y: x^3/3STAT2005 Computer Simulation
Lecture 9 — Monte Carlo Integration & Markov Chain Monte Carlo
14 May 2026
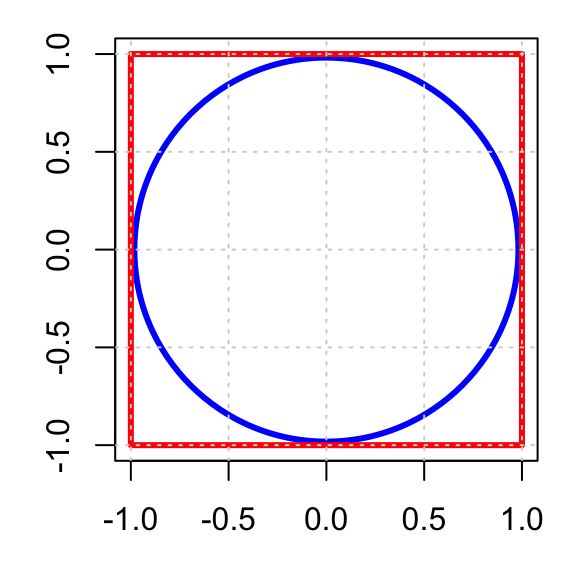
Example 2: Estimating an Area \(\pi\) of a Unit Circle
Consider the square \([-1,1]\times[-1,1]\) with area 41.
Inside the square is a circle of radius 1 centred at the origin. The equation of the circle is
\[ x^2 + y^2 = 1. \tag{3}\]
Since the radius of the circle is 1, the area of the circle is
\[ \pi r^2 = \pi (1)^2 = \pi. \]
How can we use Monte Carlo integration to estimate the area of the unit circle \(\pi\)?
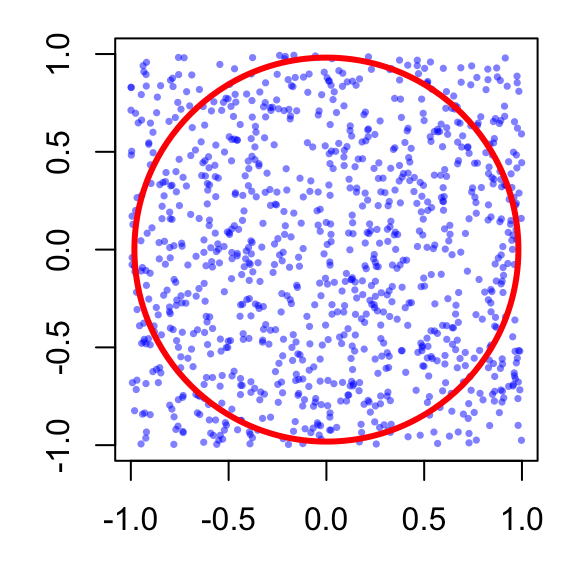
[1] 3.144Python Version
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1234)
x = np.random.uniform(-1, 1, 1000)
y = np.random.uniform(-1, 1, 1000)
fig, ax = plt.subplots()
ax.set_aspect('equal')
ax.set_xlabel(""); ax.set_ylabel("")
ax.scatter(x, y, s=10, alpha=0.5)
circle = plt.Circle((0, 0), 1, fill=False, color='red', linewidth=3)
ax.add_patch(circle)
plt.show()
n = 1000
x = np.random.uniform(-1, 1, n)
y = np.random.uniform(-1, 1, n)
inside = (x**2 + y**2 <= 1)
pi_hat = 4 * np.mean(inside)
pi_hat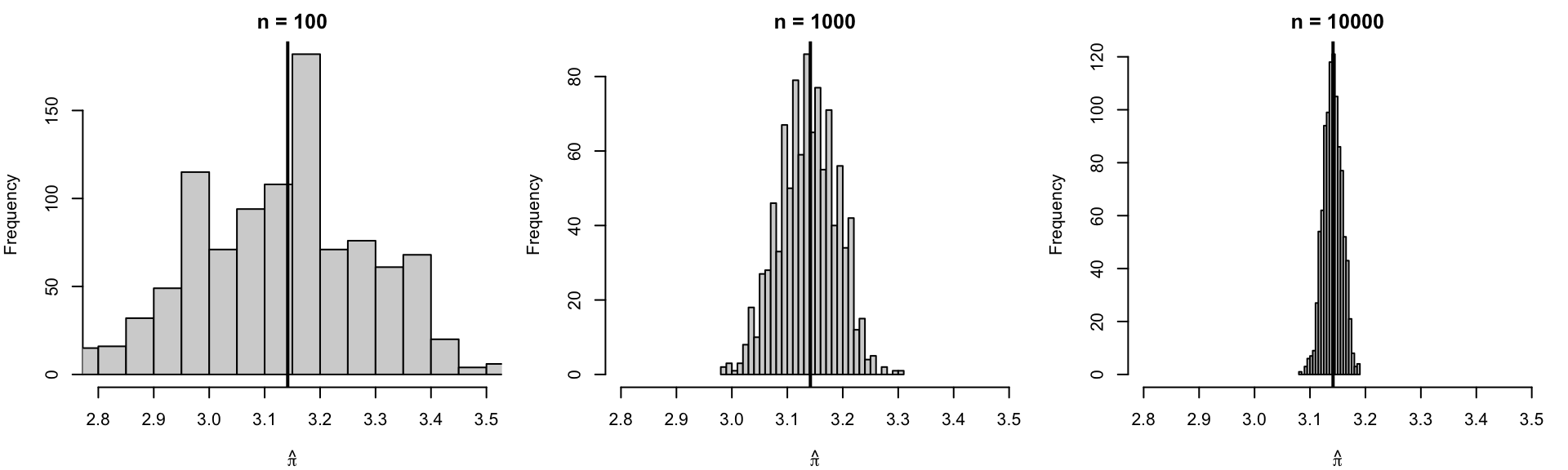
Python Version
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for i, n in enumerate(n_values):
axes[i].hist(results[f"n = {n}"], bins=30, range=(2.8, 3.5))
axes[i].axvline(np.pi, color='red', linewidth=2)
axes[i].set_title(f"n = {n}")
axes[i].set_xlabel(r'$\hat{\pi}$')
plt.tight_layout()
plt.show()Bivariate Example (Cont.)
Suppose we want to sample from a joint distribution \(p(x,y).\)
Starting from the initial values \(x^{(0)}\) and \(y^{(0)}\), the iterative updates are:
\[ x^{(t+1)} \sim p(x|y^{(t)}), \]
\[ y^{(t+1)} \sim p(y|x^{(t+1)}). \]
- These updates are repeated many times, and the sequence of samples forms a Markov chain.
- After sufficiently many iterations, the chain behaves as though it were sampling from the target joint distribution.
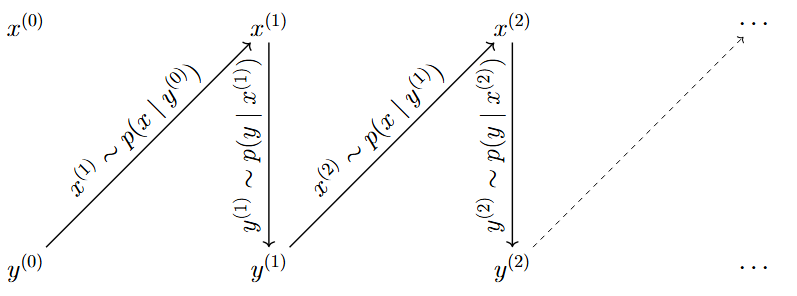
- sample a new value of \(x\) conditional on the current value of \(y\);
- sample a new value of \(y\) conditional on the updated value of \(x\).
set.seed(1234)
n <- 5000
rho <- 0.8
sd_cond <- sqrt(1 - rho^2)
x <- numeric(n)
y <- numeric(n)
x[1] <- 0
y[1] <- 0
for(i in 2:n){
x[i] <- rnorm(1, mean = rho * y[i-1], sd = sd_cond)
y[i] <- rnorm(1, mean = rho * x[i], sd = sd_cond)
}
par(mar = c(4, 4, 1, 1))
plot(x, y, pch = 16, cex = 0.4, col = rgb(0,0,1,0.3), xlab = "X", ylab = "Y")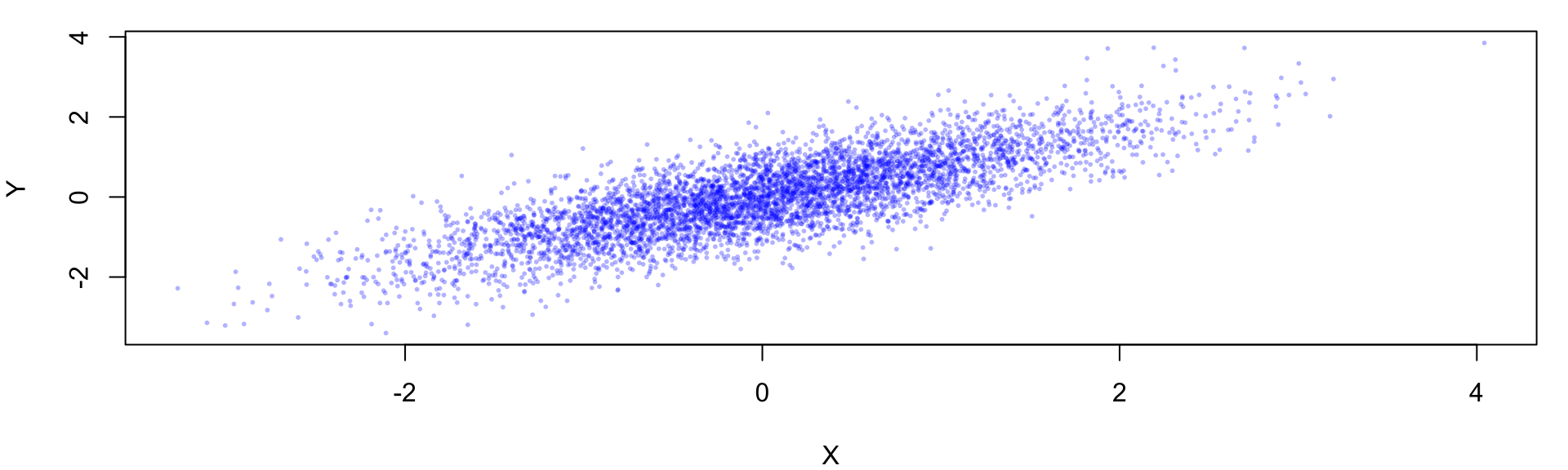
Python Version
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1234)
n = 5000
rho = 0.8
sd_cond = np.sqrt(1 - rho**2)
x = np.zeros(n)
y = np.zeros(n)
x[0] = 0
y[0] = 0
for i in range(1, n):
x[i] = np.random.normal(loc=rho * y[i-1], scale=sd_cond)
y[i] = np.random.normal(loc=rho * x[i], scale=sd_cond)
plt.scatter(x, y, alpha=0.3)
plt.xlabel("X")
plt.ylabel("Y")
plt.title("Gibbs Samples from a Bivariate Normal")
plt.show()Visualisation of Gibbs Sampling in Higher Dimensions (3 variables)
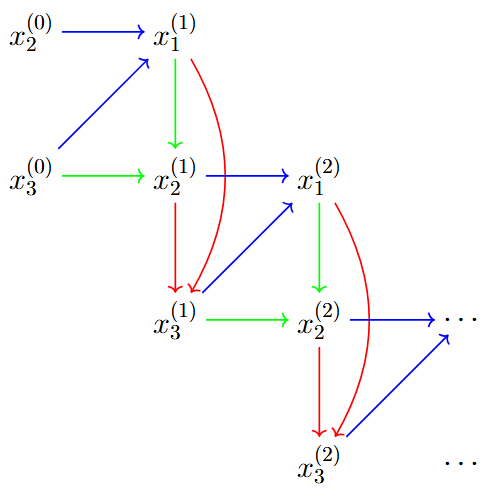
- The Gibbs sampler updates one variable at a time, conditional on the current values of the other two variables. This results in a stair-case pattern.
- Blue arrows: conditional dependencies used when updating \(x_1\)
- Green arrows: conditional dependencies used when updating \(x_2\)
- Red arrows: conditional dependencies used when updating \(x_3\)
n <- 5000 # number of iterations
x <- matrix(0, nrow = n, ncol = 3)
colnames(x) <- c("X1", "X2", "X3")
x[1, ] <- c(3, -3, 2)
for (i in 2:n) {
current <- x[i - 1, ]
for (j in 1:dim(x)[2]) {
cp <- cond_params(j, current, mu, Sigma)
current[j] <- rnorm(1, mean = cp$mean, sd = cp$sd)
}
x[i, ] <- current
}
pairs(x, pch = 16, cex = 0.3)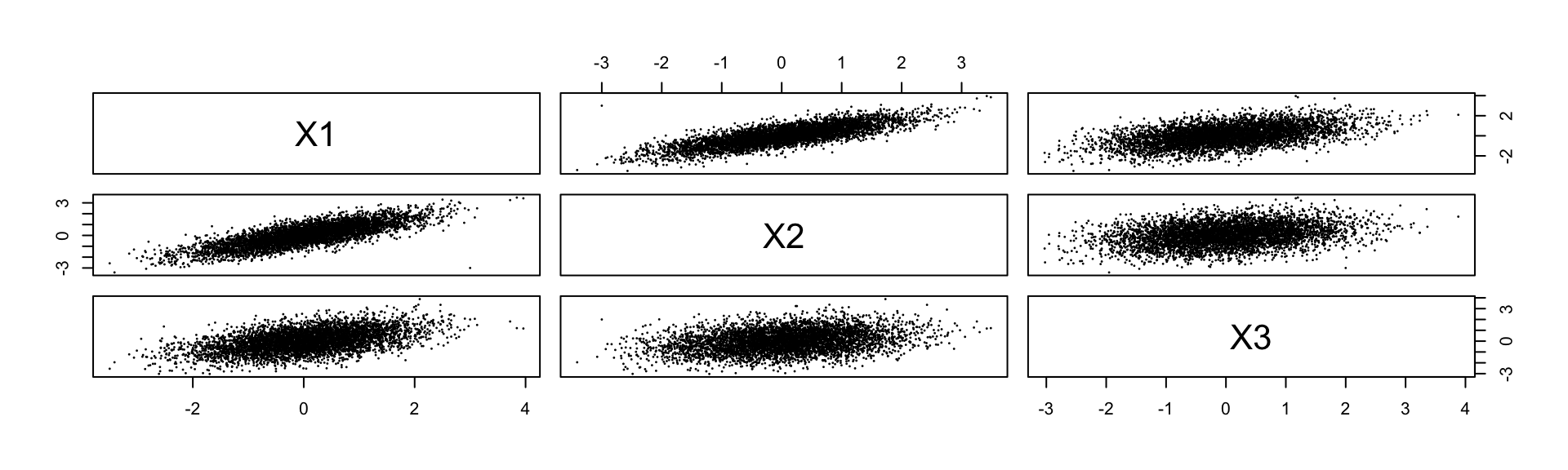
Trace Plots
A trace plot displays the sampled values over iteration number. Trace plots help assess convergence, mixing behaviour, and stability of the chain.
Good trace plots fluctuate around a stable region, show no obvious trend, and explore the distribution well.
From Example 2, we can plot the trace of each variable across iterations:
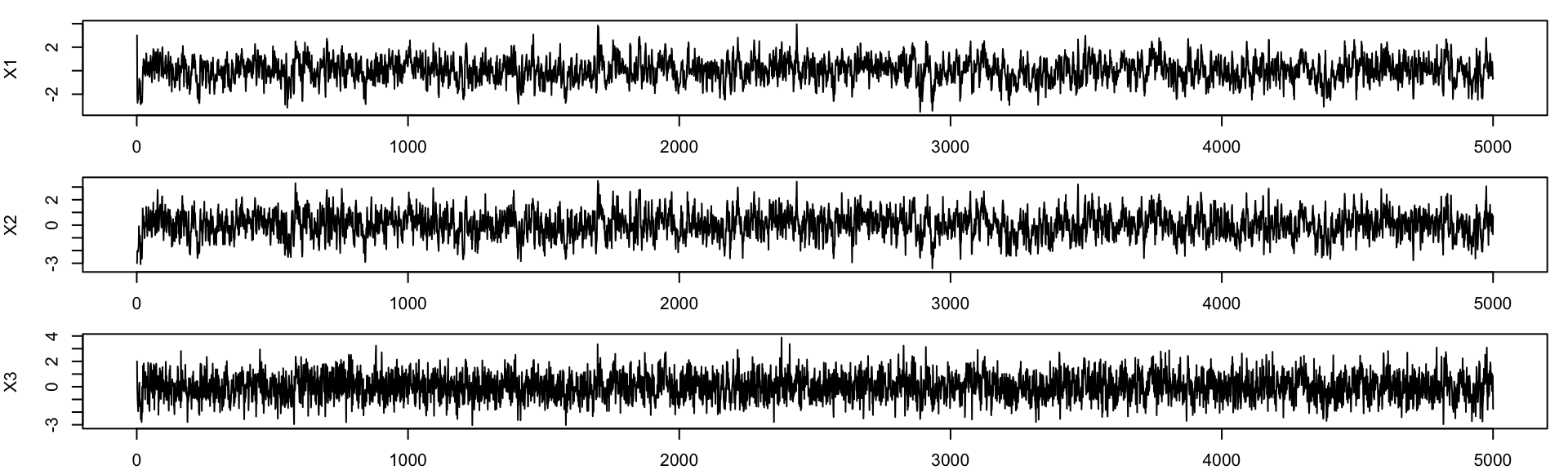
Python Version
fig, axes = plt.subplots(3, 1, figsize=(10, 8), sharex=True)
axes[0].plot(x[:, 0], color='blue')
axes[0].set_ylabel("X1")
axes[1].plot(x[:, 1], color='green')
axes[1].set_ylabel("X2")
axes[2].plot(x[:, 2], color='red')
axes[2].set_xlabel("Iteration")
axes[2].set_ylabel("X3")
plt.suptitle("Trace Plots for Gibbs Samples")
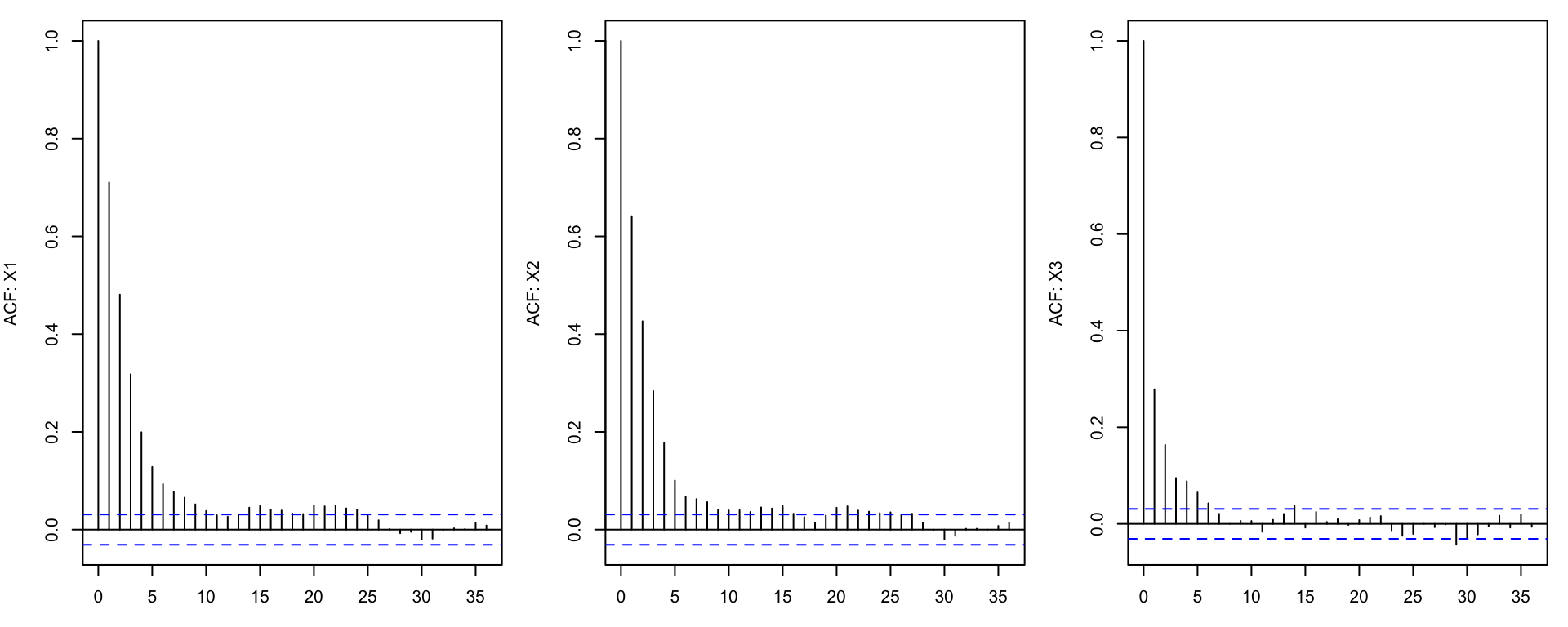
plt.show() Autocorrelation in MCMC
Gibbs samples are dependent. Successive samples are often highly correlated. This dependence is measured by autocorrelation. Strong autocorrelation means the chain moves slowly and fewer effectively independent samples are obtained.
This is one reason MCMC methods may require many iterations.