[1] 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0STAT2005 Computer Simulation
Lecture 7 — Stochastic Modelling
23 Apr 2026
Random Walk
- Random walk is a simple stochastic process that models a path consisting of a succession of random steps.
Example: Discrete-time, discrete-state random walk
\[ X_0 = 0, \quad X_{t} = X_{t-1} + Z_t = \sum_{i=1}^t Z_i, \quad t = 1, 2, ... \]
where
\[ Z_t = \begin{cases}+1 & \text{with probability } p \\ -1 & \text{with probability } 1-p \end{cases} \]
and \(Z_t\) are i.i.d. random variables.
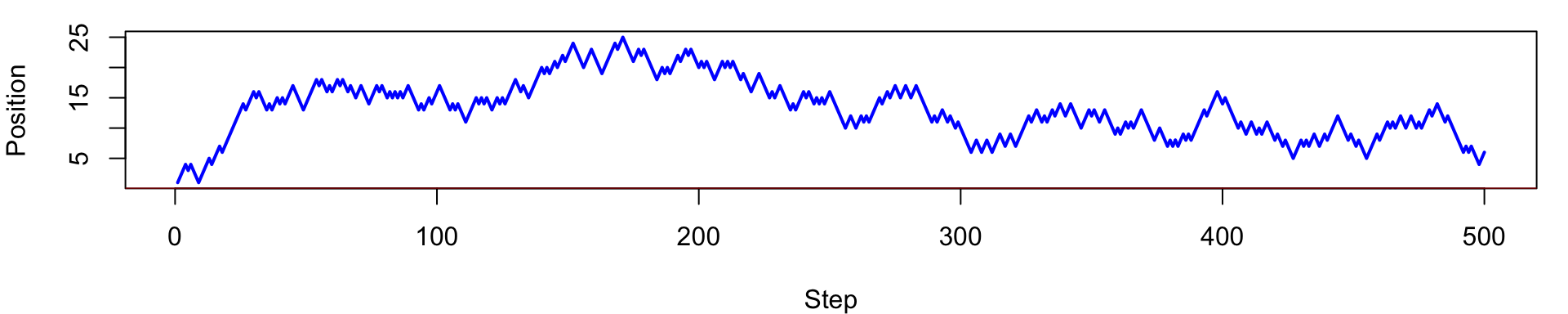
Path is jagged
Variance grows with time
No smoothness
Generalised Wiener Process
- If the mean of the increments is non-zero, we can introduce a drift term \(\mu\) to model a process with a trend, and
- if the variance of the increments is not equal to 1, we can introduce a volatility term \(\sigma\) to model a process with different levels of variability.
A generalised Wiener process \(X_t\) is defined as:
\[ X_t = \mu t + \sigma W_t. \]
where \(\mu\) is drift (trend) and \(\sigma\) is volatility (randomness).
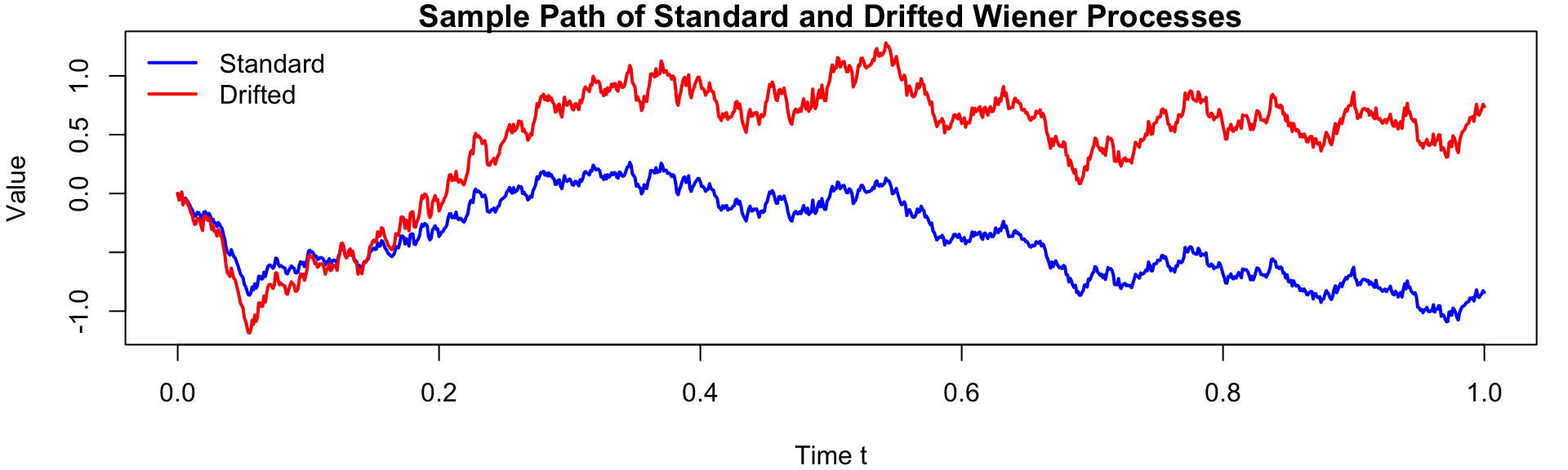
Example: Simulate a standard Wiener process and a generalised Wiener process with \(\mu = 2.0\) and \(\sigma = 1.5\).
Sample Path of Standard vs Drifted Wiener Process
set.seed(1234)
T <- 1
n <- 1000
dt <- T / n # increment size
t <- seq(0, T, length.out = n + 1) # time points from "0" to T
# Standard Wiener increments
dW <- rnorm(n, mean = 0, sd = sqrt(dt))
# Standard Wiener process
# W(t) ~ N(0, t)
W <- c(0, cumsum(dW))
# Drifted Wiener process
# X(t) ~ N(mu*t, sigma^2 * t)
mu <- 2.0
sigma <- 1.5
X <- mu * t + sigma * W
par(mar=c(4,4,1,1))
plot(
t, W, type = "l", lwd = 2, col = "blue",
xlab = "Time t", ylab = "Value", ylim = range(W, X),
main = "Sample Path of Standard and Drifted Wiener Processes"
)
lines(t, X, lwd = 2, col = "red")
legend(
"topleft",
legend = c("Standard", "Drifted"),
col = c("blue", "red"),
lwd = 2, bty = "n"
)
Multiple realisations of standard vs drifted Wiener process
set.seed(1234)
n <- 1000
m <- 20
dt <- 1 / n
t <- seq(0, 1, length.out = n + 1)
Z <- matrix(rnorm(n * m, mean = 0, sd = sqrt(dt)), n, m)
W <- rbind(0, apply(Z, 2, cumsum))
mu <- 2.0
sigma <- 1.5
Wd <- mu * t + sigma * W
ylim <- range(W, Wd)
matplot(t, W, type = "l", lty = 1, col = "blue",
ylim = ylim, xlab = "Time t", ylab = "Value")
matlines(t, Wd, lty = 1, col = "red")
legend("topleft", legend = c("Standard", "Drifted"),
col = c("blue", "red"), lwd = 2, bty = "n")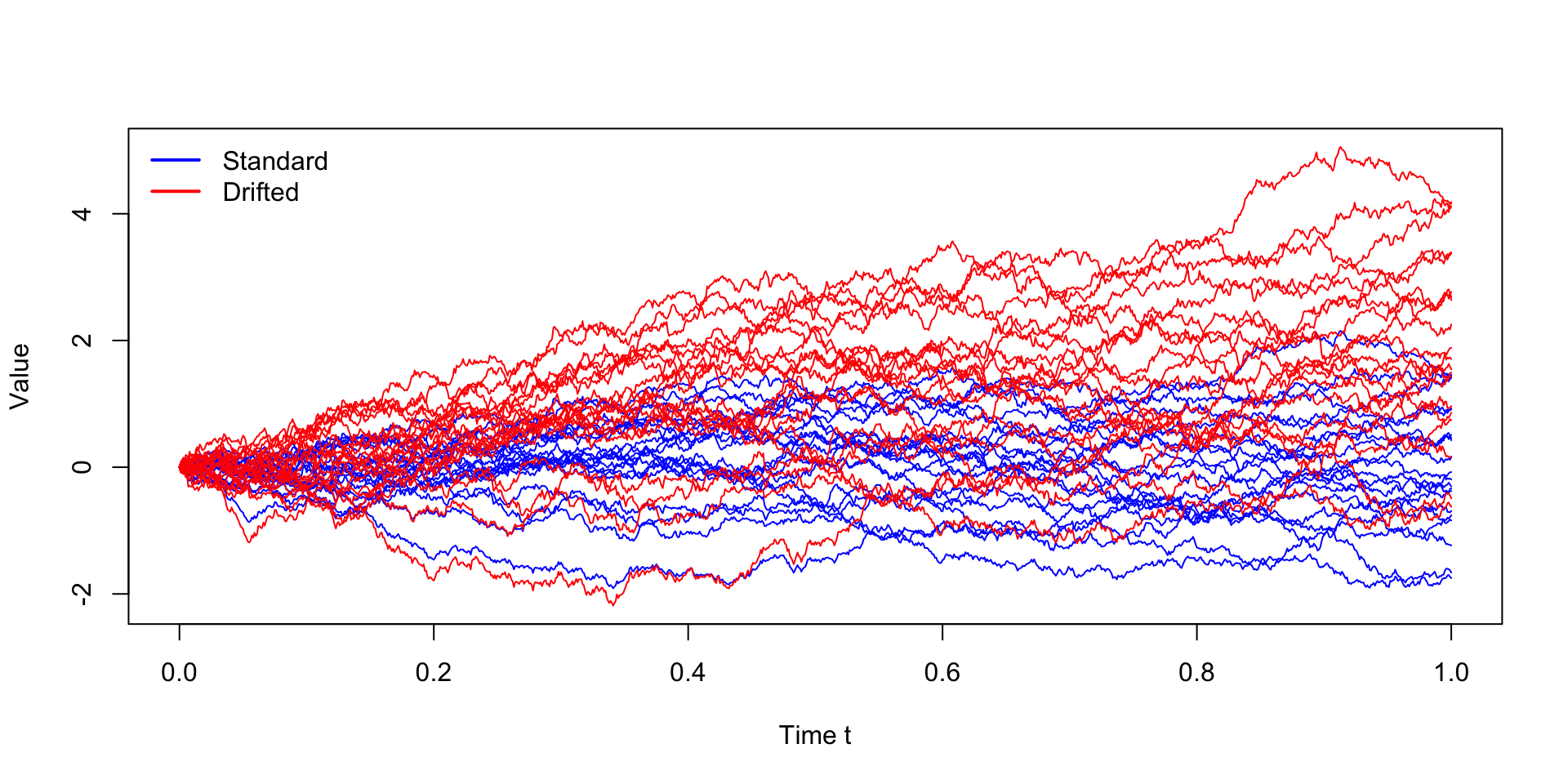
- In practice, we often simulate multiple realisations of a stochastic process to understand its variability and behaviour under different scenarios.
Example: Simulating stock prices using Geometric Brownian Motion with initial price \(S_0 = 100\), drift \(\mu = 0.1\), volatility \(\sigma = 0.2\), time horizon \(T = 5\) year, and number of time steps \(n = 1000\).
Sample Path of Geometric Brownian Motion
set.seed(1234)
# Parameters
S0 <- 100
mu <- 0.1
sigma <- 0.2
T <- 5
n <- 1000
dt <- T / n
t <- seq(0, T, length.out = n + 1)
# Simulate standard Wiener process
W <- c(0, cumsum(rnorm(n, mean = 0, sd = sqrt(dt))))
# Simulate Geometric Brownian Motion
S <- S0 * exp((mu - 0.5 * sigma^2) * t + sigma * W)
# Plot the sample path of Geometric Brownian Motion
par(mar=c(4,4,2,1))
plot(t, S, type = "l", lwd = 2, col = "darkgreen",
xlab = "Time t", ylab = "Stock Price S(t)",
main = "Geometric Brownian Motion Sample Path")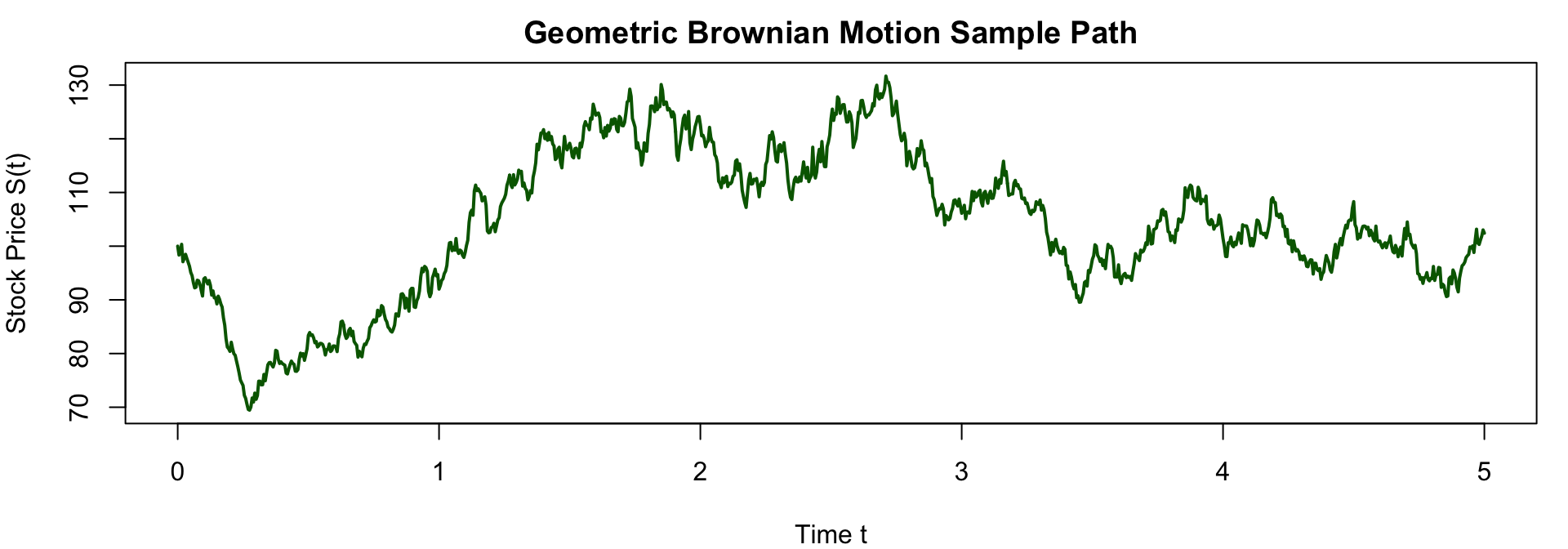
- GBM shows how the stock price evolves over time with a positive drift and volatility, resulting in an exponential growth pattern with random fluctuations.
- The sample path illustrates the typical behaviour of stock prices, which can experience significant variability while generally trending upwards due to the positive drift.
Example: Simulating a HPP with rate \(\lambda = 2\) events per unit time over the interval \([0, 10]\).
[1] 1.11 1.21 2.60 2.86 3.43 5.45 6.39 7.06 7.66 8.00 8.23 8.40 8.83 9.13[1] 14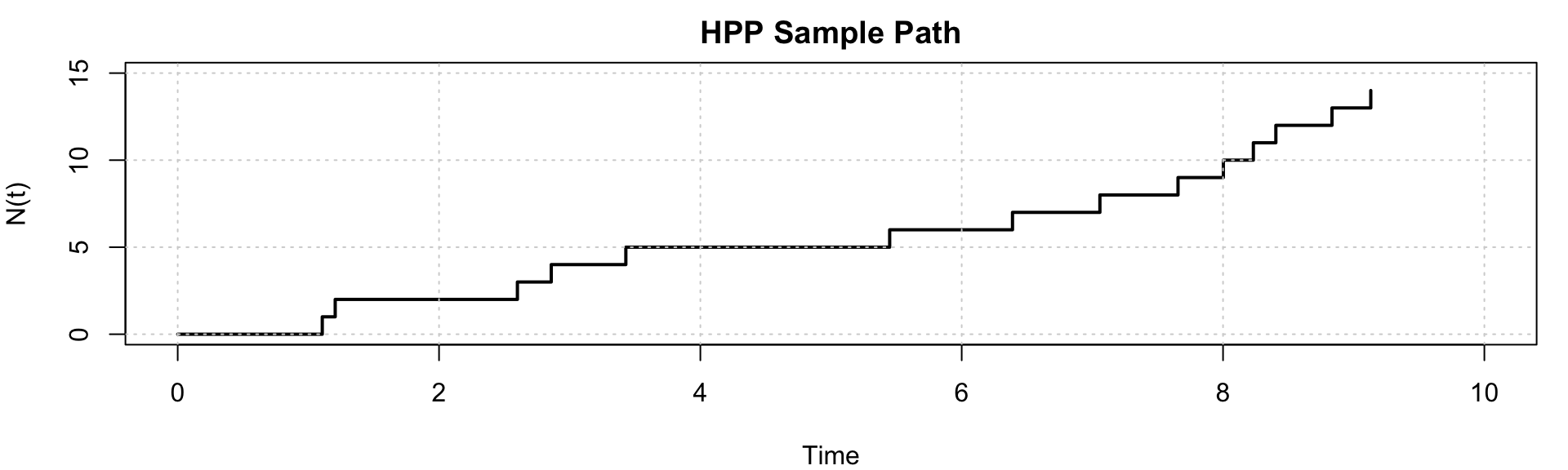
The sample path of the HPP shows the number of events \(N(t)\) increasing in a stepwise manner as time progresses, with the inter-arrival times between events following an exponential distribution. The rate \(\lambda\) determines how frequently events occur, and the plot illustrates the random nature of event occurrences over time.
We can also check the count distribution of \(N_t\) for the HPP by simulating many trajectories and comparing the empirical distribution with the theoretical Poisson distribution.
Distribution of Counts for HPP
# Empirical distribution of counts
hist(counts, breaks = 30, probability = TRUE,
main = "Distribution of Nt for HPP", xlab = "Count")
x_vals <- 0:max(counts)
# Theoretical Poisson distribution with mean lambda * T_max
points(x_vals, dpois(x_vals, lambda = 2 * 10), pch = 19, cex = 0.6)
legend("topright", legend = c("Empirical", "Theoretical"),
col = c("grey", "black"), pch = c(15, 19), lwd = c(2, 2), bty = "n")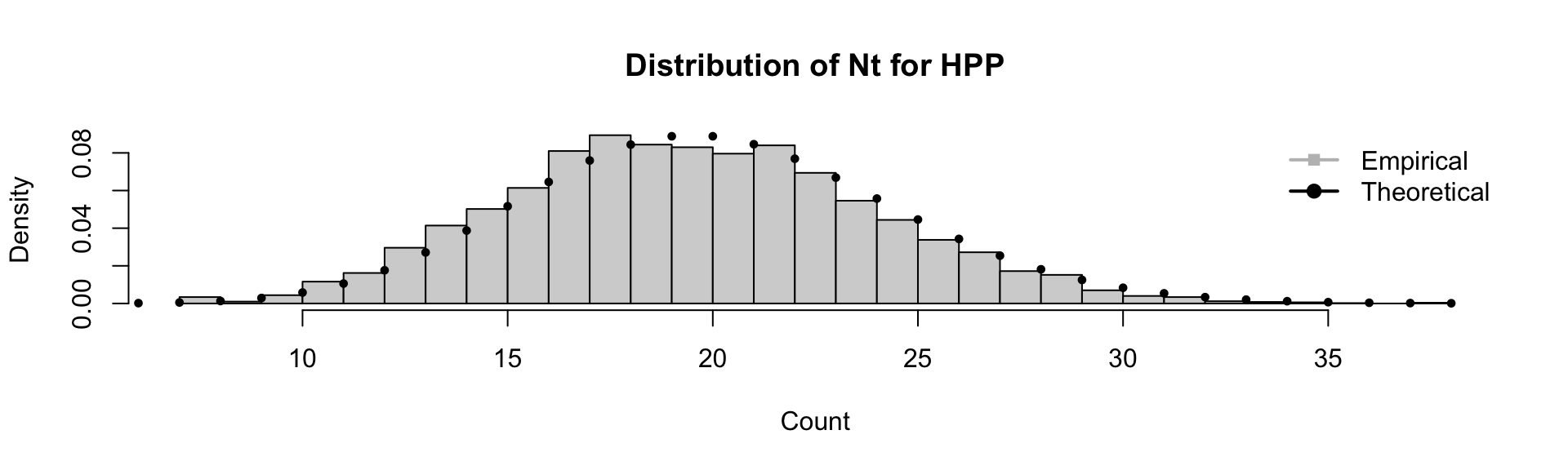
The empirical distribution of the counts \(N_t\) closely matches the theoretical Poisson distribution with mean \(\lambda T_{\max}\).
Non-homogeneous Poisson Process (NHPP)
graph LR
A((0)) -->|"$$\lambda_0$$"| B((1))
B -->|"$$\lambda_1$$"| C((2))
C -->|"$$\lambda_2$$"| D(("$$\cdots$$"))
D -->|"$$\lambda_{k-1}$$"| E(("$$k$$"))
E -->|"$$\lambda_{k}$$"| F(("$$\cdots$$"))
A --- B --- C --- D --- E --- F
linkStyle 5,6,7,8,9 stroke:#ffffff
style D fill:#FFFFFF00, stroke:#FFFFFF00;
style F fill:#FFFFFF00, stroke:#FFFFFF00;
- NHPP is a Poisson process where the rate \(\lambda(t)\) varies over time.
- The expected number of events in a time interval depends on the specific time period.
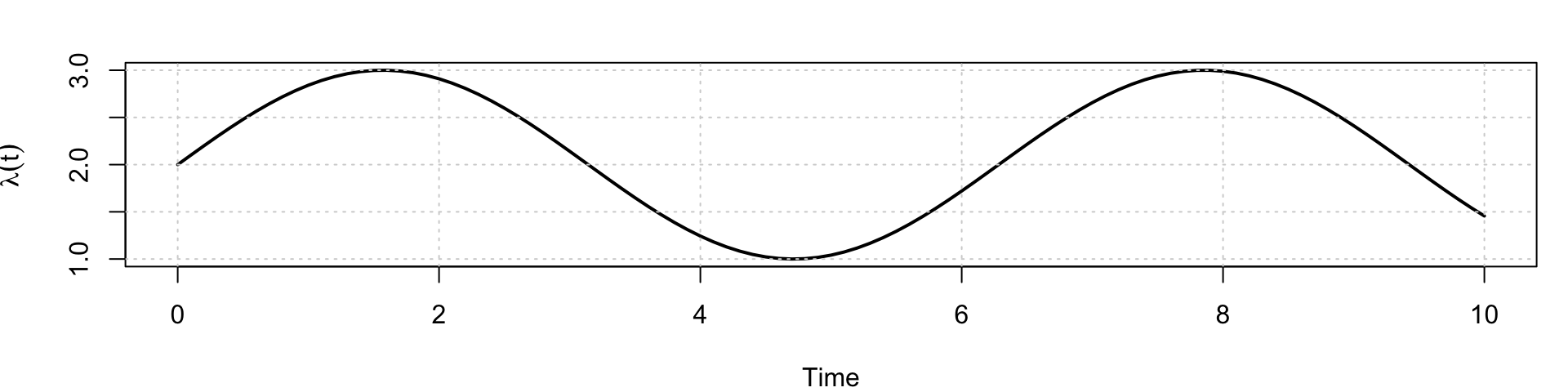
Example: Simulating a NHPP with a rate function \[ \lambda(t) = 2 + \sin(t), \quad 0 \leq t \leq 10. \]
The function is always positive and oscillates between 1 and 3, with an average rate of 2 events per unit time.
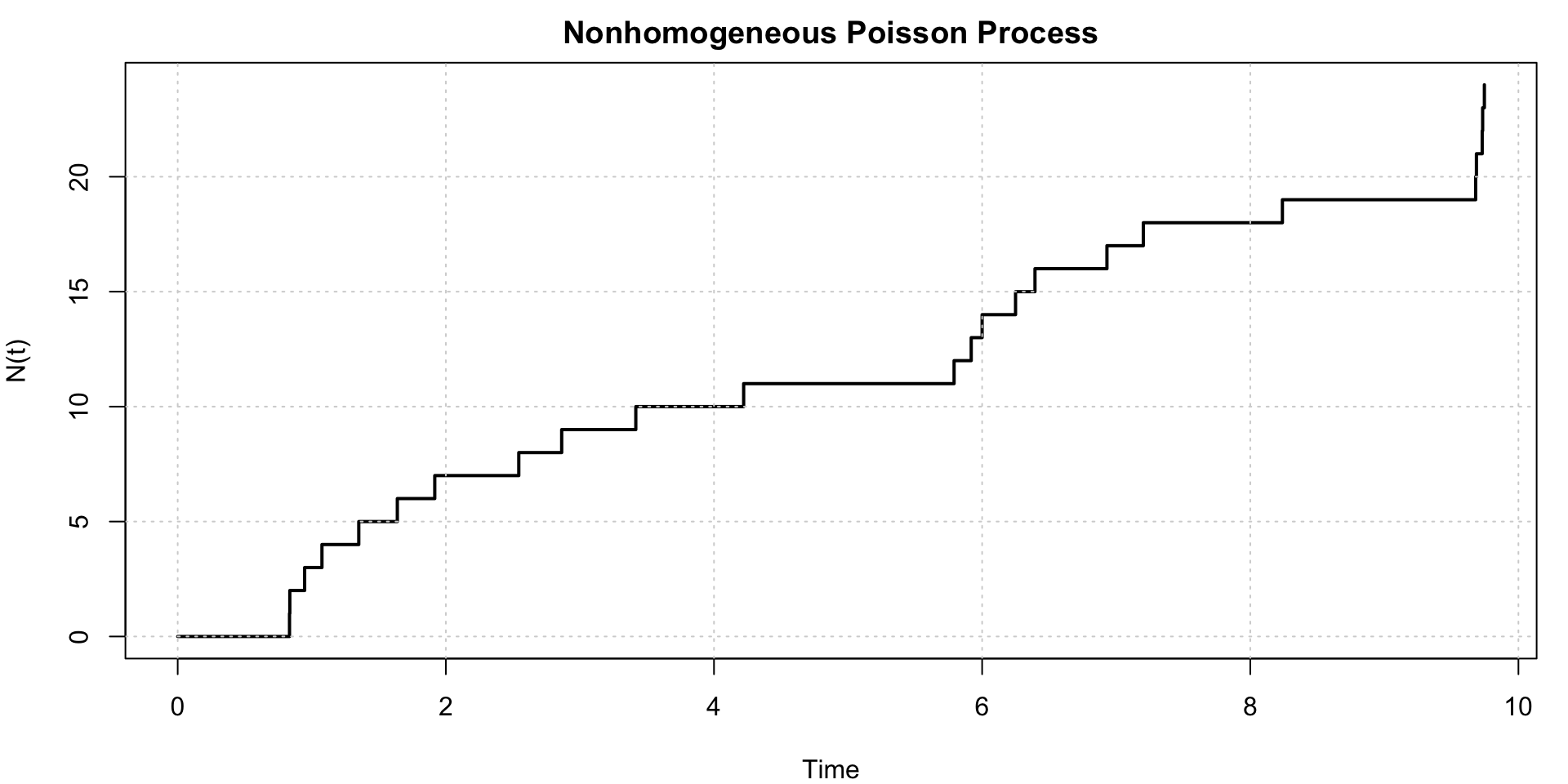
The sample path of the NHPP shows the number of events \(N(t)\) increasing in a stepwise manner, but the rate of increase varies over time according to the rate function \(\lambda(t)\). The inter-arrival times are not exponentially distributed with a constant rate, and the process exhibits non-stationary increments due to the time-varying intensity.
Extend the simulation to multiple runs to check the distribution of counts \(N_t\):
Mean: 21.78
Variance: 21.33627Distribution of Counts for NHPP
# Empirical distribution of counts
hist(counts_nhpp, breaks = 30, probability = TRUE,
main = "Distribution of Nt for NHPP",
xlab = "Count")
x_vals <- 0:max(counts_nhpp)
# Theoretical Poisson distribution with mean equal to the expected count
points(x_vals, dpois(x_vals, expected_count), pch = 19, cex = 0.6)
legend("topright", legend = c("Empirical", "Theoretical"),
col = c("grey", "black"), pch = c(15, 19), lwd = c(2, 2), bty = "n")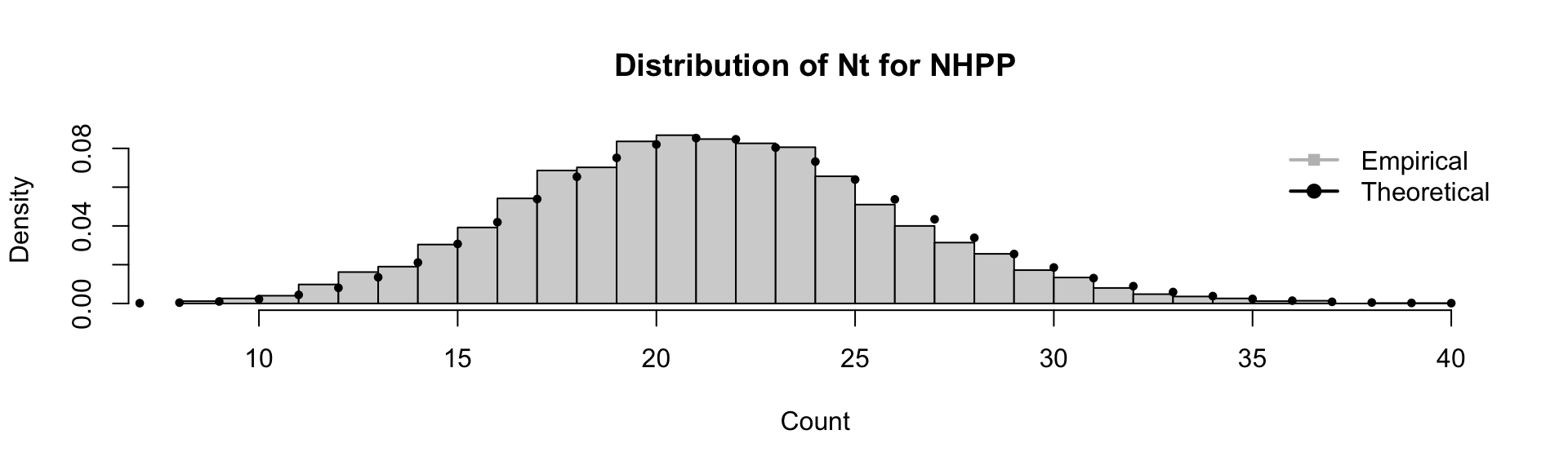
Although the rate varies over time, the number of events in a fixed interval \(N_T\) of a NHPP over a fixed interval \([0, T]\) is Poisson distributed with mean (and variance) \(\int_0^T \lambda(t) dt\). What changes relative to the homogeneous case is the lack of stationary increments.
Example: Simulate an M/M/1 queue with the following parameters:
- initial state (number of customers) \(X_0 = 0\).
- arrival rate \(\lambda = 2\)
- service rate \(\mu = 3\)
- a total simulation time of 10 units.
Simulating an M/M/1 Queue
simulate_mm1 <- function(lambda = 2, mu = 3,
sim_time = 10, seed = 1234) {
if (!is.null(seed)) set.seed(seed)
X <- 0
T <- 0
time_vec <- c(0)
state_vec <- c(0)
event_vec <- c("Start")
# Schedule first arrival
T_a <- rexp(1, rate = lambda)
T_s <- Inf # no service when system is empty
while (T < sim_time) {
if (min(T_a, T_s) > sim_time) break
if (T_a < T_s) { # Arrival event
T <- T_a
X <- X + 1
event <- "Arrival"
# Schedule next arrival
T_a <- T + rexp(1, rate = lambda)
# If server was idle, start service
if (X == 1) {
T_s <- T + rexp(1, rate = mu)
}
} else { # Departure event
T <- T_s
X <- X - 1
event <- "Departure"
# If there are still customers, schedule next departure
if (X > 0) {
T_s <- T + rexp(1, rate = mu)
} else {
T_s <- Inf
}
}
time_vec <- c(time_vec, T)
state_vec <- c(state_vec, X)
event_vec <- c(event_vec, event)
}
data.frame(
time = round(time_vec, 4),
state = state_vec,
event = event_vec
)
}
df <- simulate_mm1(lambda = 2, mu = 3, sim_time = 10, seed = 1234)
plot(
df$time, df$state,
type = "s",
xlim = c(0, 10),
xlab = "Time",
ylab = "Number in system",
main = "M/M/1 sample path"
)
points(df$time, df$state,
pch = ifelse(df$event == "Arrival", 16, ifelse(df$event == "Departure", 17, 15)),
col = ifelse(df$event == "Arrival", "blue", ifelse(df$event == "Departure", "red", "black")))
legend(
"topleft", ncol = 3, bty = "n",
legend = c("Arrival", "Departure", "Start"),
pch = c(16, 17, 15),
col = c("blue", "red", "black"))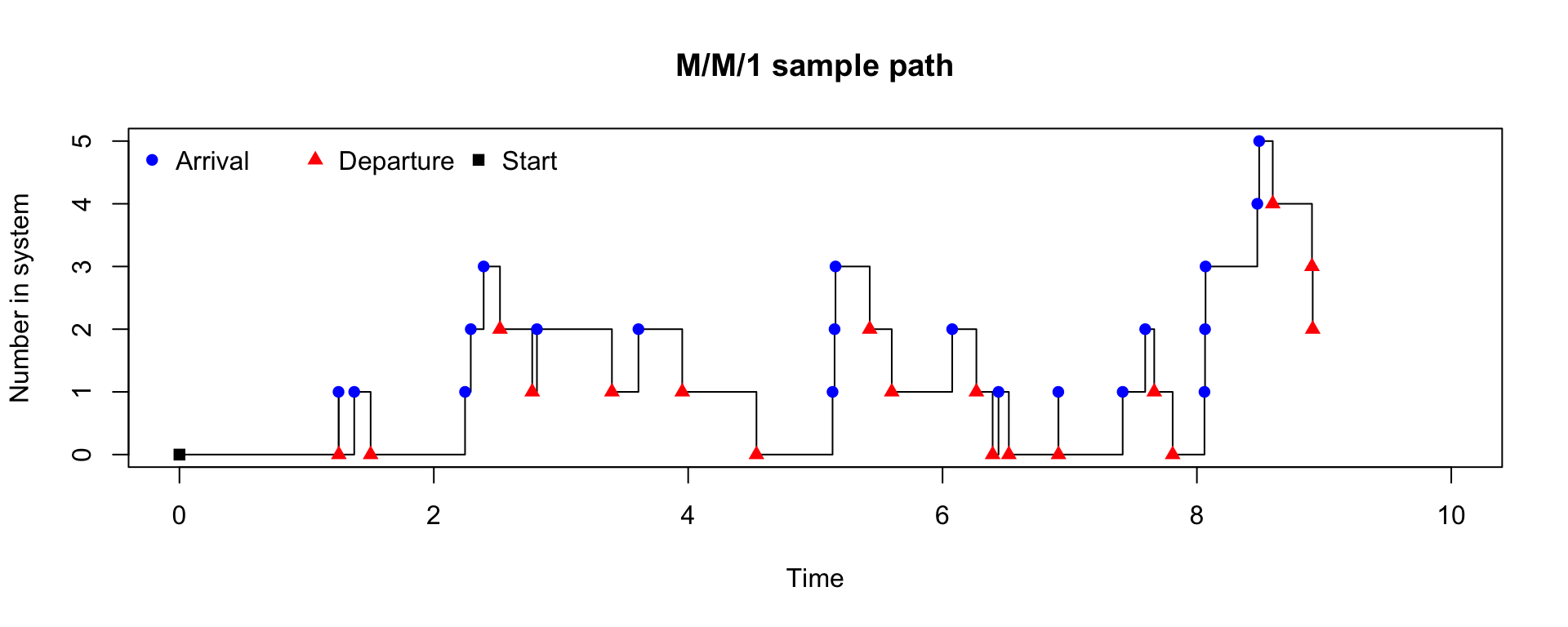
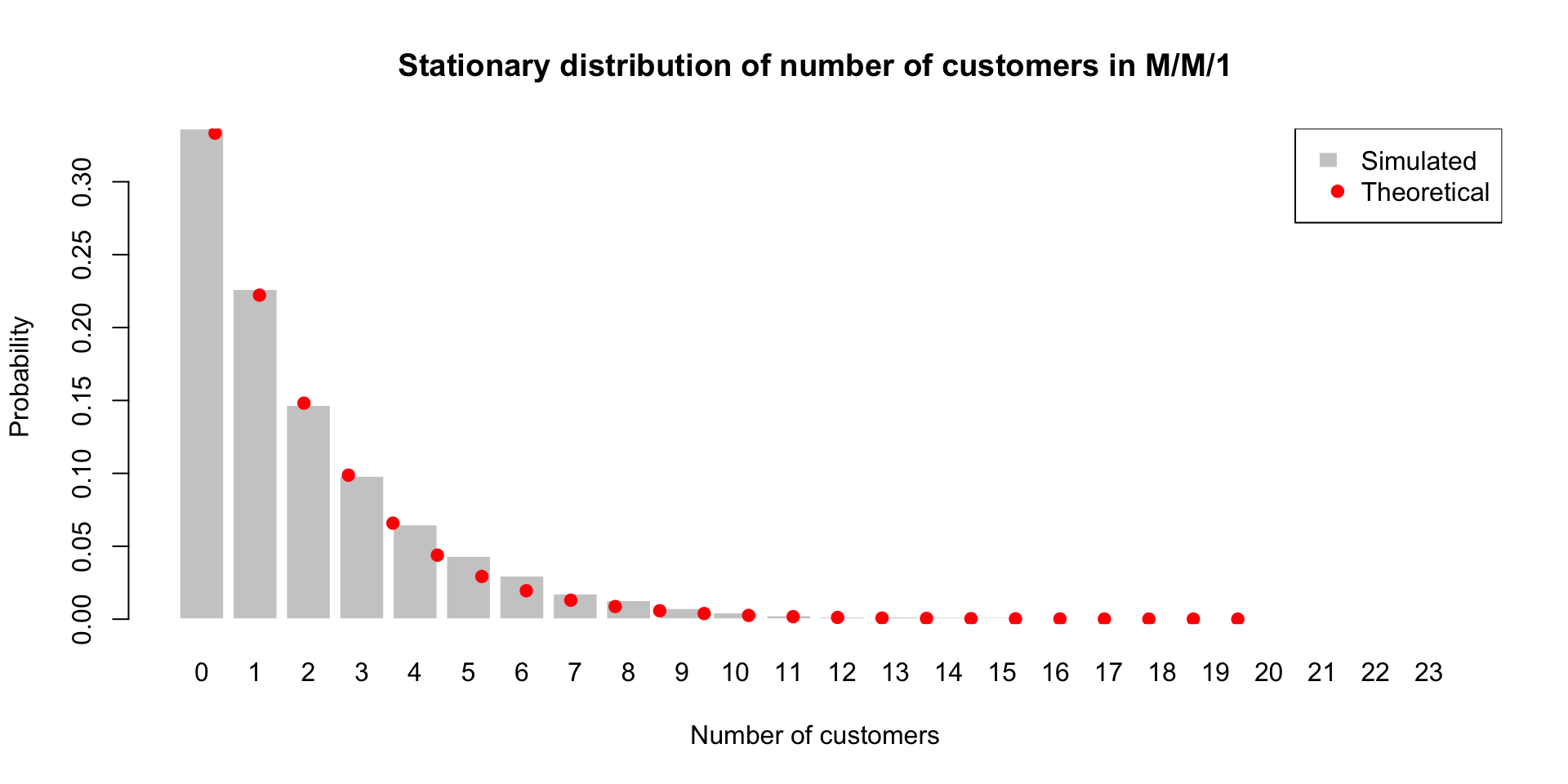
We can also check the stationary distribution of the number of customers in the system.
Stationary Distribution of M/M/1 Queue
# Time spent in each state
time_in_state <- tapply(durations, states, sum)
max_state <- max(as.integer(names(time_in_state)))
pi_hat <- numeric(max_state + 1)
pi_hat[as.integer(names(time_in_state)) + 1] <- time_in_state / sum(durations)
# Theoretical stationary distribution: P(N=n) = (1-rho) rho^n
n_vals <- 0:max_state
pi_theory <- (1 - rho) * rho^n_vals
barplot(
pi_hat,
names.arg = n_vals,
col = "grey80",
border = "white",
main = "Stationary distribution of number of customers in M/M/1",
xlab = "Number of customers",
ylab = "Probability"
)
points(
x = seq_along(n_vals),
y = pi_theory,
pch = 19,
col = "red"
)
legend(
"topright",
legend = c("Simulated", "Theoretical"),
fill = c("grey80", NA),
border = c("white", NA),
pch = c(NA, 19),
col = c("black", "red")
)