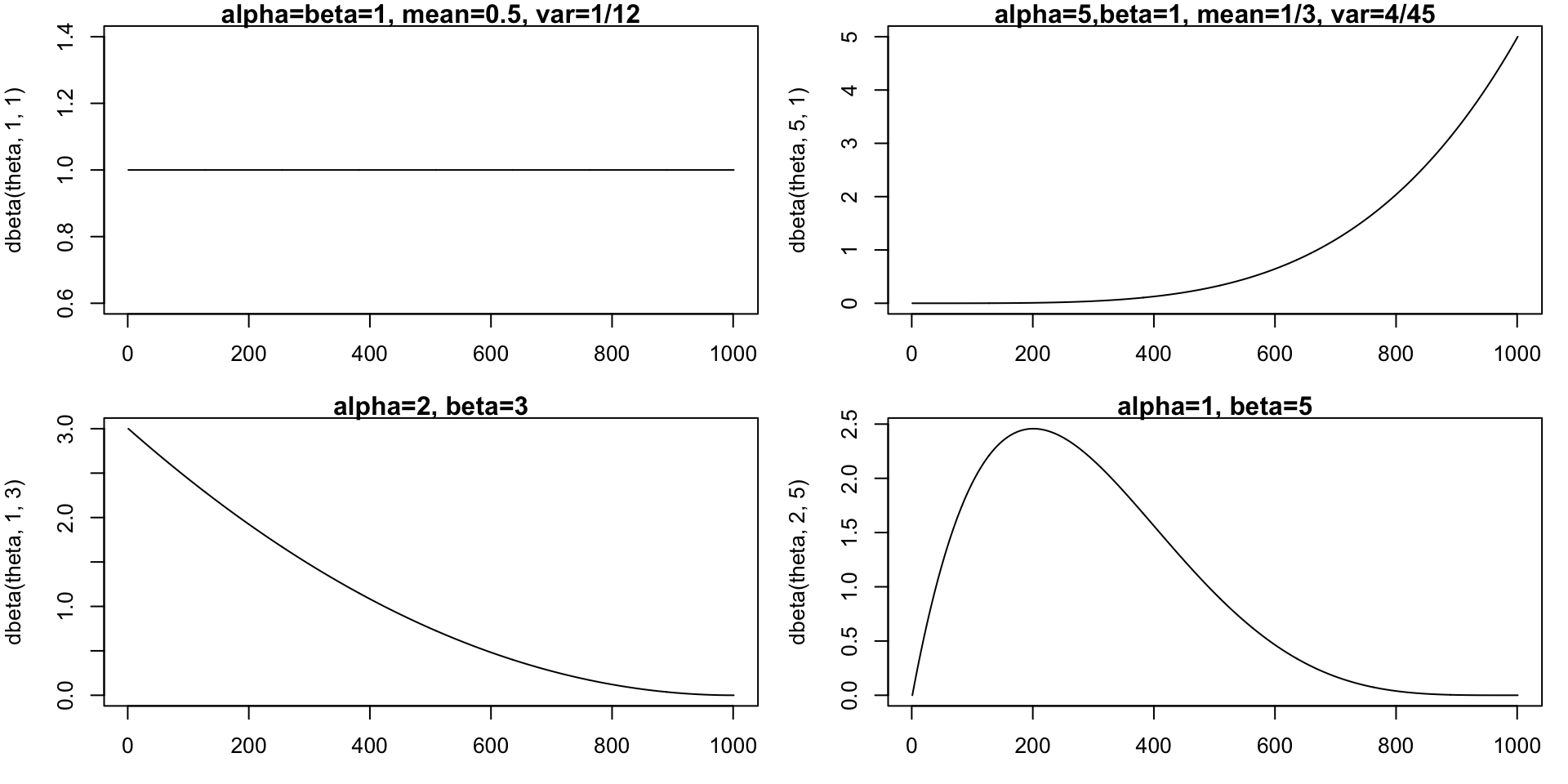
theta <- seq(0,1, by=0.001)
par(mfrow=c(2,2), mar=c(3,4,1,1))
plot(dbeta(theta, 1, 1),type="l", main="alpha=beta=1, mean=0.5, var=1/12")
plot(dbeta(theta, 5, 1),type="l", main="alpha=5,beta=1, mean=1/3, var=4/45")
plot(dbeta(theta, 1, 3),type="l",main="alpha=2, beta=3")
plot(dbeta(theta, 2, 5),type="l",main="alpha=1, beta=5")STAT2005 Computer Simulation
Lecture 4 — Simulation of Discrete Random Variables
12 Mar 2026
Beta Distributions
Non-informative (Flat) Priors
- Non-informative priors aim to have minimal influence on the posterior relative to the likelihood.
- They attempt to represent prior ignorance or neutrality about the parameter.
- Uniform or flat prior, where all parameter values equally likely: \(p \sim \text{Uniform(0,1)}.\)
🏀 Example: Basketball with Uniform or flat prior
- Suppose we know nothing about the player or what his shooting percentage might be.
- A simple choice is a uniform prior, where every value of \(p\) between 0 and 1 is considered equally likely.
Code
p <- seq(0, 1, length = 100)
prior <- rep(1, length(p))
likelihood <- dbinom(39, 60, p)
norm <- sum(prior * likelihood) # normalising constant
posterior <- prior * likelihood / norm
par(mfrow = c(3,1),
mar = c(0,4,1,1), # remove bottom margin
oma = c(4,0,0,0)) # outer margin for shared x-label
plot(p, prior, type="l", xaxt="n", ylab="Prior", col="green")
plot(p, likelihood, type="l", xaxt="n", ylab="Likelihood", col="blue")
plot(p, posterior, type="l", ylab="Posterior", xlab="p", col="red")
mtext("Free throw success probability (p)", side=1, outer=TRUE, line=3)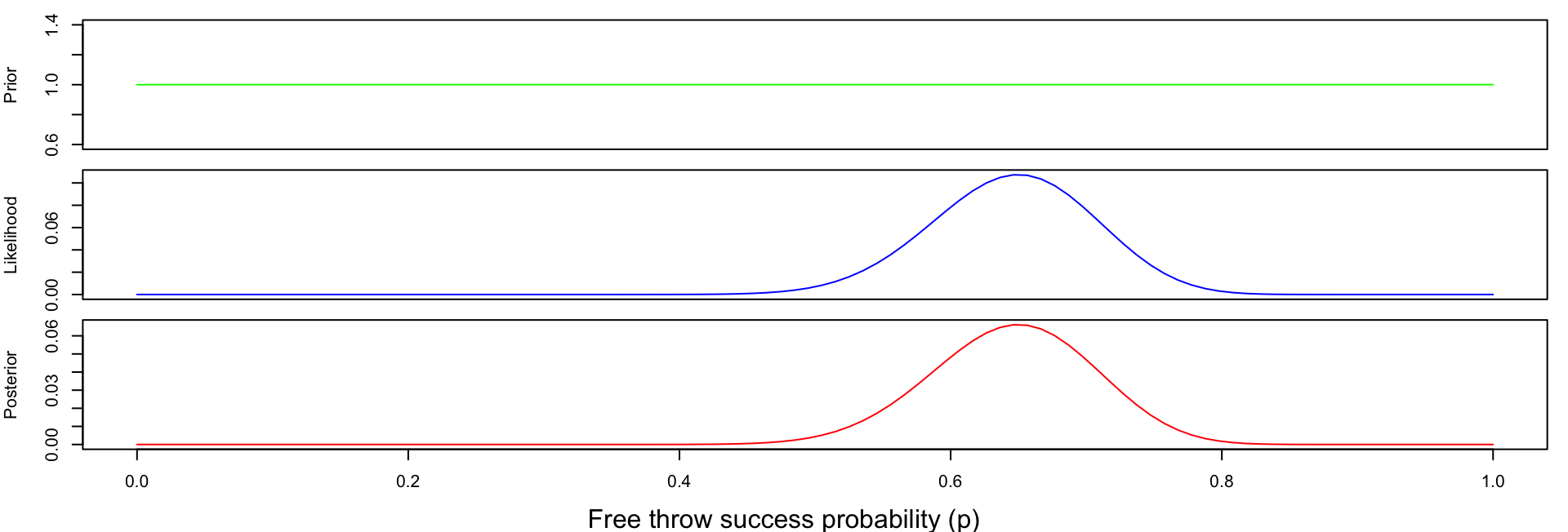
Informative Priors
- In many situations we have prior knowledge or expert beliefs about the parameter \(p.\)
🏀 Example: Basketball with Informative Prior
- Professional players typically make between 50% and 95% of their free throws.
- Based on a basketball expert’s knowledge, we have the following discrete prior.
| Free Throw Probability (p) | 0.50 | 0.55 | 0.60 | 0.65 | 0.70 | 0.75 | 0.80 | 0.85 | 0.90 | 0.95 |
|---|---|---|---|---|---|---|---|---|---|---|
| Prior Probability | 0.005 | 0.01 | 0.05 | 0.10 | 0.22 | 0.33 | 0.22 | 0.05 | 0.014 | 0.001 |
Code
p <- seq(0.5, 0.95, length = 10)
prior <- c(0.005, 0.01, 0.05, 0.1, 0.22, 0.33, 0.22, 0.05, 0.014, 0.001) # given by an expert
likelihood <- dbinom(39, 60, p)
norm <- sum(prior * likelihood) # normalising constant from the law of total probability
posterior <- prior * likelihood / norm
# Prior summaries
prior_mode <- p[which.max(prior)]
prior_mean <- sum(p * prior)
# Posterior summaries
posterior_mode <- p[which.max(posterior)] # MAP estimate on this grid
posterior_mean <- sum(p * posterior)
# 98% equal-tail credible interval on the discrete grid
post_cdf <- cumsum(posterior)
lower_98 <- p[min(which(post_cdf >= 0.01))]
upper_98 <- p[min(which(post_cdf >= 0.99))]
# Plot
par(mfrow = c(3,1),
mar = c(0,4,1,1), # remove bottom margin
oma = c(4,0,0,0)) # outer margin for shared x-label
plot(p, prior, type="l", xaxt="n", ylab="Prior", col="green")
abline(v = prior_mode, lty = 2, col = "darkgreen")
plot(p, likelihood, type="l", xaxt="n", ylab="Likelihood", col="blue")
plot(p, posterior, type="l", ylab="Posterior", xlab="p", col="red")
abline(v = posterior_mode, lty = 2, col = "darkred")
abline(v = c(lower_98, upper_98), lty = 3, col = "gray40")
mtext("Free throw success probability (p)", side=1, outer=TRUE, line=3)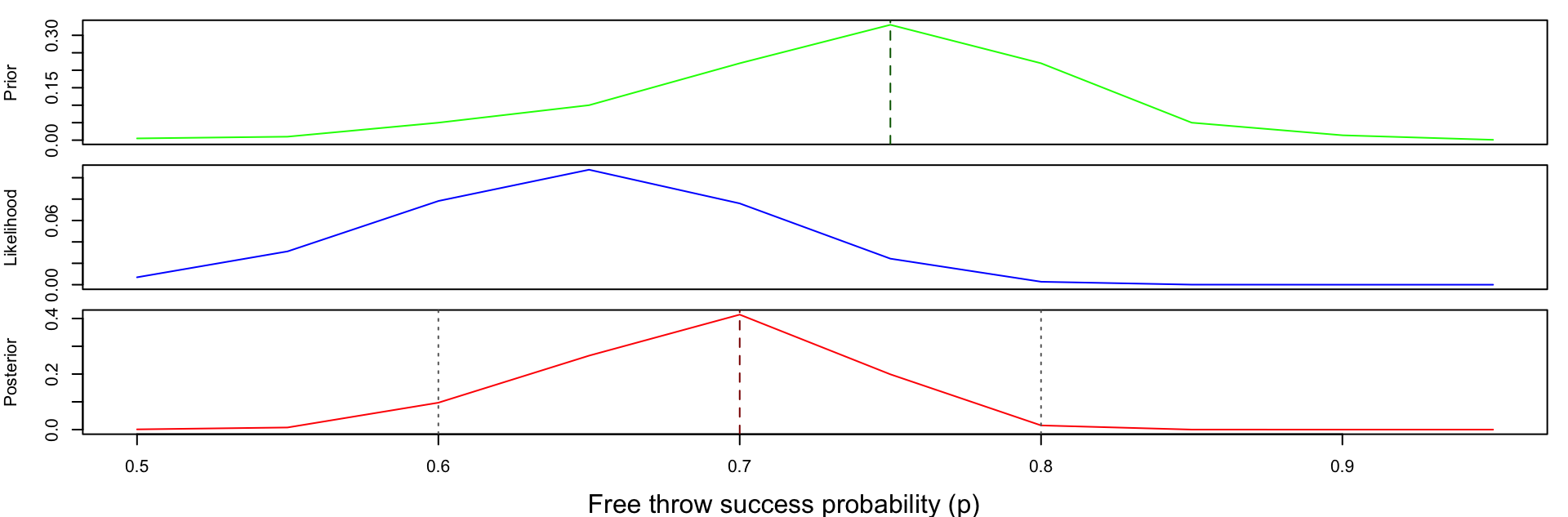
curve(dbeta(x, alpha_post, beta_post), from = 0, to = 1, col = "red", lwd = 2)
curve(dbeta(x, alpha, beta), from = 0, to = 1,
col = "darkgreen", lwd = 2, ylab = "Density", xlab = "p",
main = "Beta-Binomial Basketball Example", add = TRUE)
abline(v = x / n, col = "blue", lty = 2, lwd = 2)
legend("topright",
legend = c("Prior Beta(15,5)", "Posterior Beta(54,26)", "Sample Proportion = 39/60"),
col = c("darkgreen", "red", "blue"), lwd = c(2, 2, 2), lty = c(1, 1, 2))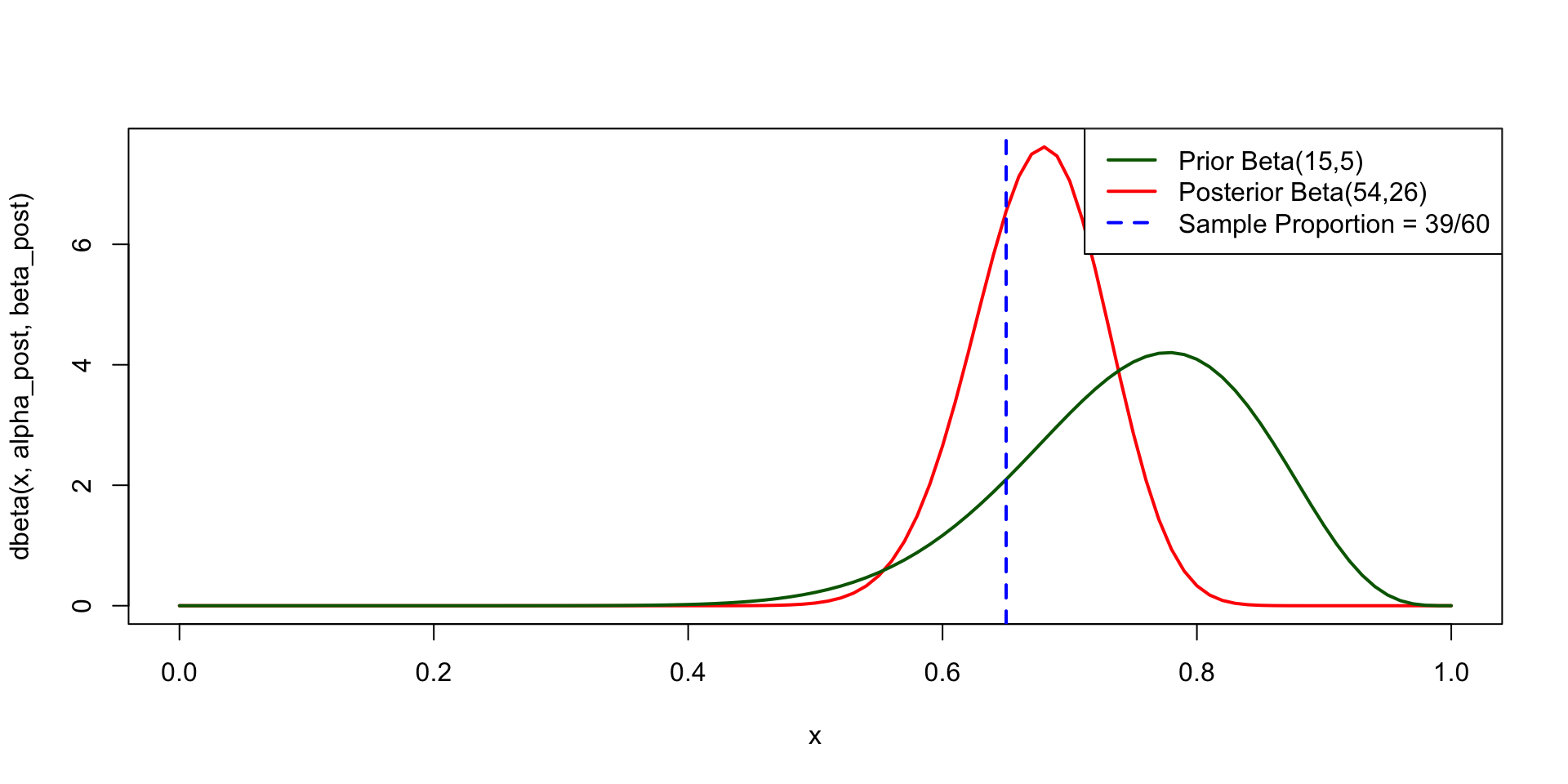
# Empirical check with a large simulation
set.seed(123)
samples <- r_arrivals(10000)
empirical <- table(samples) / 10000
barplot(rbind(p, empirical), names.arg = x,
beside = TRUE, col = c("skyblue", "orange"),
legend.text = c("True p(x)", "Empirical"),
main = "Simulated vs True Arrival Distribution")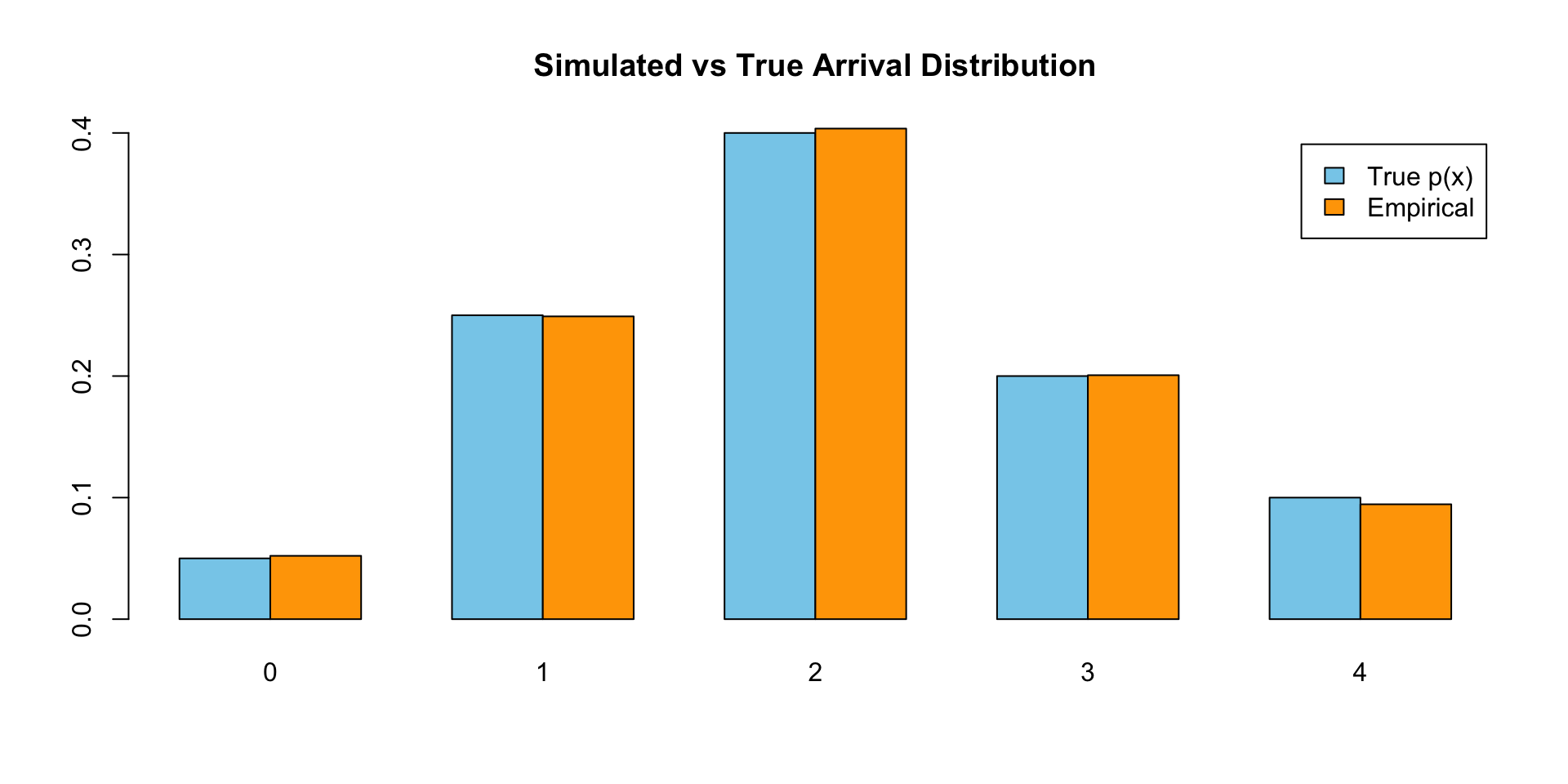
With 10,000 samples, the empirical distribution closely matches the target distribution—demonstrating that the discrete inverse CDF method works exactly as intended.
Plot \(S(t), I(t), R(t)\) for four separate simulations, with \(\alpha = 0.0005\) and \(\beta = 0.1, 0.2, 0.3,\) and \(0.4.\)
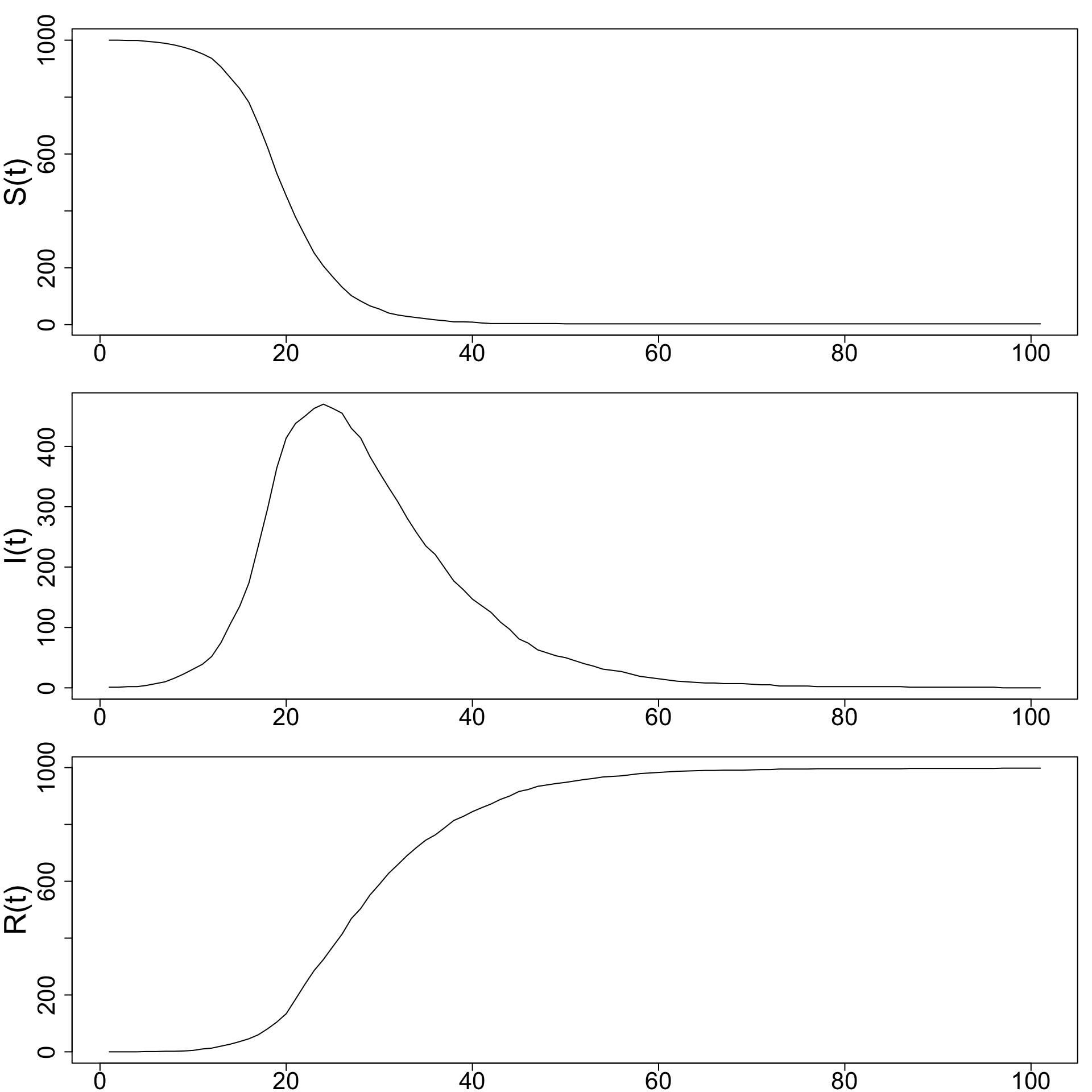
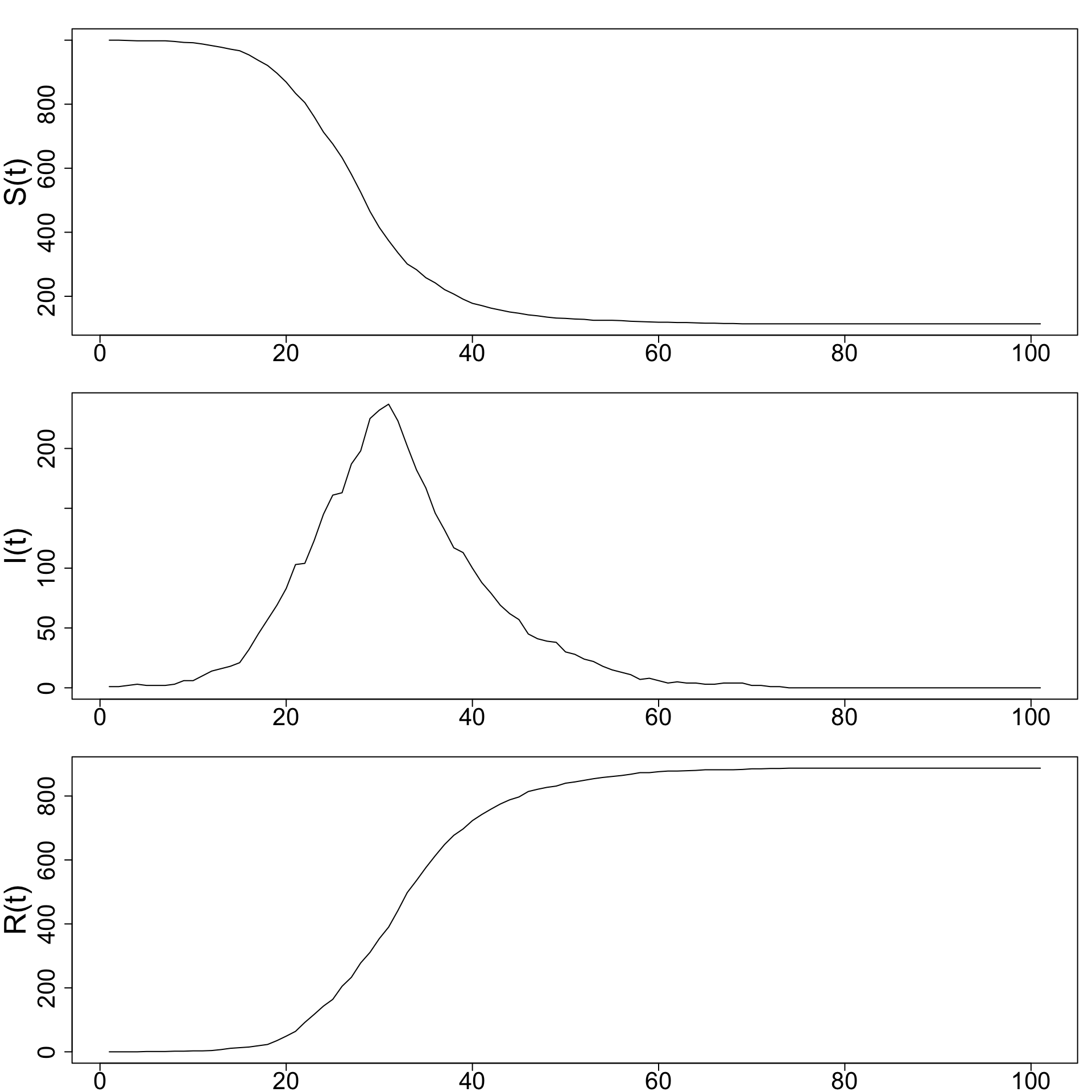
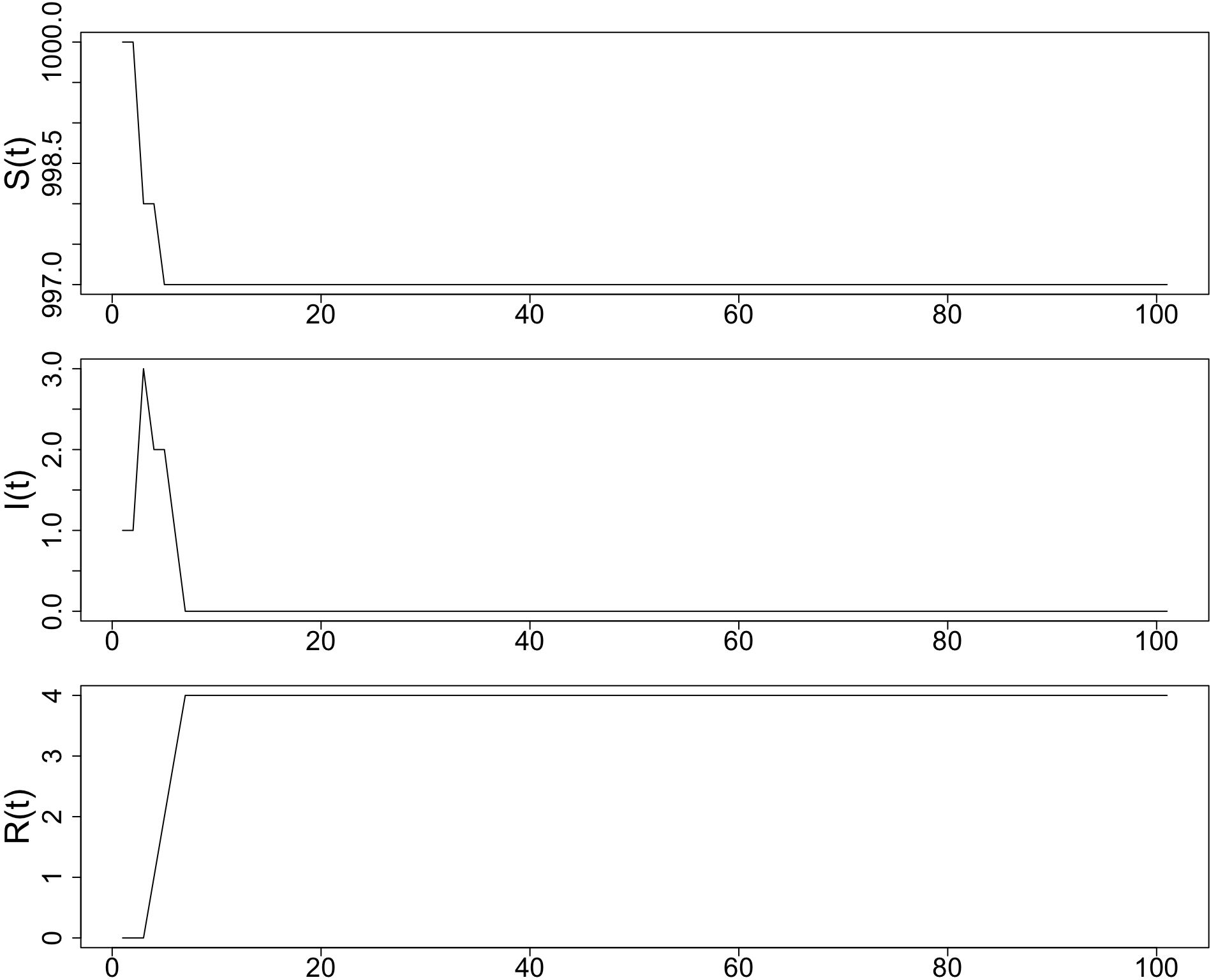
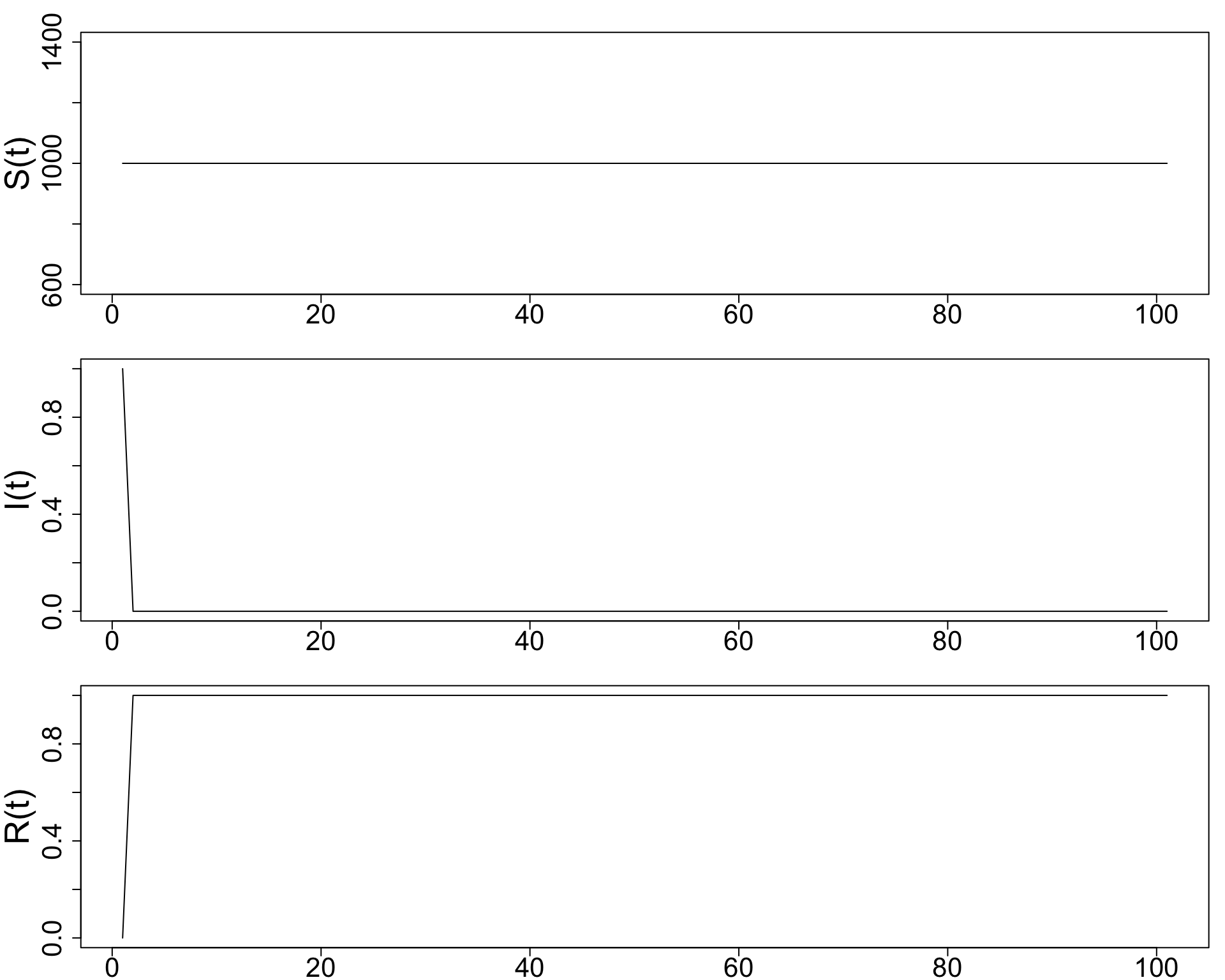
- As β increases, infected individuals recover faster.
- Faster recovery means less time spent infectious, so fewer secondary infections occur. Therefore:
- The peak of \(I(t)\) becomes lower.
- The epidemic ends sooner.
- The final number of susceptibles \(S(T)\) is higher.
- The epidemic size decreases.
The main aim is to estimate \(E[S(T)]\), average epidemic size, for different values of \(\alpha\) and \(\beta\) to see how it varies.
Code
SIR <- function(a, b, N, T) {
# simulates SIR epidemic model from time 0 to T
# returns number of susceptibles, infected and removed at time T
S <- N
I <- 1
R <- 0
for (i in 1:T) {
S <- rbinom(1, S, (1 - a)^I)
R <- R + rbinom(1, I, b)
I <- N + 1 - S - R
}
return(c(S, I, R))
}
# set parameter values
N <- 1000
T <- 100
a <- seq(0.0001, 0.001, by = 0.0001)
b <- seq(0.1, 0.5, by = 0.05)
n.reps <- 400 # sample size for estimating E S[T]
f.name <- "SIR_grid.dat" # file to save simulation results
# estimate E S[T] for each combination of a and b
write(c("a", "b", "S_T"), file = f.name, ncolumns = 3)
for (i in 1:length(a)) {
for (j in 1:length(b)) {
S.sum <- 0
for (k in 1:n.reps) {
S.sum <- S.sum + SIR(a[i], b[j], N, T)[1]
}
write(c(a[i], b[j], S.sum/n.reps), file = f.name,
ncolumns = 3, append = TRUE)
}
}
# plot estimates in 3D
g <- read.table(f.name, header = TRUE)
library(lattice)
print(wireframe(S_T ~ a*b, data = g, scales = list(arrows = FALSE),
aspect = c(.5, 1), drape = TRUE,
xlab = "a", ylab = "b", zlab = "E S[T]"))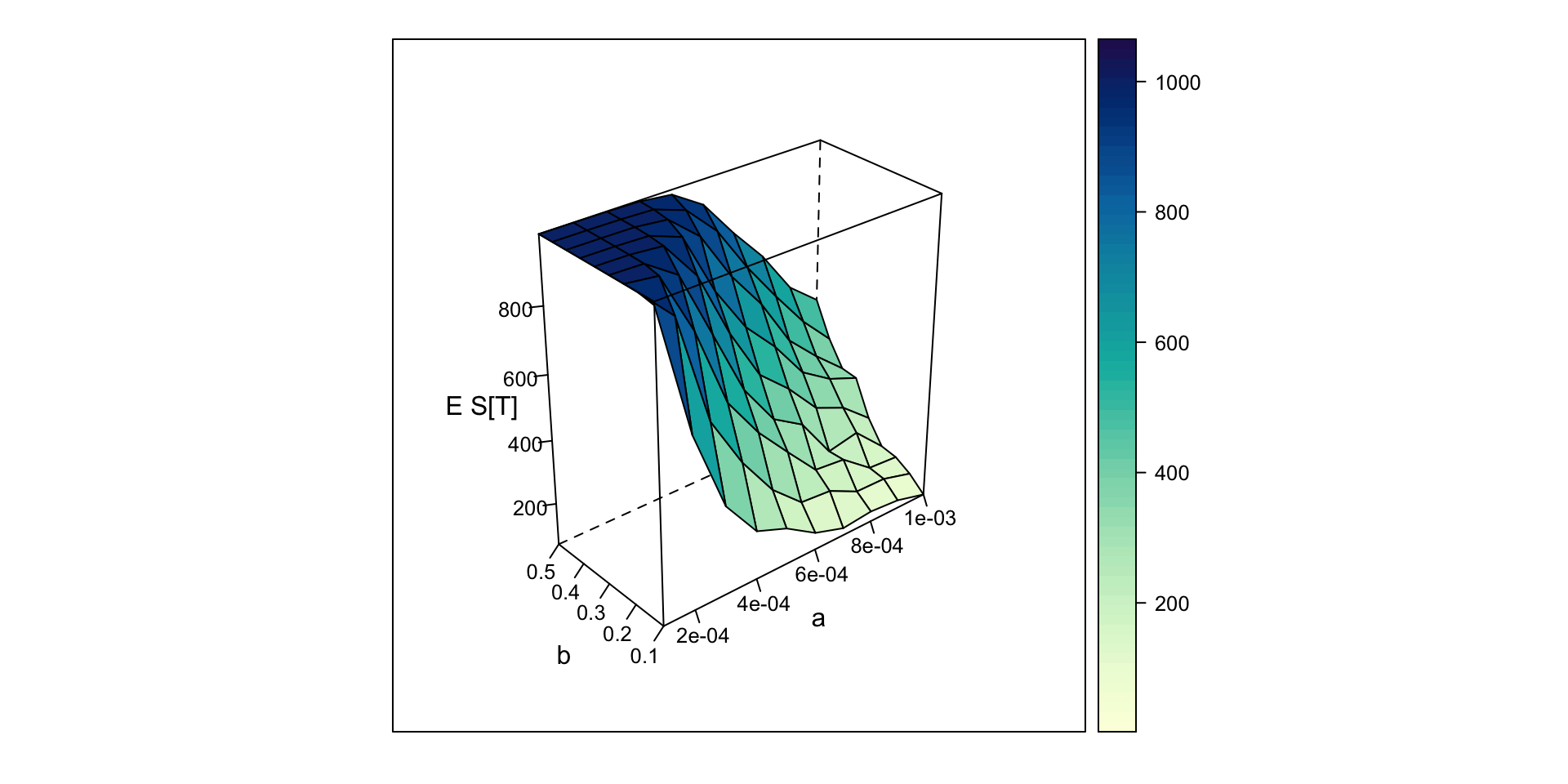
The 3D plot shows how the expected epidemic size depends jointly on infection probability and recovery probability: epidemics grow larger when α is high and β is low, and shrink when α is low and β is high.