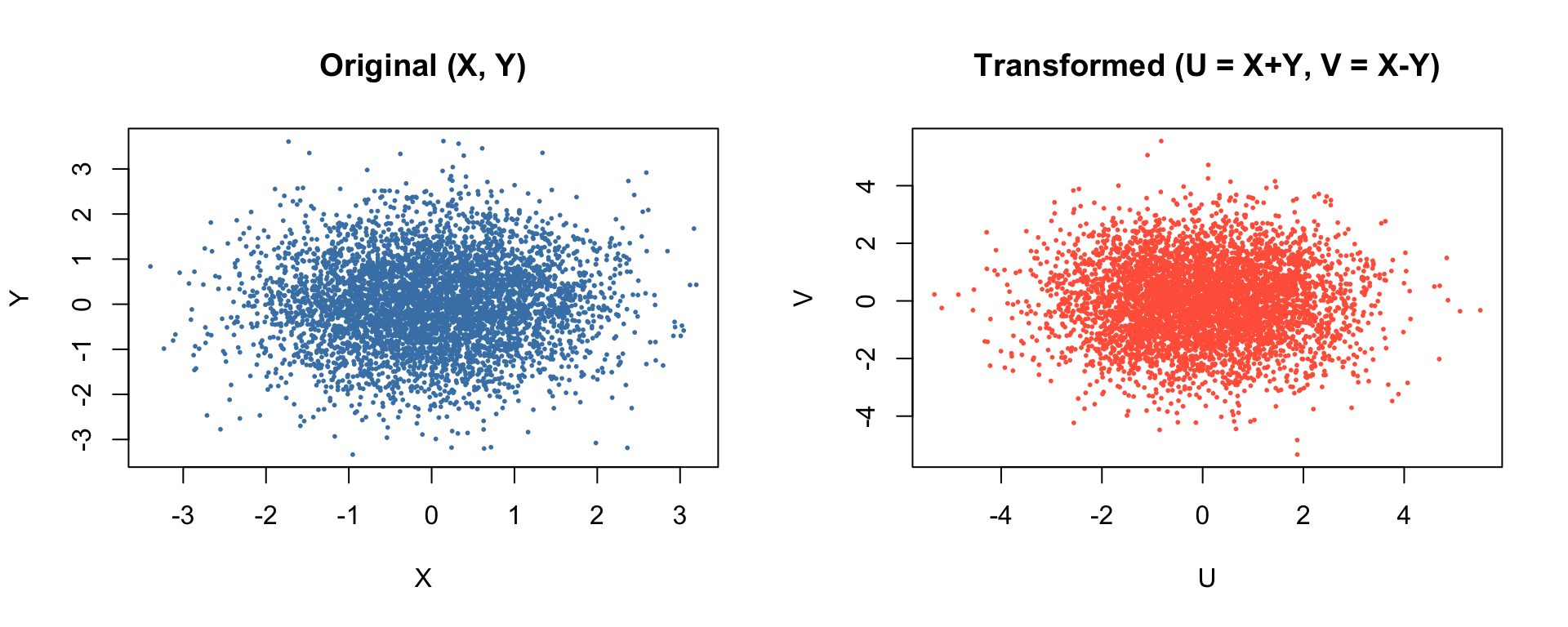
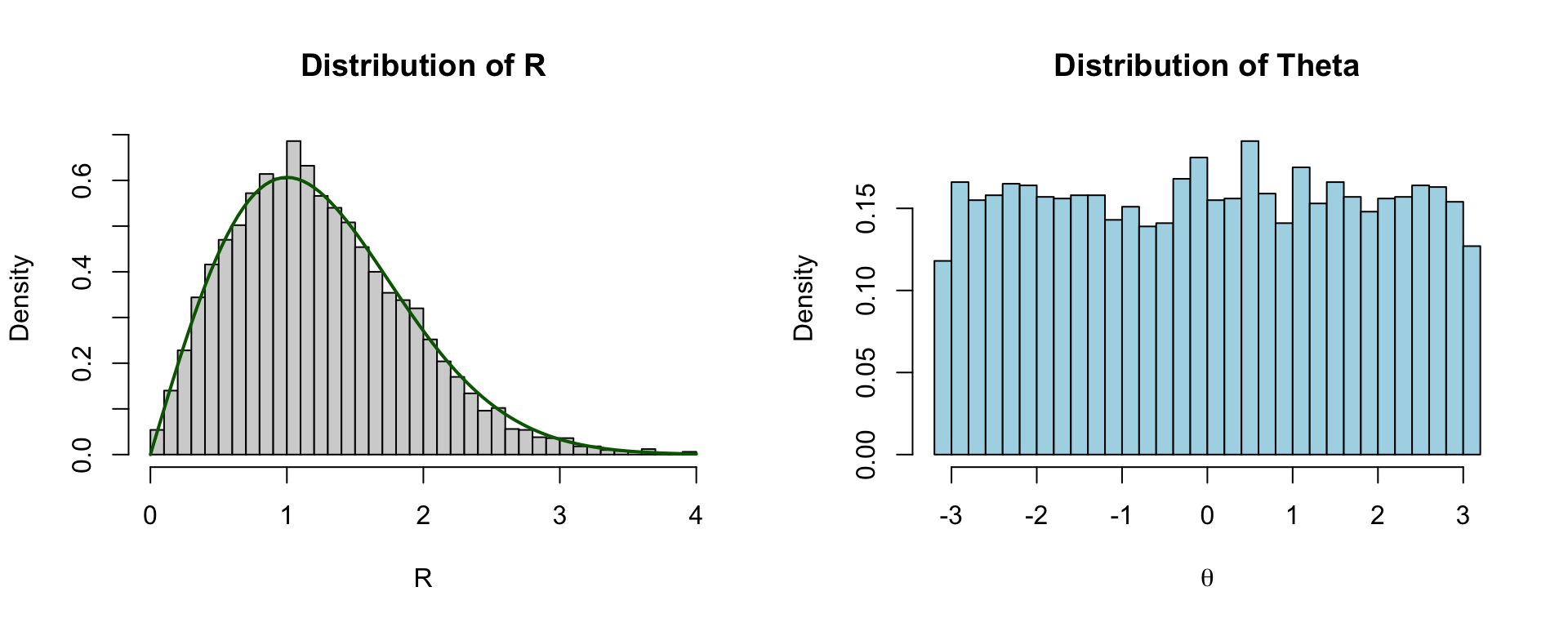
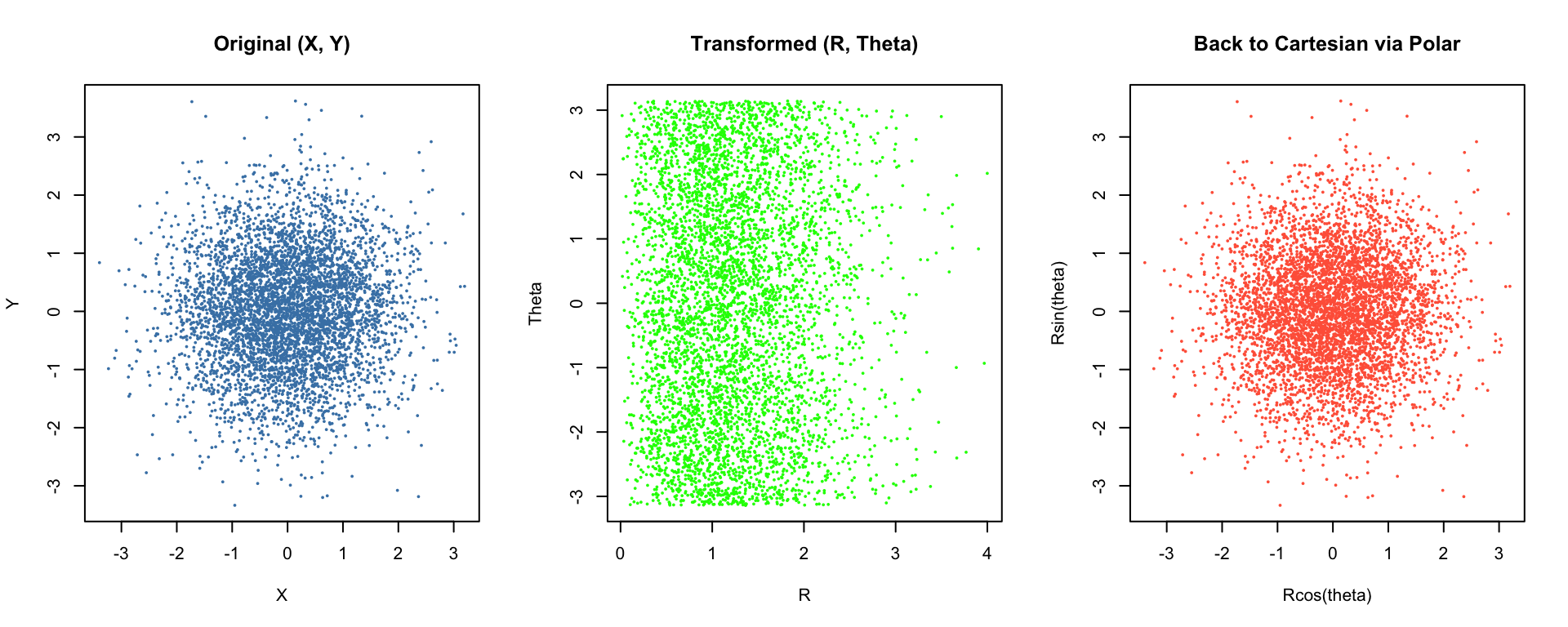
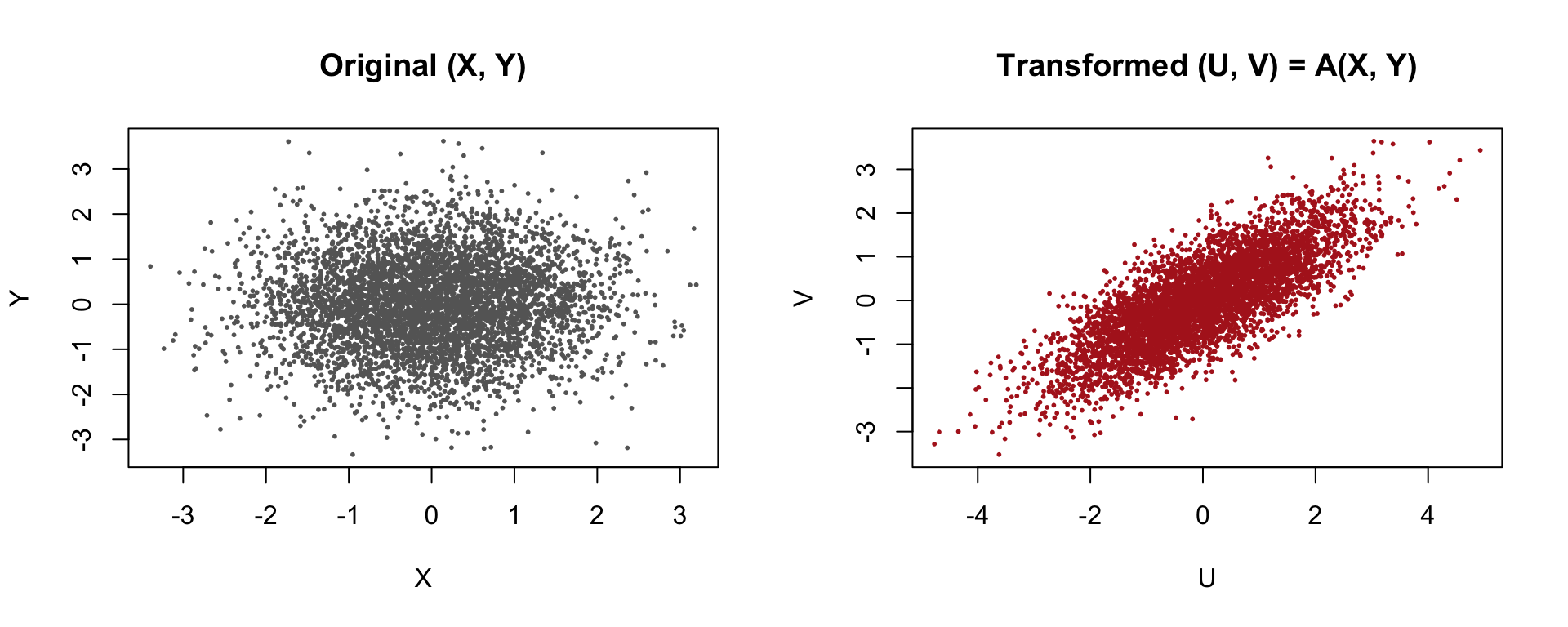
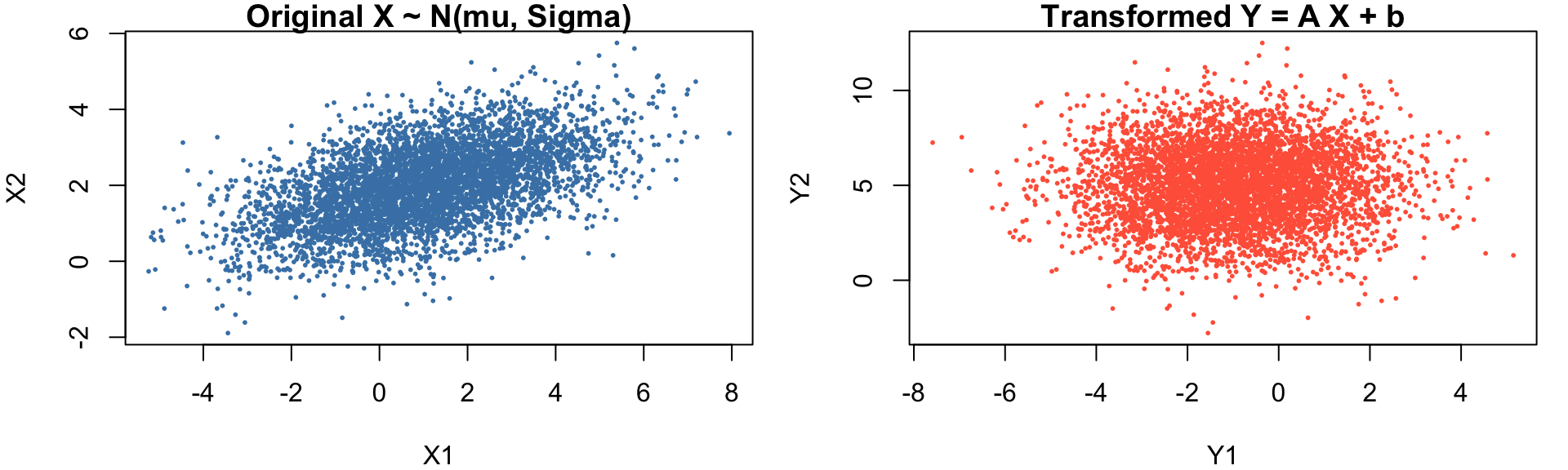
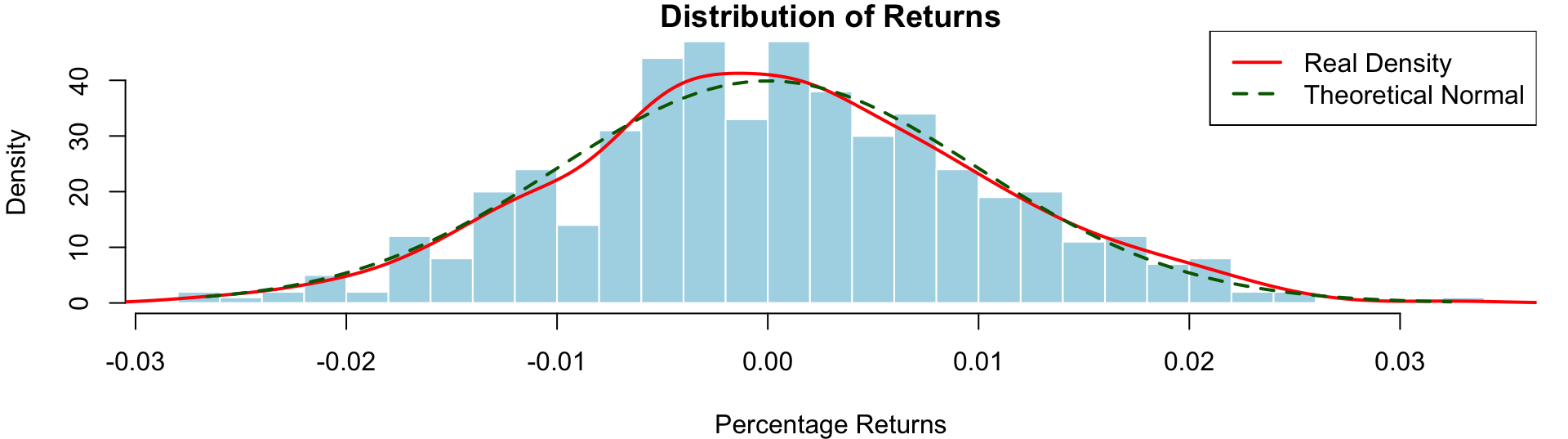
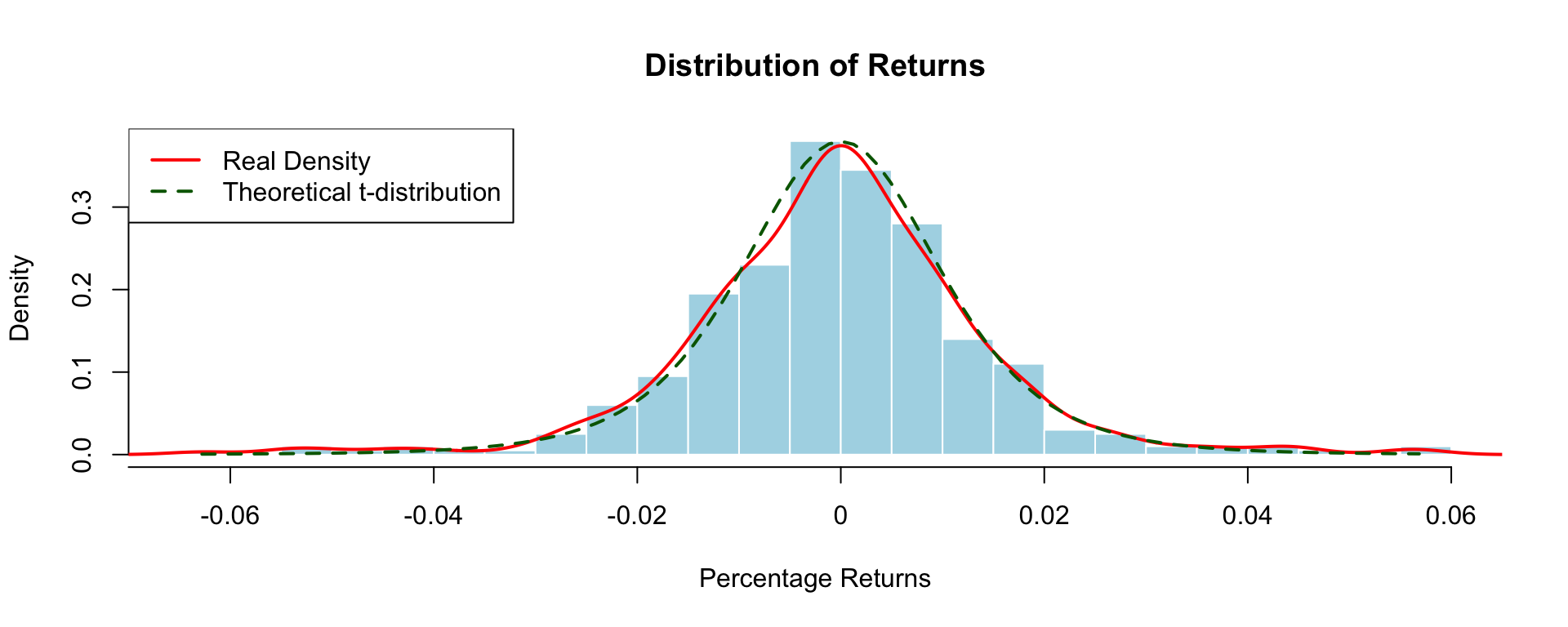
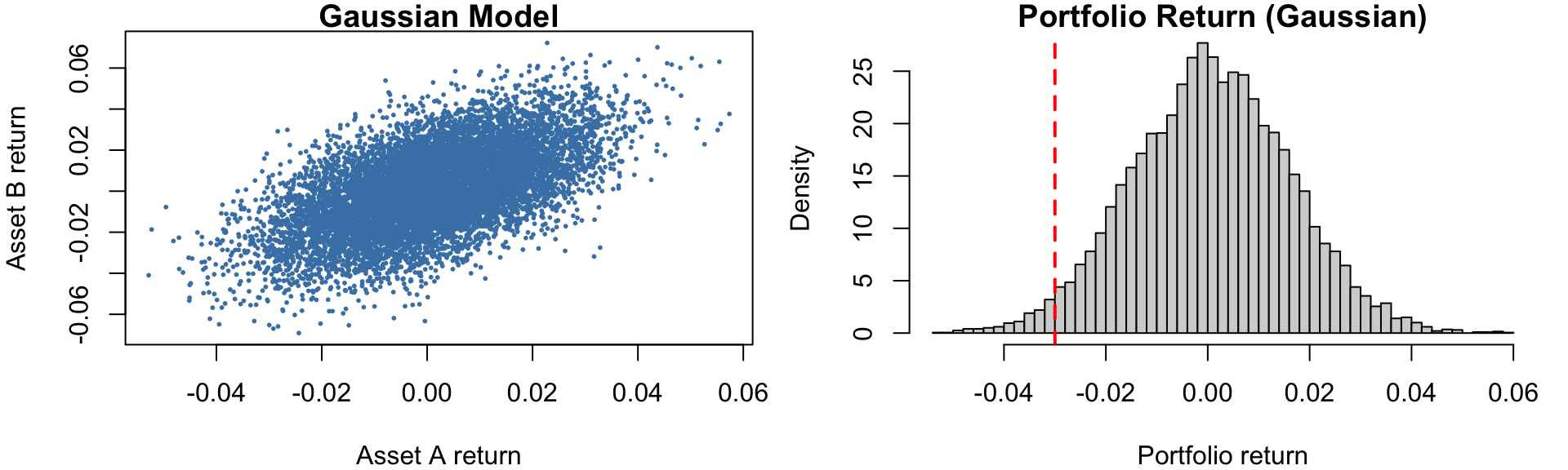
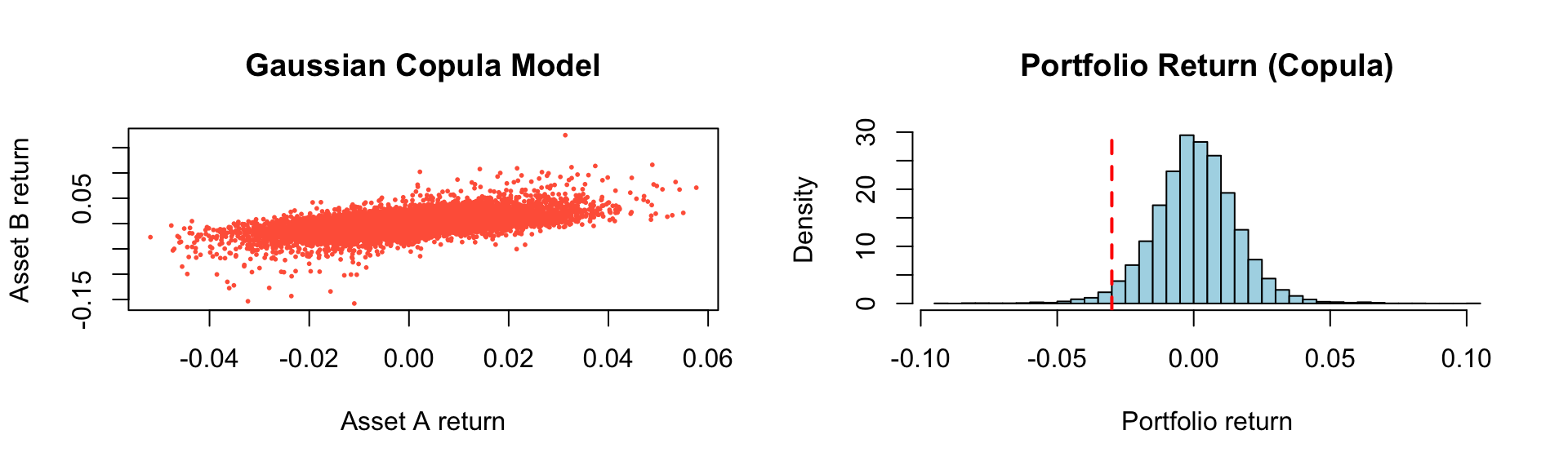
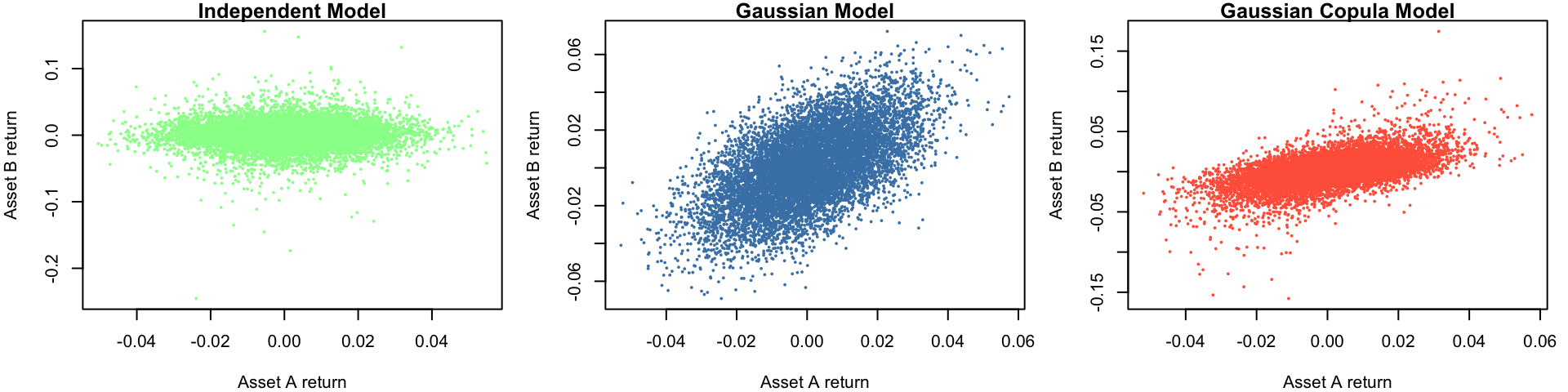
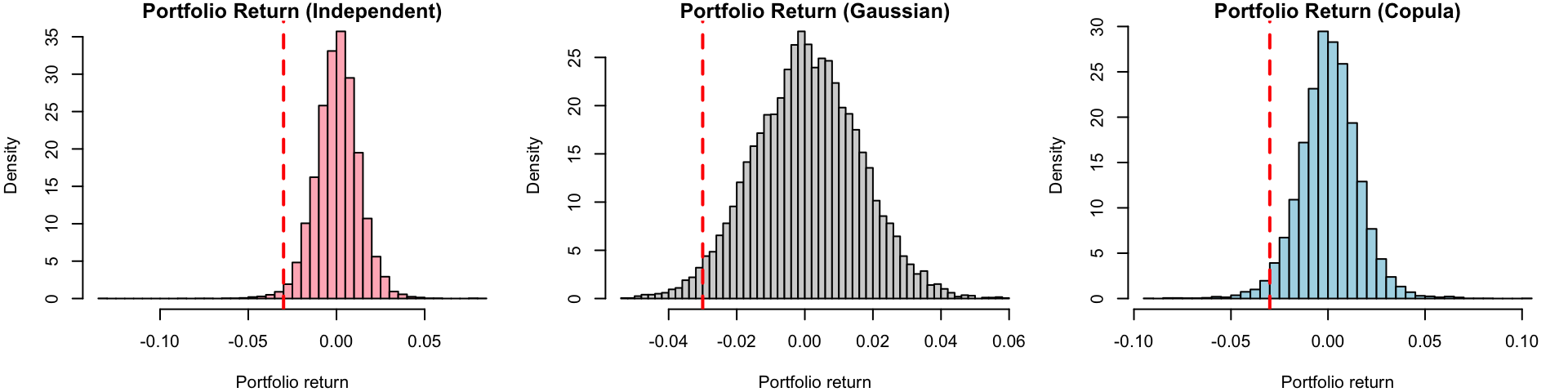
set.seed(1234)
library(MASS)
# Original distribution
mu <- c(1, 2)
Sigma <- matrix(c(4, 1,
1, 1), 2, 2)
n <- 5000
X <- mvrnorm(n, mu = mu, Sigma = Sigma)
# Linear transformation
A <- matrix(c(1, 0,
-1, 2), 2, 2)
b <- c(0, 1)
# Matrix algebra
Y <- t(A %*% t(X)) + matrix(b, n, 2, byrow = TRUE)
par(mfrow = c(1, 2), mar = c(4,4,1,1))
plot(X[,1], X[,2], pch = 16, cex = 0.4, col = "steelblue",
main = "Original X ~ N(mu, Sigma)",
xlab = "X1", ylab = "X2")
plot(Y[,1], Y[,2], pch = 16, cex = 0.4, col = "tomato",
main = "Transformed Y = A X + b",
xlab = "Y1", ylab = "Y2")