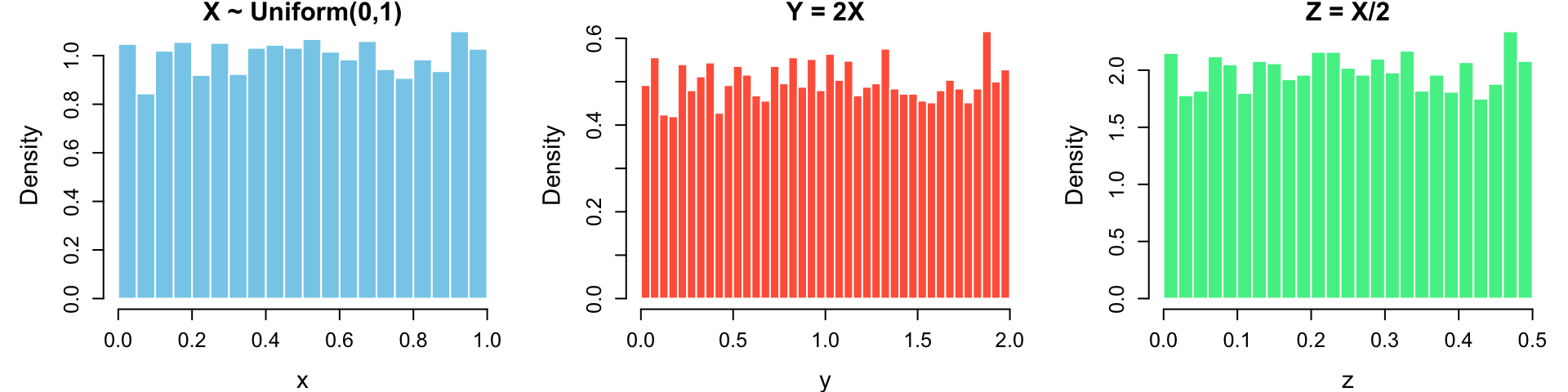
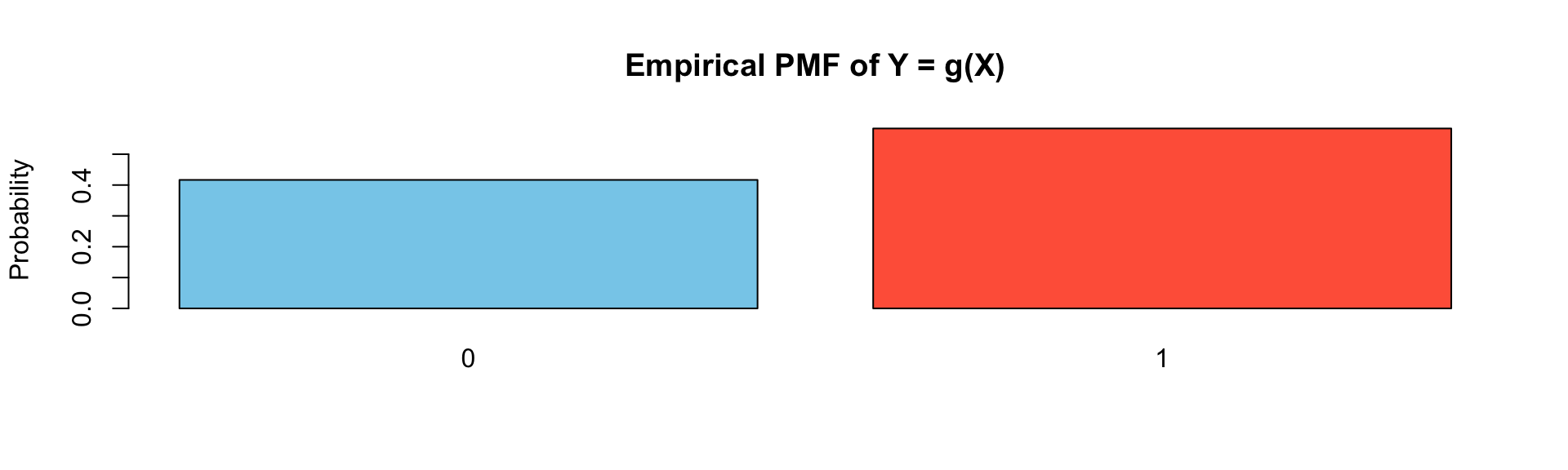
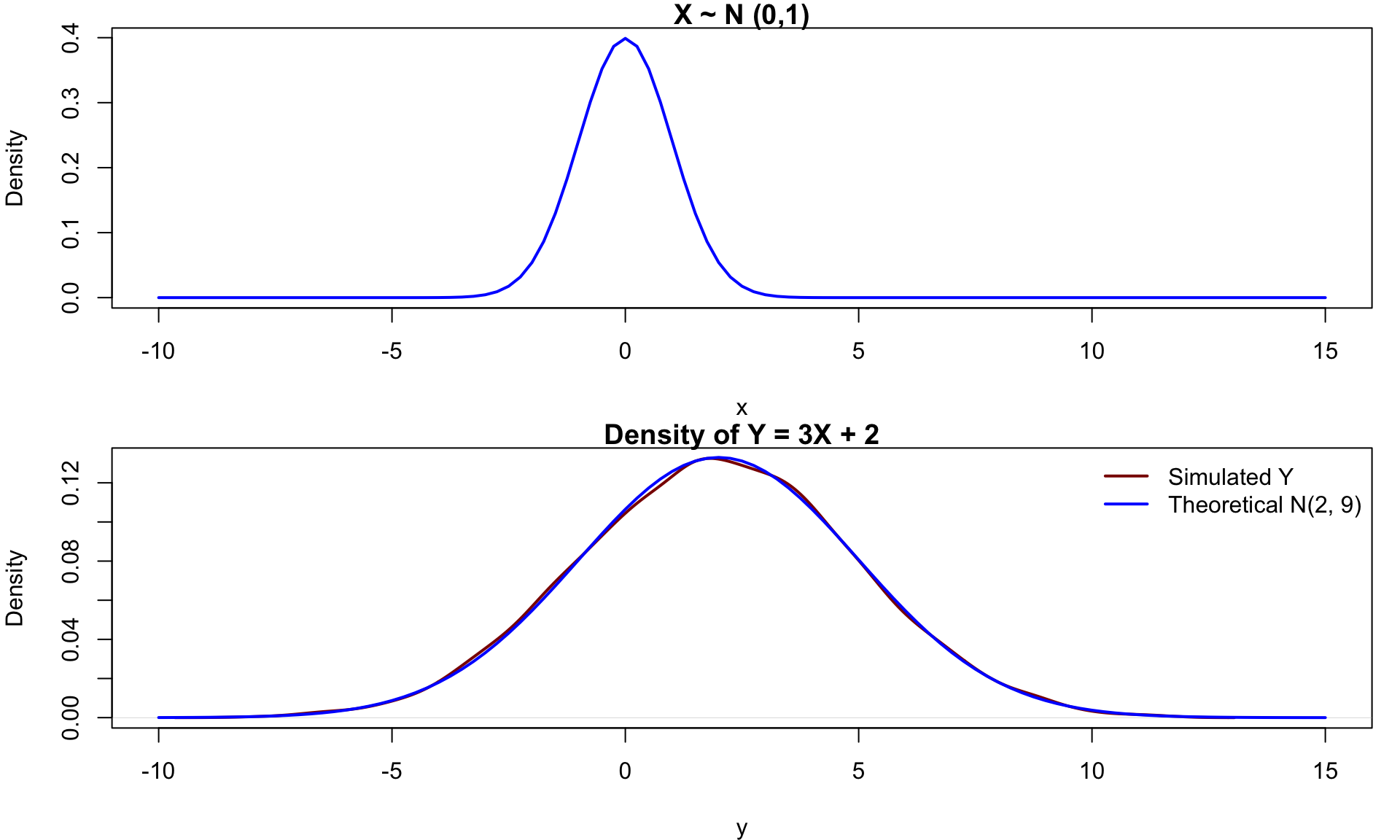
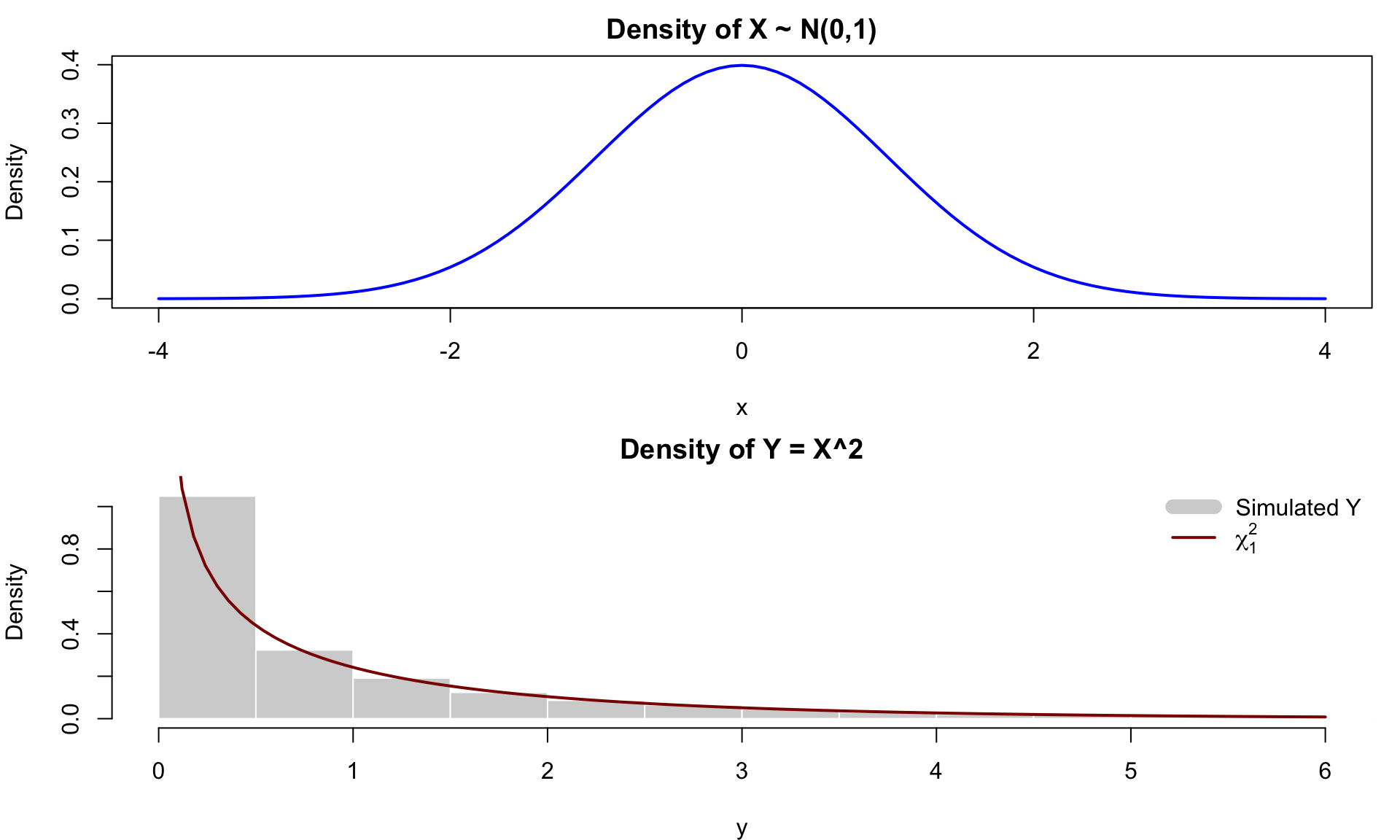
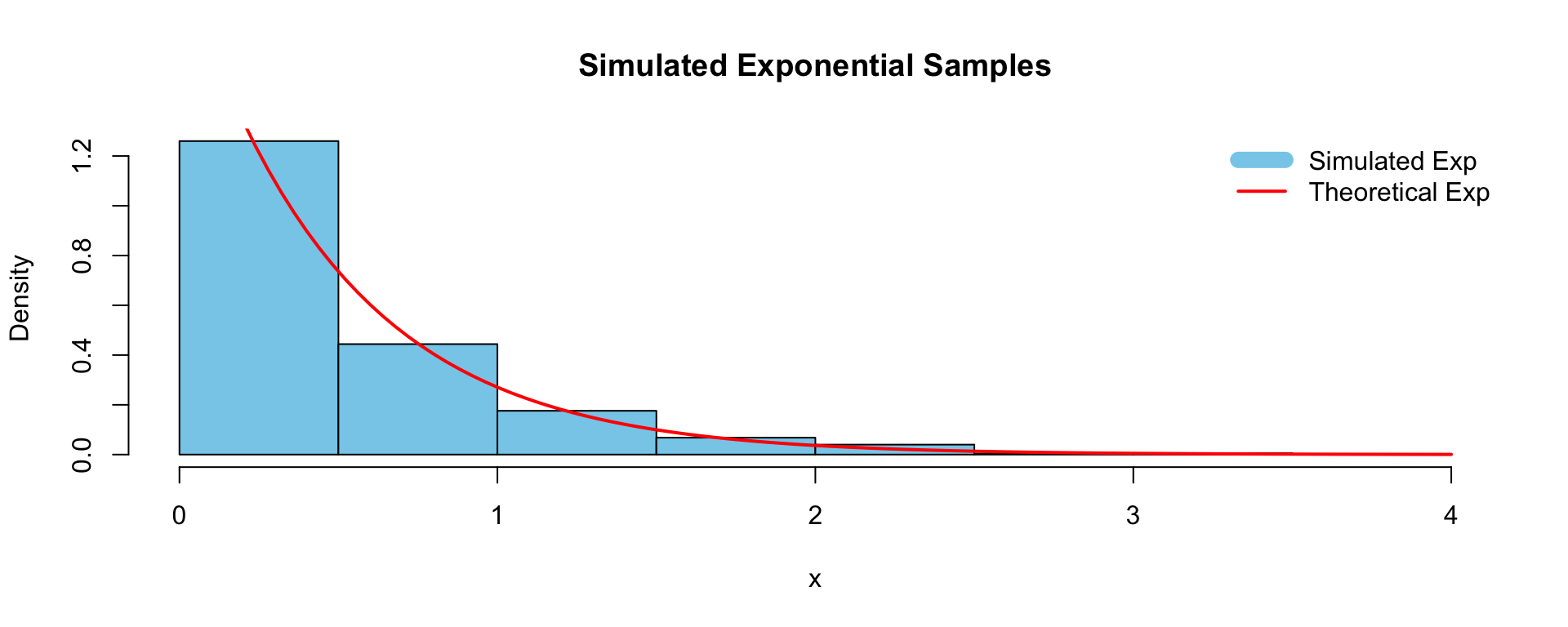
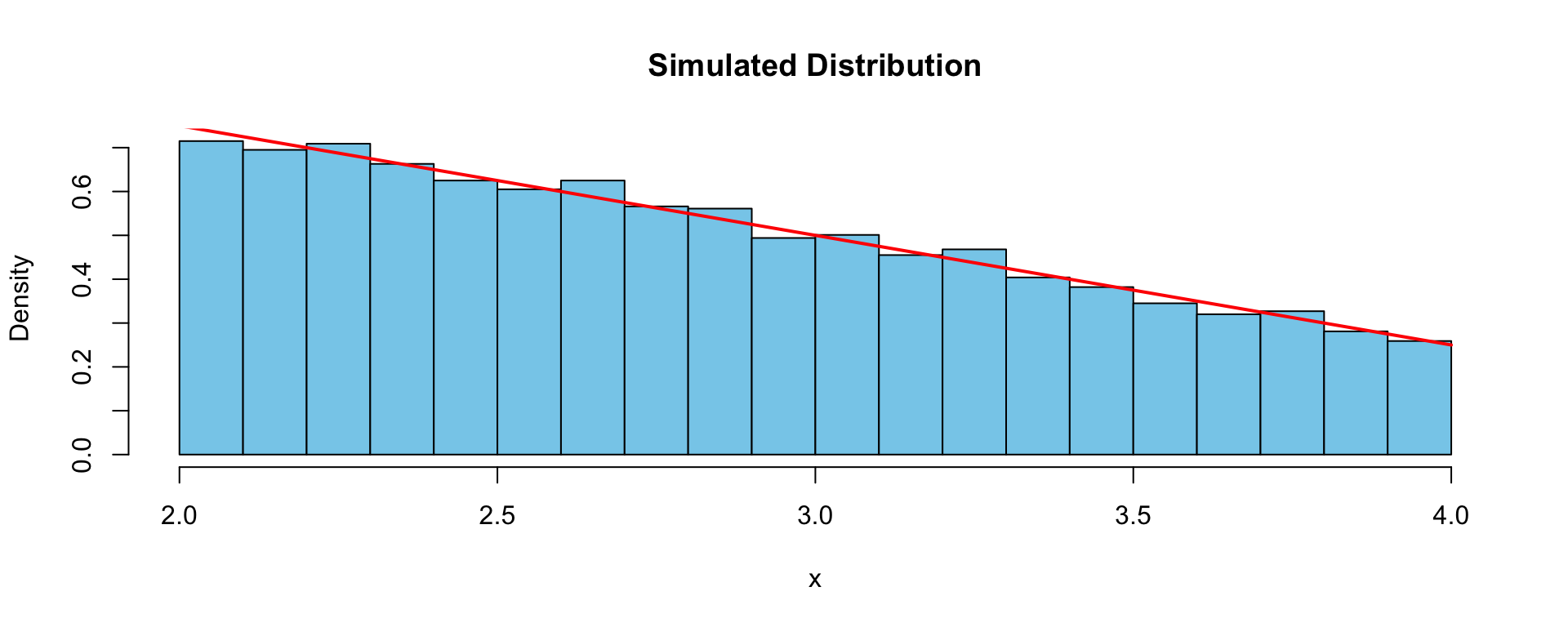
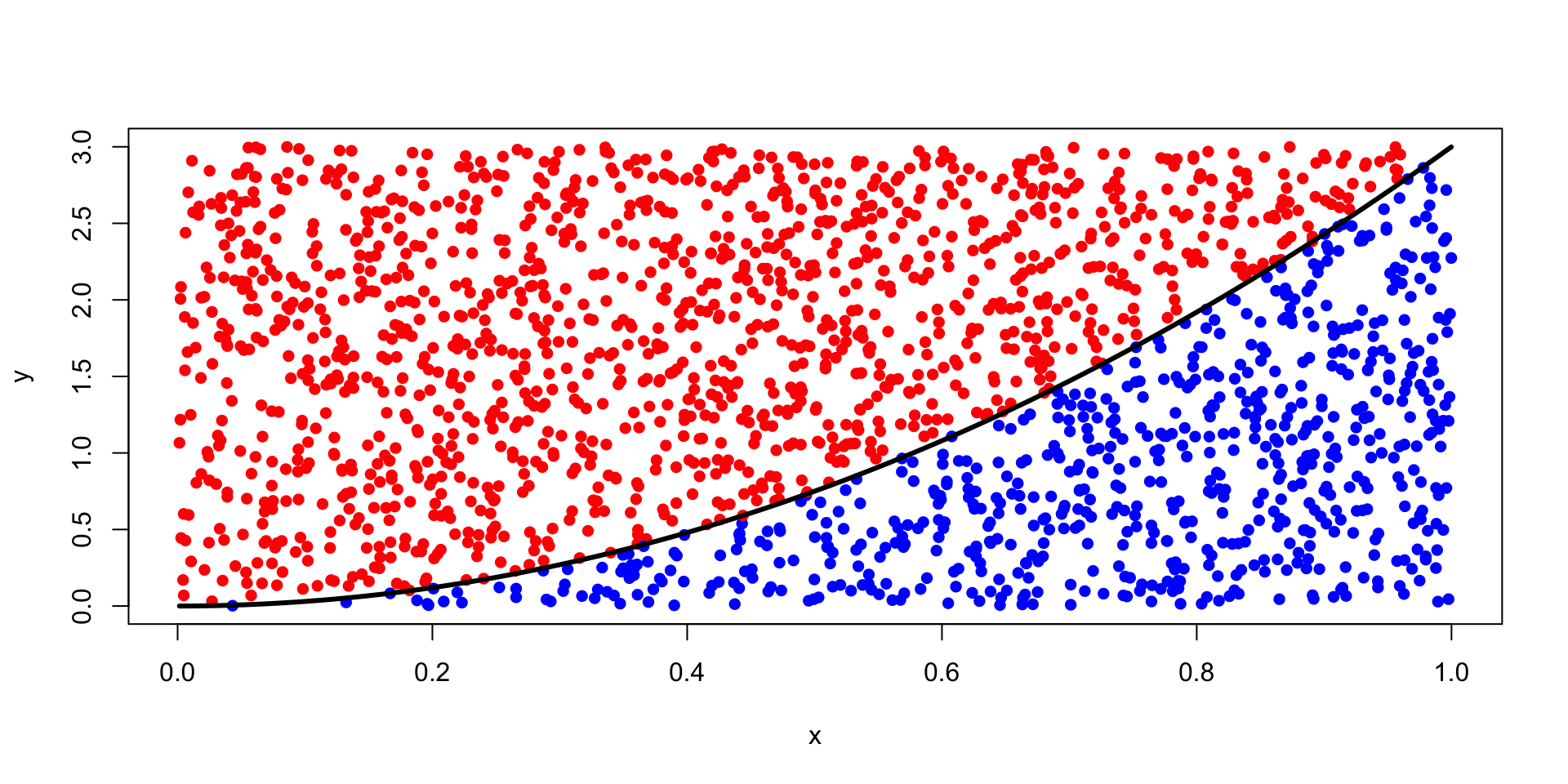
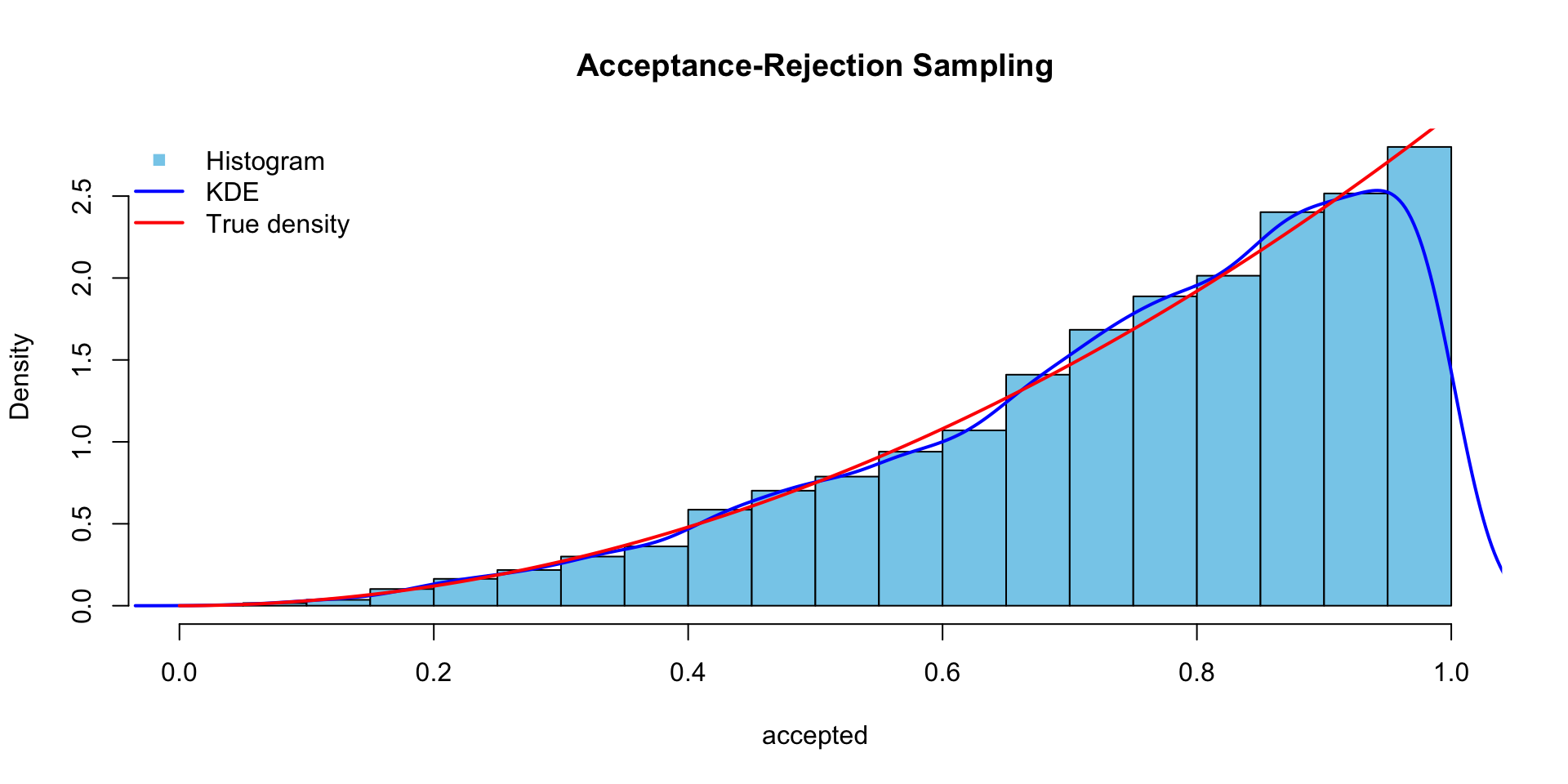
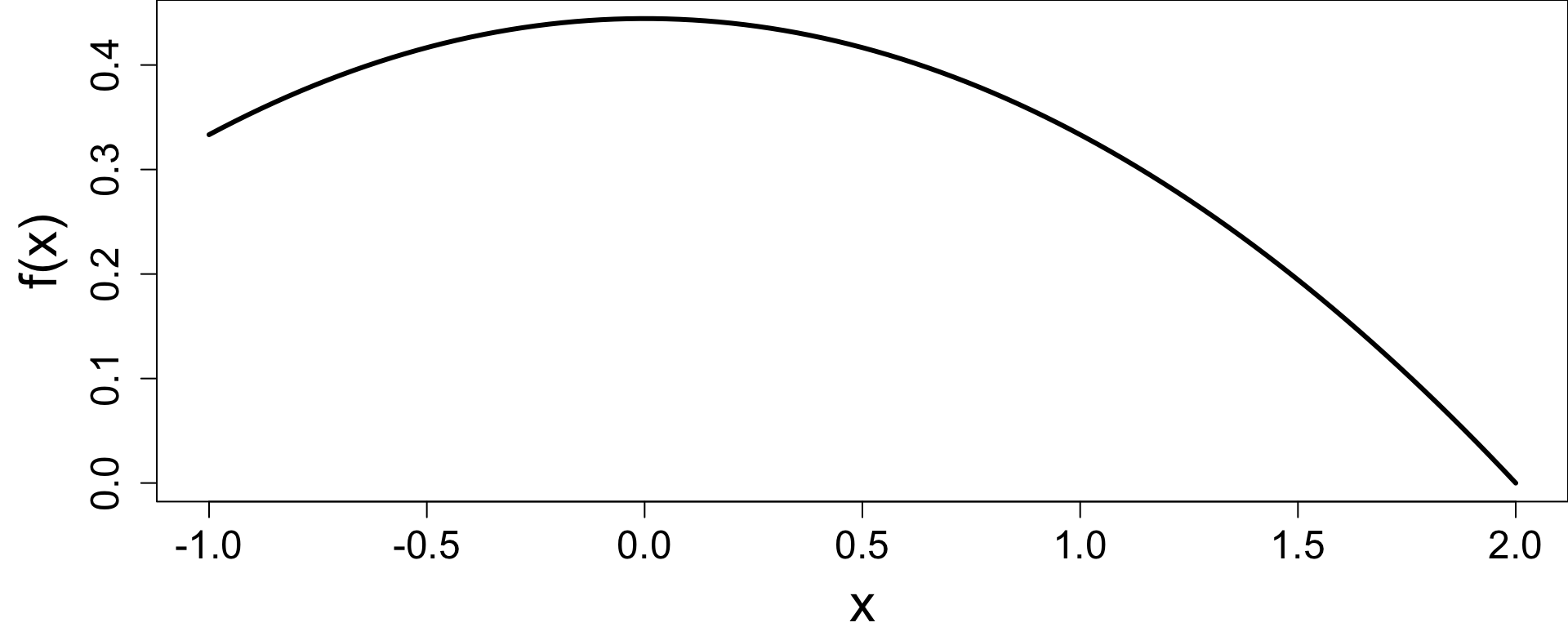
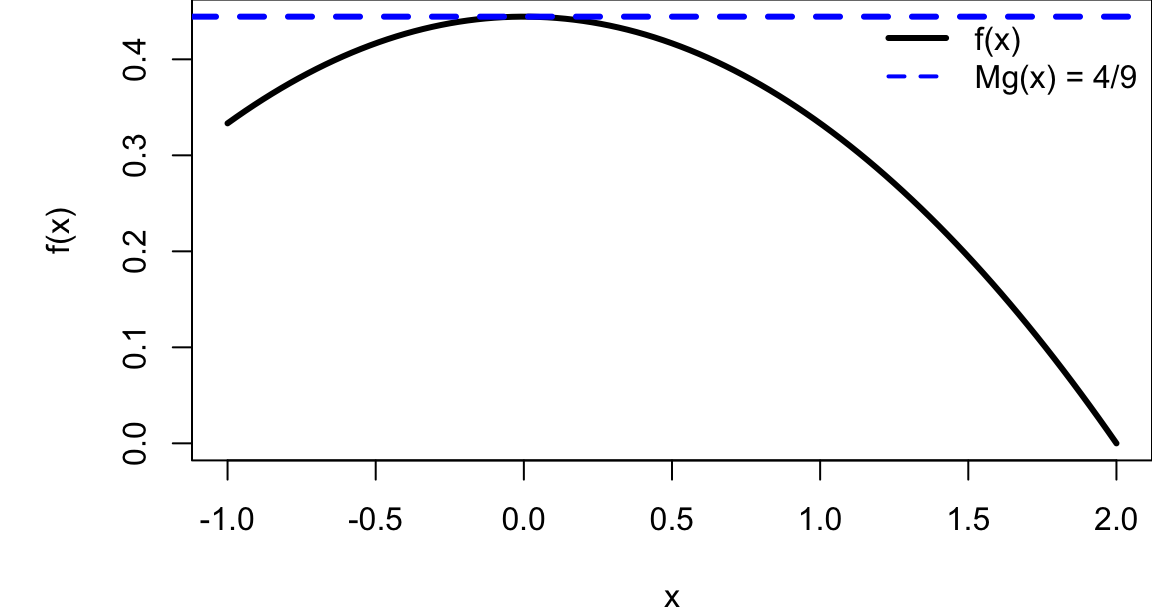
set.seed(1234)
# Original variable
X <- rnorm(5000)
# Transformation
Y <- X^2
op <- par(mfrow = c(2,1), mar = c(4,4,2,1))
# Panel 1: X ~ N(0,1)
curve(dnorm(x, mean = 0, sd = 1),
from = -4, to = 4,
col = "blue", lwd = 2,
xlab = "x", ylab = "Density",
main = "Density of X ~ N(0,1)")
# Panel 2: Y = X^2
hist(Y, breaks = 40, freq = FALSE,
col = "lightgray", border = "white",
xlim = c(0, 6), ylim = c(0, 1.1),
main = "Density of Y = X^2",
xlab = "y", ylab = "Density")
curve(dchisq(x, df = 1),
from = 1e-4, to = 6,
col = "darkred", lwd = 2, add = TRUE)
legend("topright",
legend = c("Simulated Y", expression(chi[1]^2)),
col = c("lightgray", "darkred"),
lwd = c(10, 2), bty = "n")