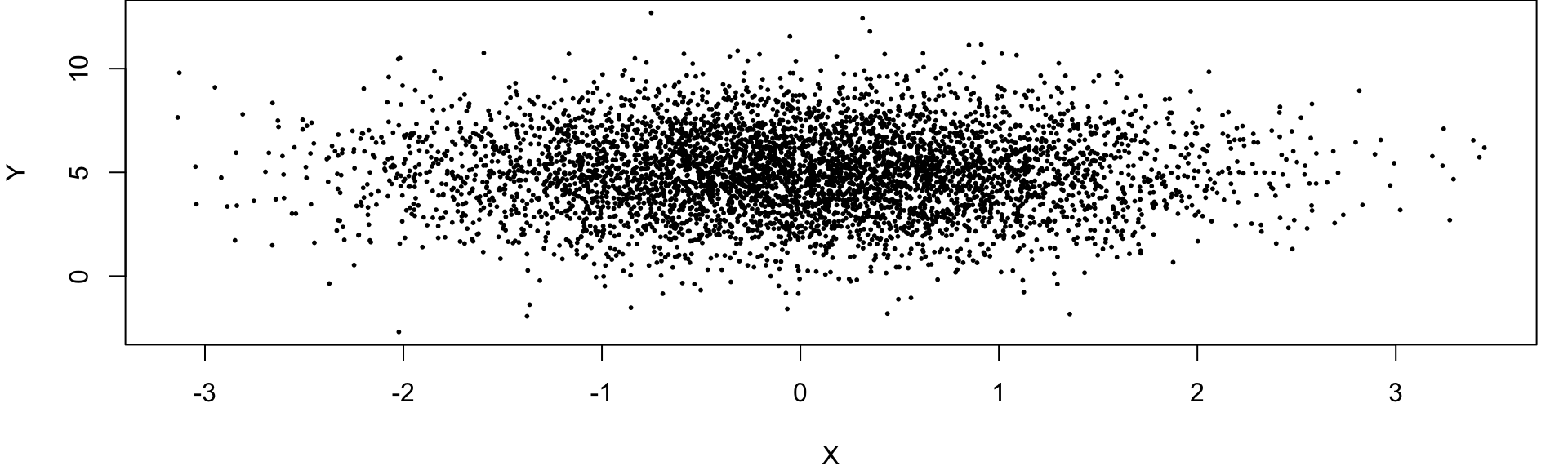
Continuous Case Example
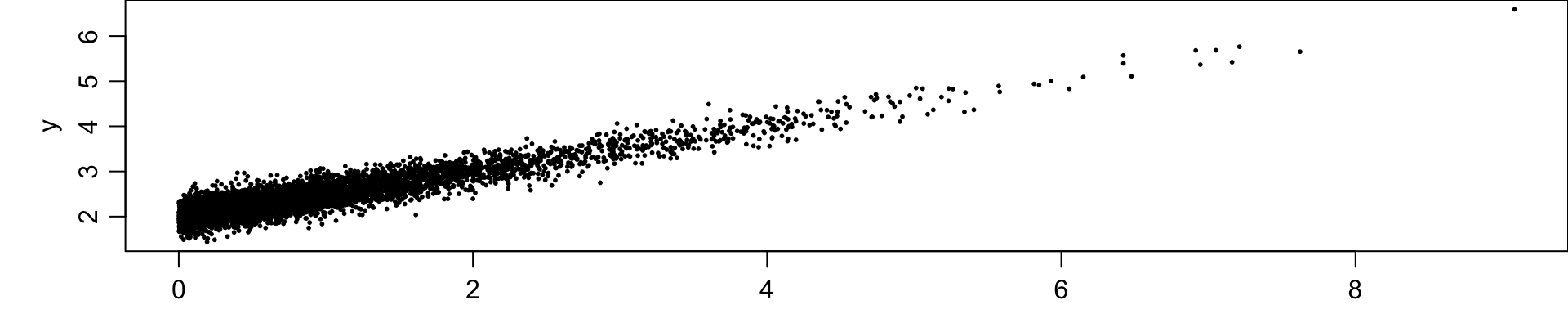
Suppose interarrival time \(X\) of a coffee shop influences service time \(Y\), such that
\[ Y = 2 + 0.5X + \varepsilon, \]
\[ X \sim \text{Exp}(1), \quad \varepsilon \sim N(0, 0.2^2), \]
and \(X\) and \(\varepsilon\) are independent.
- When customers arrive slowly (large \(X\)), baristas work more carefully.
- When arrivals are rapid (small \(X\)), service is faster.
{kind=link}
- Very high correlation. The scatterplot reveals a clear linear trend, and the correlation is positive.
The sign of the covariance of two random variables \(X\) and \(Y\)
Code
set.seed(123)
par(mfrow = c(1, 3), mar = c(4, 4, 3, 1))
### 1. Negative covariance
x1 <- rnorm(500)
y1 <- -0.8 * x1 + rnorm(500, sd = 0.5)
plot(x1, y1,
pch = 16, cex = 0.5, col = "steelblue",
main = paste("Cov < 0\n", round(cov(x1, y1), 2)),
xlab = "X", ylab = "Y")
### 2. Approximately zero covariance
x2 <- rnorm(500)
y2 <- rnorm(500)
plot(x2, y2,
pch = 16, cex = 0.5, col = "darkgray",
main = paste("Cov ≈ 0\n", round(cov(x2, y2), 2)),
xlab = "X", ylab = "Y")
### 3. Positive covariance
x3 <- rnorm(500)
y3 <- 0.8 * x3 + rnorm(500, sd = 0.5)
plot(x3, y3,
pch = 16, cex = 0.5, col = "firebrick",
main = paste("Cov > 0\n", round(cov(x3, y3), 2)),
xlab = "X", ylab = "Y")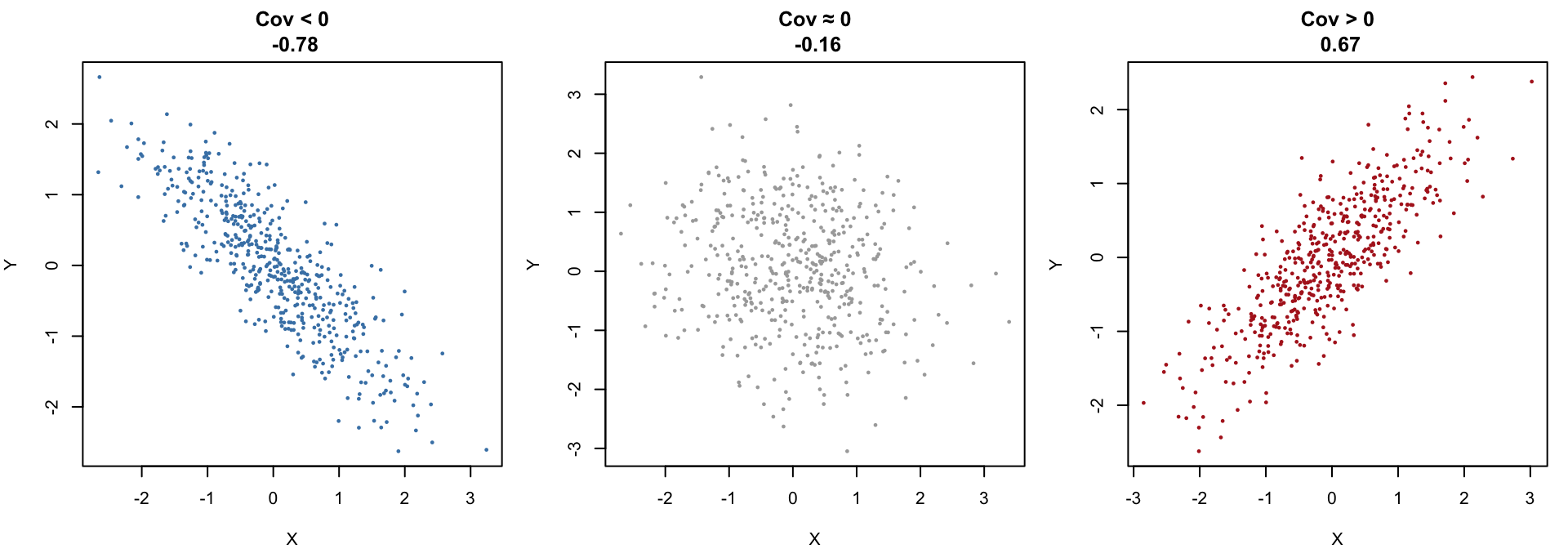
- \(\text{Cov}(X, Y) < 0\) shows a clear downward trend. As \(X\) increases, \(Y\) tends to decrease.
- \(\text{Cov}(X, Y) ≈ 0\) shows a round, structureless cloud — classic independence‑looking scatter.
- \(\text{Cov}(X, Y) > 0\) shows a clear upward trend. As \(X\) increases, \(Y\) tends to increase.
The sign of the correlation of two random variables \(X\) and \(Y\)
Code
set.seed(123)
par(mfrow = c(1, 3), mar = c(4, 4, 3, 1))
### 1. Negative correlation
x1 <- rnorm(500)
y1 <- -0.8 * x1 + rnorm(500, sd = 0.5)
plot(x1, y1,
pch = 16, cex = 0.5, col = "steelblue",
main = paste("Cor < 0\n", round(cor(x1, y1), 2)),
xlab = "X", ylab = "Y")
### 2. Approximately zero correlation
x2 <- rnorm(500)
y2 <- rnorm(500)
plot(x2, y2,
pch = 16, cex = 0.5, col = "darkgray",
main = paste("Cor ≈ 0\n", round(cor(x2, y2), 2)),
xlab = "X", ylab = "Y")
### 3. Positive correlation
x3 <- rnorm(500)
y3 <- 0.8 * x3 + rnorm(500, sd = 0.5)
plot(x3, y3,
pch = 16, cex = 0.5, col = "firebrick",
main = paste("Cor > 0\n", round(cor(x3, y3), 2)),
xlab = "X", ylab = "Y")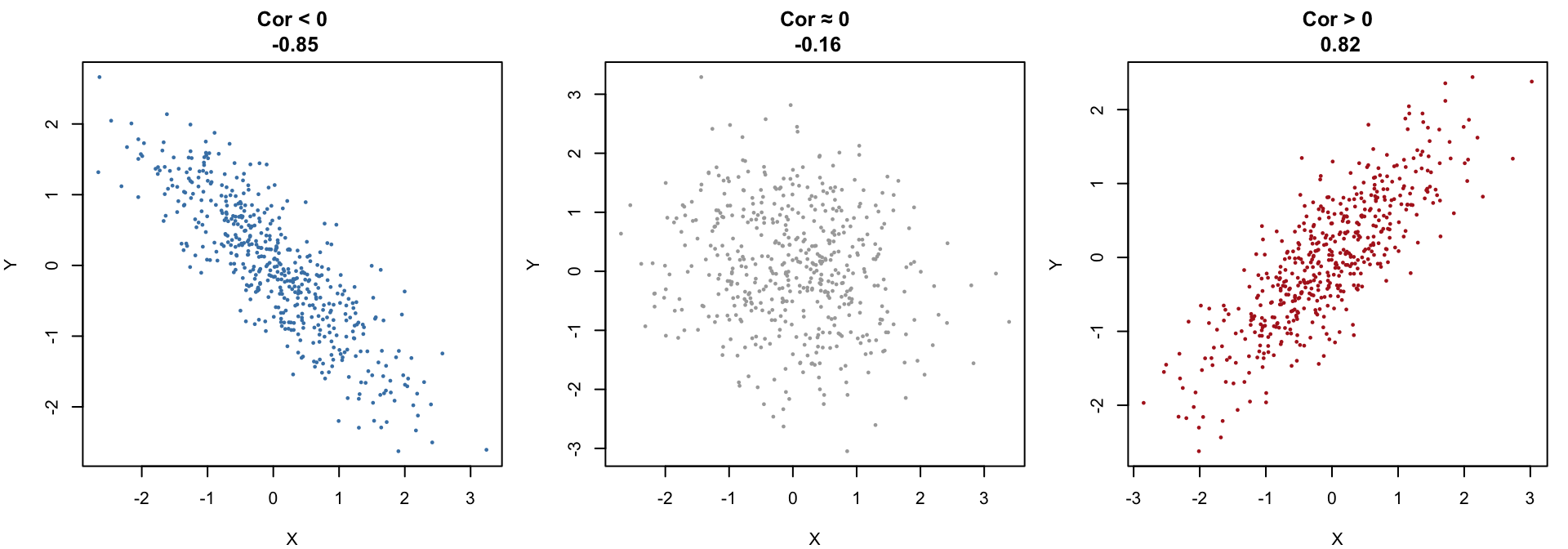
\(\rho_{XY} < 0\) indicates a clear downward linear trend: as \(X\) increases, \(Y\) tends to decrease.
\(\rho_{XY} \approx 0\) produces a round, structureless cloud of points with no visible upward or downward tilt — the classic “no linear association” look.
\(\rho_{XY} > 0\) indicates a clear upward linear trend: as \(X\) increases, \(Y\) tends to increase.
Key properties
Each marginal is normal \(\quad X\sim N(\mu _X,\sigma _X^2),\qquad Y\sim N(\mu _Y,\sigma _Y^2)\)
The joint density forms a 3D bell surface The height of the surface at point \((x,y)\) is the joint density \(f_{X,Y}(x,y).\) The shape of this surface depends heavily on the correlation \(\rho.\)
Contours are ellipses. If you slice the 3D surface horizontally, you get ellipses. The orientation of the ellipse tells you the sign of the correlation.
Independence happens only when \(\rho =0\). This is not true for most distributions. It’s a unique property of the multivariate normal family.
3D bivariate normal surfaces for different correlations
library(mvtnorm)
# Grid for evaluation
x <- seq(-3, 3, length = 50)
y <- seq(-3, 3, length = 50)
grid <- expand.grid(x = x, y = y)
# Function to compute BVN density matrix
bvn_matrix <- function(rho) {
Sigma <- matrix(c(1, rho, rho, 1), 2, 2)
z <- dmvnorm(grid, mean = c(0, 0), sigma = Sigma)
matrix(z, nrow = length(x), ncol = length(y))
}
z_neg <- bvn_matrix(-0.8)
z_zero <- bvn_matrix(0)
z_pos <- bvn_matrix(0.8)
par(mfrow = c(1, 3), mar = c(2, 2, 3, 1))
# 1. Negative correlation
persp(x, y, z_neg,
theta = 30, phi = 25,
col = "lightblue",
main = "ρ = -0.8 (tilts downward)",
xlab = "X", ylab = "Y", zlab = "f(x,y)")
# 2. Zero correlation
persp(x, y, z_zero,
theta = 30, phi = 25,
col = "lightgray",
main = "ρ = 0 (symmetric hill)",
xlab = "X", ylab = "Y", zlab = "f(x,y)")
# 3. Positive correlation
persp(x, y, z_pos,
theta = 30, phi = 25,
col = "salmon",
main = "ρ = 0.8 (tilts upward)",
xlab = "X", ylab = "Y", zlab = "f(x,y)")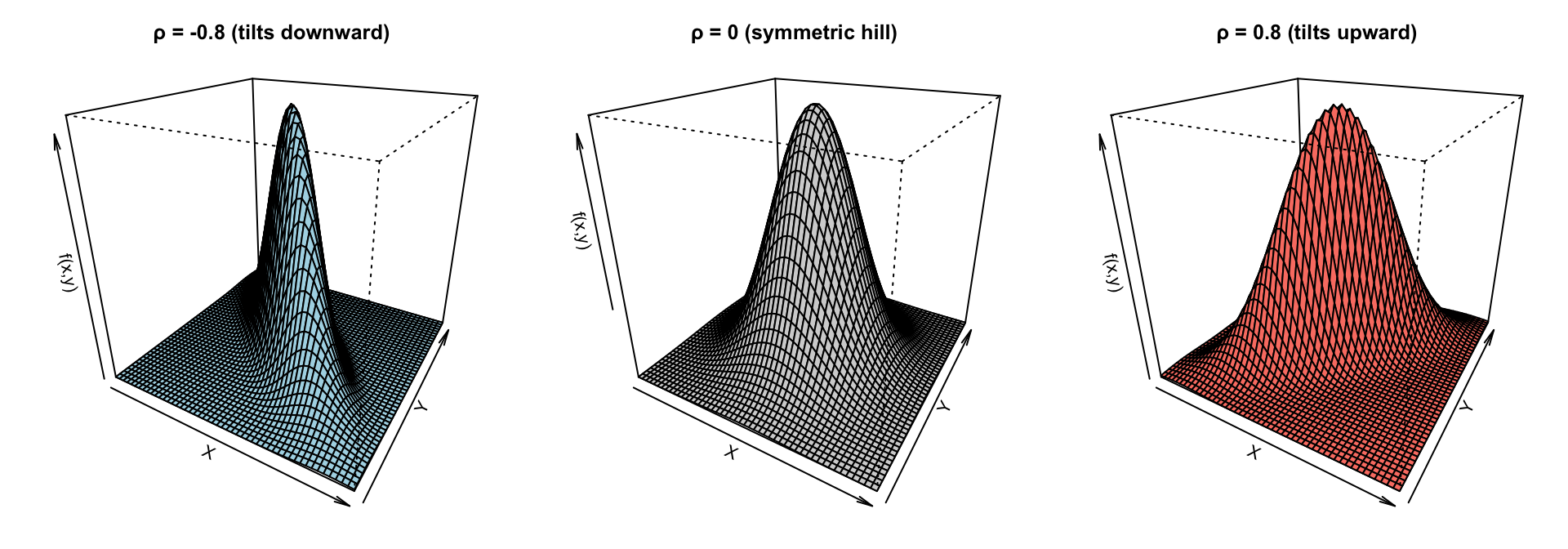
We can simulate correlated normals using a linear transformation:
\[ X = Z_1, \qquad Y = \rho Z_1 + \sqrt{1-\rho^2} Z_2 \]
[1] 0.7963105Code
# Define parameters
rho <- 0.7
# Create grid
x <- seq(-3, 3, length = 100)
y <- seq(-3, 3, length = 100)
grid <- expand.grid(x = x, y = y)
# Bivariate normal density (mean=0, var=1)
f <- function(x, y, rho) {
1/(2*pi*sqrt(1 - rho^2)) *
exp(-(x^2 - 2*rho*x*y + y^2) / (2*(1 - rho^2)))
}
# Compute density values
z <- matrix(f(grid$x, grid$y, rho), nrow = 100)
par(mar = c(0, 0, 0, 0))
# 3D perspective plot
persp(x, y, z,
theta = 30, phi = 30,
expand = 0.5,
col = "lightblue",
xlab = "X",
ylab = "Y",
zlab = "Density",
ticktype = "detailed")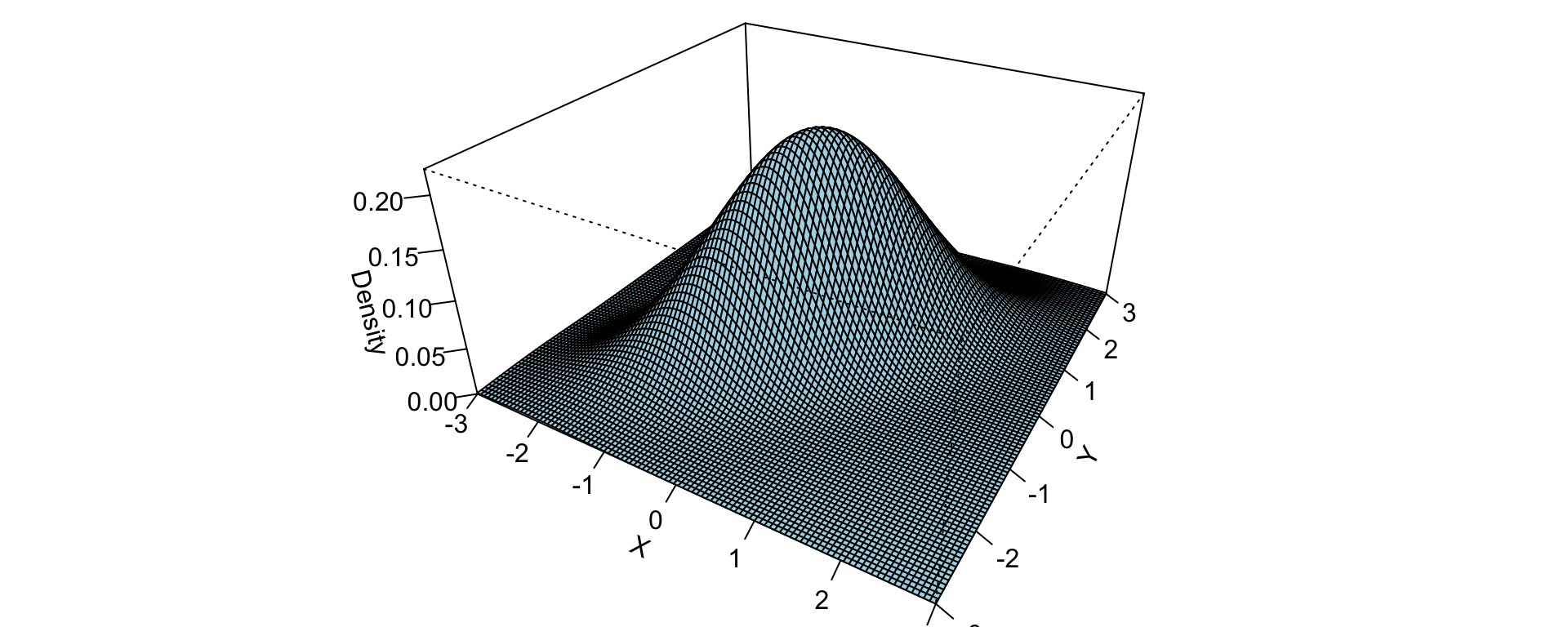
Code
loglik <- function(p, s, n) {
s * log(p) + (n - s) * log(1 - p)
}
# Grid of p values
p_grid <- seq(0.001, 0.999, length.out = 500)
# Compute log-likelihood
ll_values <- loglik(p_grid, s, n)
# Plot
plot(p_grid, ll_values,
type = "l",
xlab = "p",
ylab = "Log-Likelihood",
main = "Log-Likelihood for Bernoulli(p)")
# Add MLE
abline(v = p_hat, lty = 2, col="red")
# Add true parameter (optional)
abline(v = p_true, lty = 3, col="blue")
# Legend
legend("topright",
legend = c("MLE (p_hat)", "True p"),
col = c("red", "blue"),
lty = c(2,3))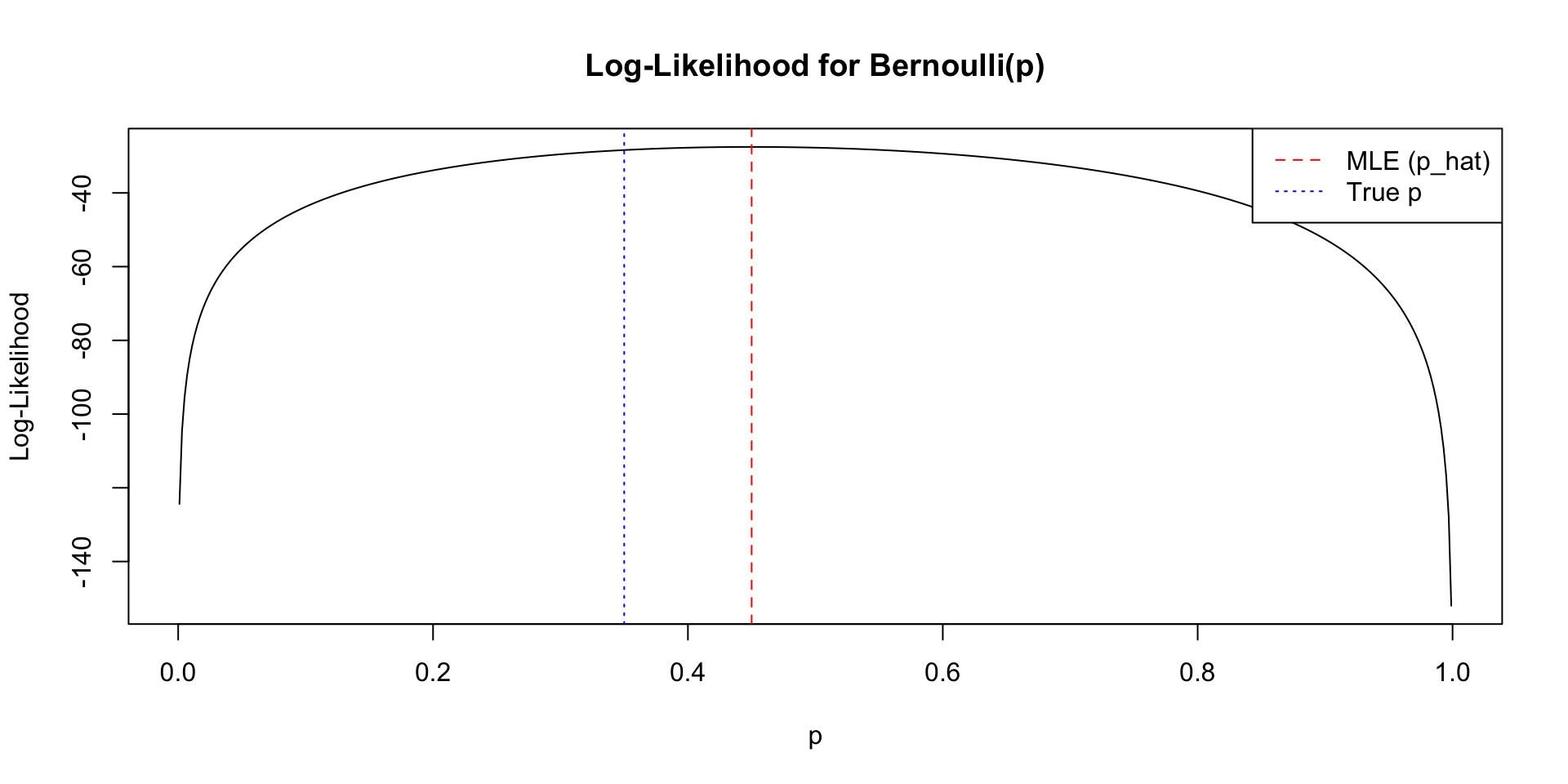
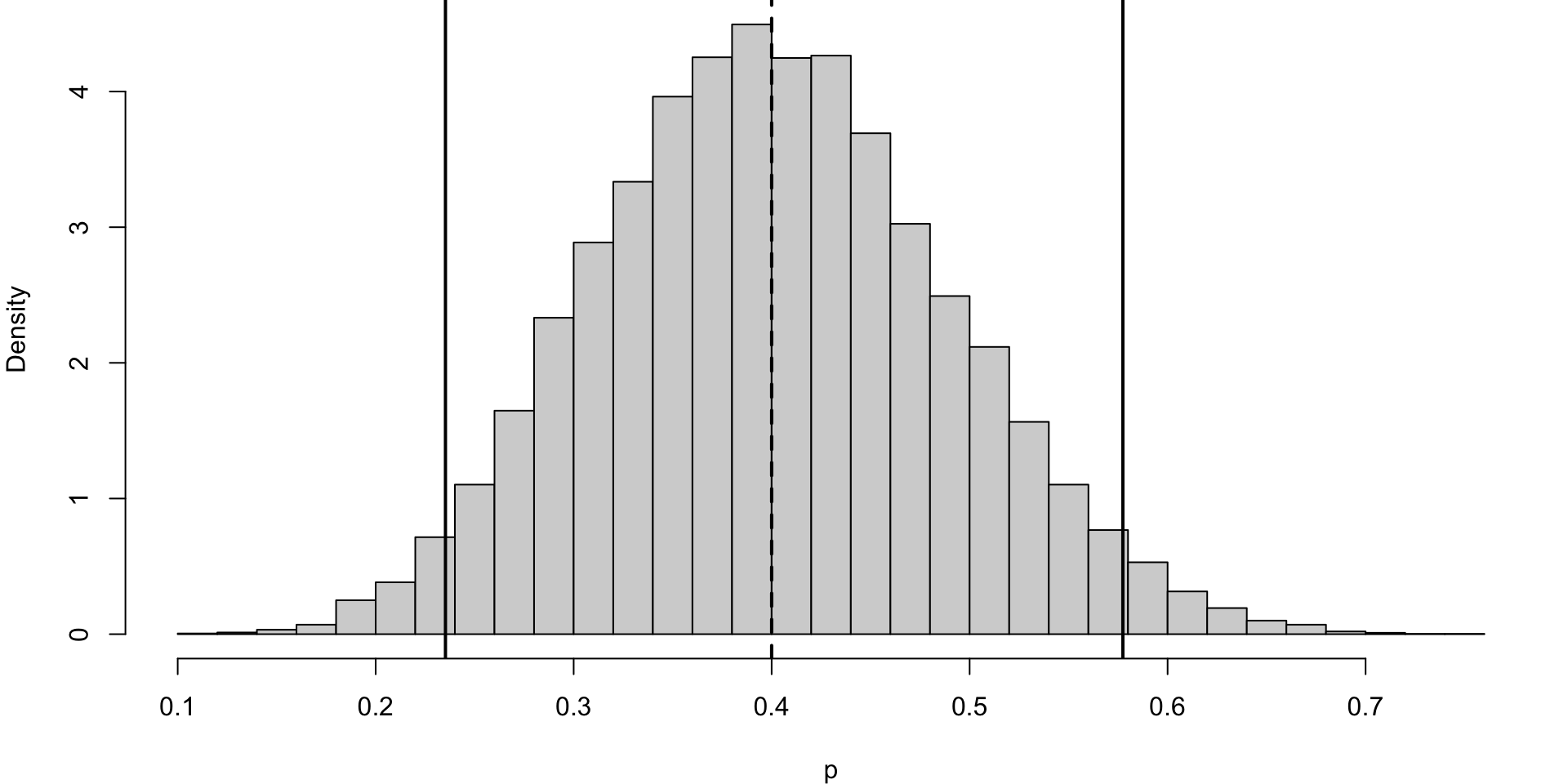
[1] 0.3056364[1] 0.397195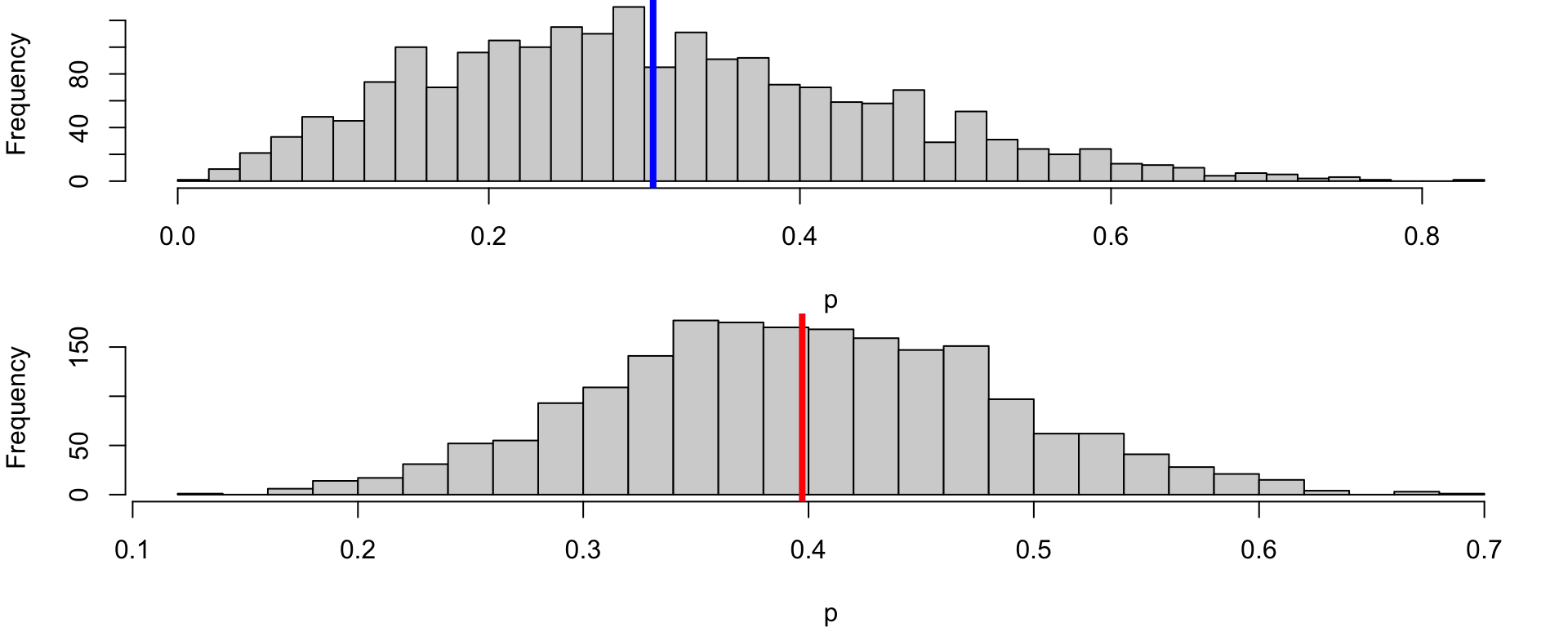
The posterior mean is 0.4, so our belief shifts from 30% to 40%.