set.seed(1234)
Lb <- -4; Ub <- 4 # bounds of uniform prior / proposal
# Target posterior: proportional to Normal(0, 1), truncated to [Lb, Ub]
posterior <- function(theta) {
ifelse(theta >= Lb & theta <= Ub, dnorm(theta, mean = 0, sd = 1), 0)
}
N <- 5000
theta <- numeric(N); accepted <- logical(N)
theta[1] <- runif(1, Lb, Ub) # Initial value
for (t in 2:N) {
proposal <- runif(1, Lb, Ub)
# Acceptance probability simplifies to ratio of posteriors since proposal is symmetric
alpha <- min(1, posterior(proposal) / posterior(theta[t - 1]))
if (runif(1) < alpha) {
theta[t] <- proposal
accepted[t] <- TRUE
} else {
theta[t] <- theta[t - 1]
accepted[t] <- FALSE
}
}STAT2005 Computer Simulation
Lecture 10 — Simulation in Practice
21 May 2026
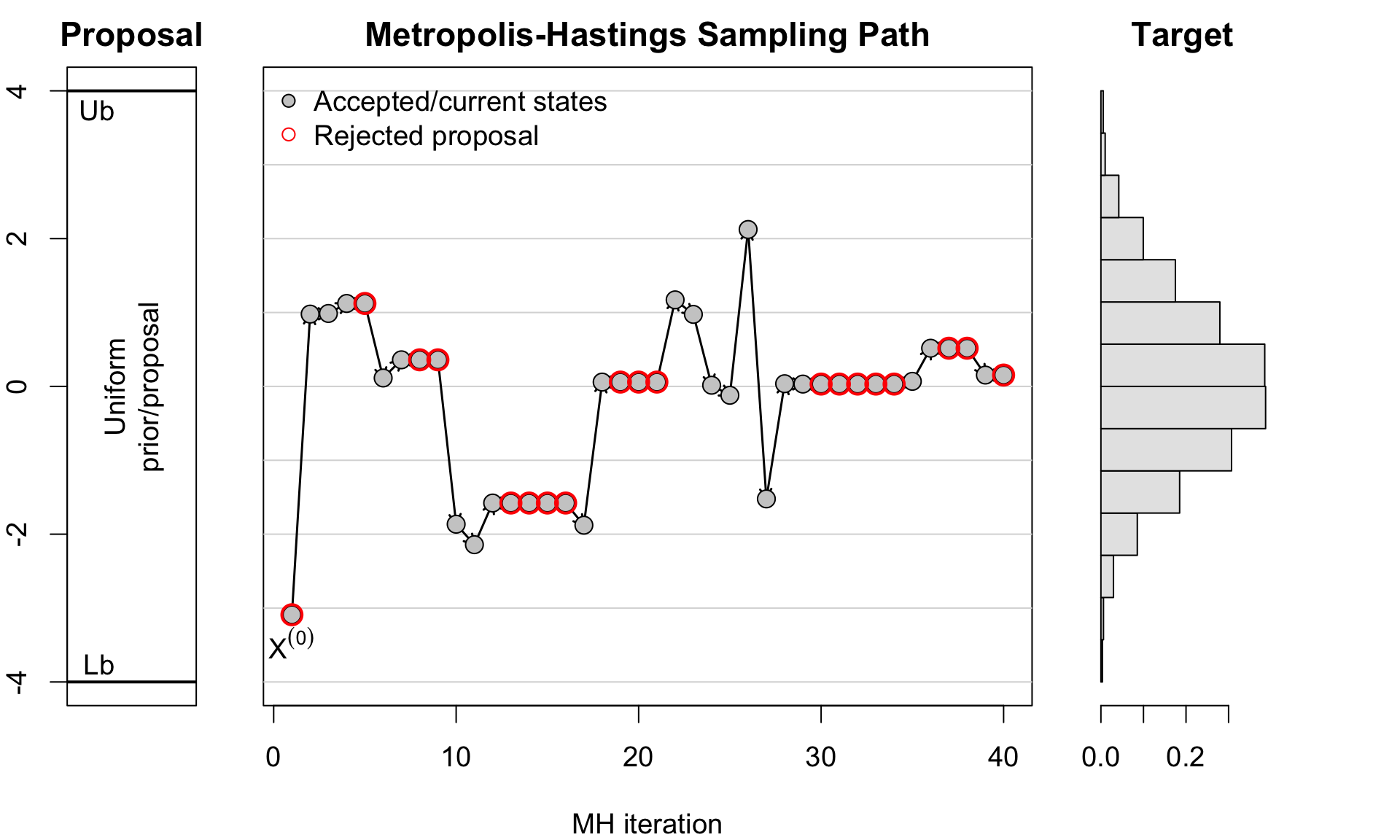
Example 3 (cont.): MH Proposal, Sampling Path & Target Distribution
Example 2: Estimating a Rare Event Probability
Suppose we want to estimate \(P(X > 4)\) where \(X \sim N(0,1).\)
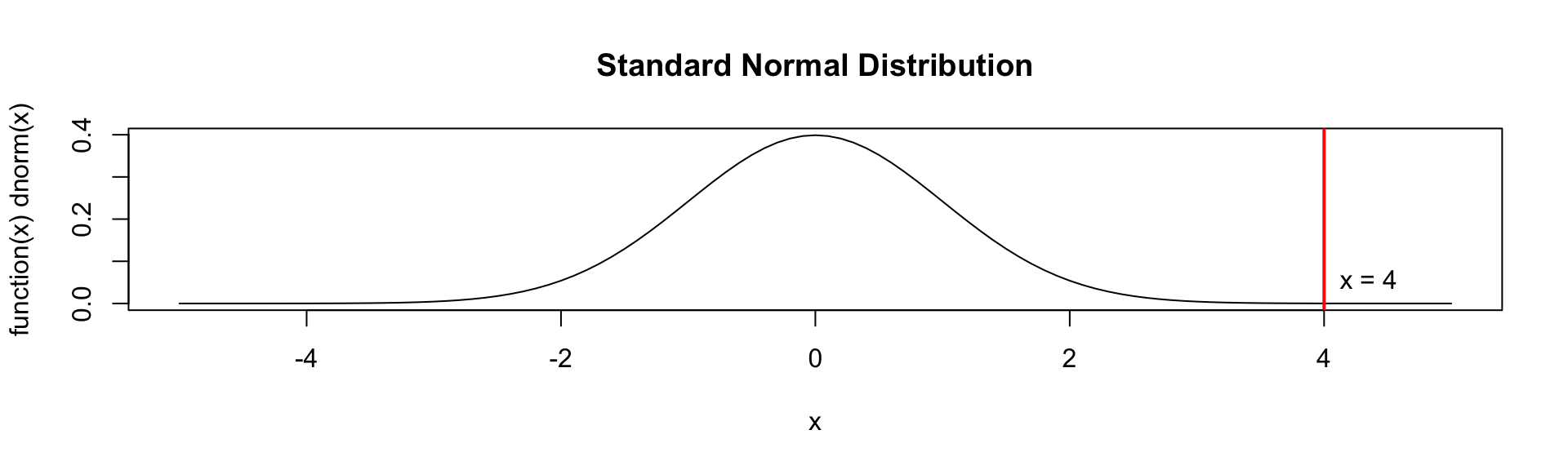
Observations larger than 4 are extremely rare under the standard normal distribution!
Python Version
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 1000)
plt.plot(x, norm.pdf(x), label='Standard Normal Distribution')
plt.axvline(x=4, color='red', linewidth=2, label='x = 4')
plt.title('Standard Normal Distribution')
plt.show()
true_prob = 1 - norm.cdf(4)
print(f"True probability P(X > 4): {true_prob}")2.2 Stratified Sampling
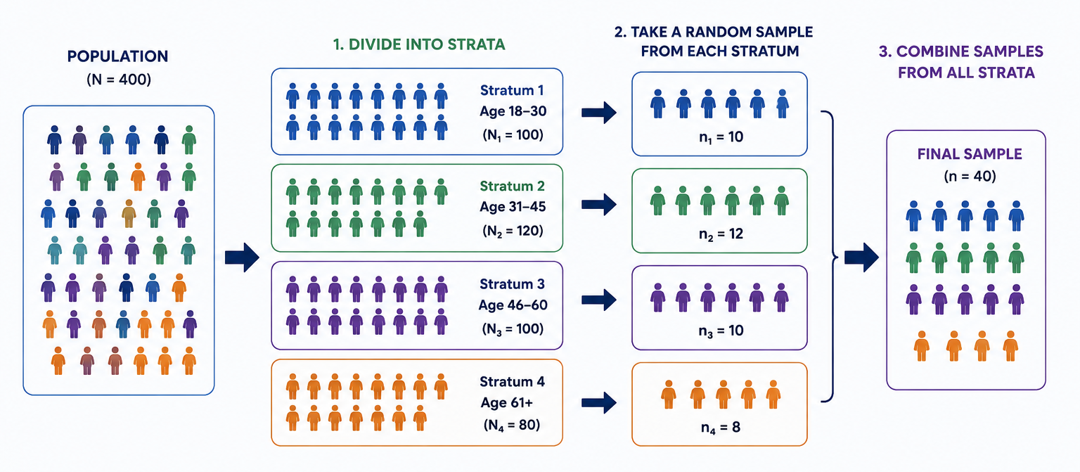
- Pure random sampling may accidentally oversample some regions of the sample space while undersampling others. This can increase Monte Carlo variability.
- Stratified sampling divides the sample space into non-overlapping regions called strata, then samples separately within each stratum. This ensures that all regions of the sample space are represented in the sample, which can reduce variance and improve estimation accuracy.
par(mfrow = c(2,1), mar = c(3,4,1.5,1))
plot(x_mc, rep(1, n), pch = 16, cex = 1.3,
xlim = c(0,1), ylim = c(0.8,1.2),
yaxt = "n", ylab = "", xlab = "Sample Space",
main = "Naive Monte Carlo Sampling")
plot(x_strat, rep(1, n), pch = 16, col = "blue", cex = 1.3,
xlim = c(0,1), ylim = c(0.8,1.2),
yaxt = "n", ylab = "", xlab = "Sample Space",
main = "Stratified Sampling")
abline(v = seq(0, 1, length.out = k+1), col = "grey70", lty = 2)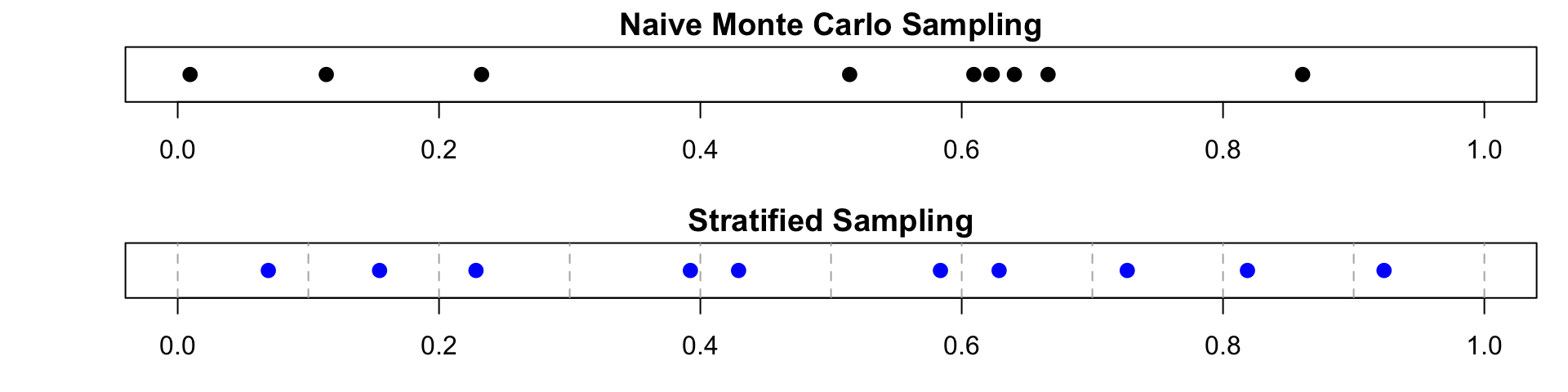
Python Version
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(1234)
n = 10 # number of samples
x_mc = np.random.uniform(size=n) # naive Monte Carlo samples
k = n # stratified sampling with n strata (one sample per stratum)
x_strat = (np.arange(k) + np.random.uniform(size=k)) / k # stratified samples
fig, axs = plt.subplots(2, 1, figsize=(6, 5))
# Naive MC
axs[0].scatter(x_mc, np.ones(n), s=100, color='steelblue')
axs[0].set_xlim(0, 1)
axs[0].set_ylim(0.8, 1.2)
axs[0].set_yticks([])
axs[0].set_xlabel("Sample Space")
axs[0].set_title("Naive Monte Carlo Sampling")
# Stratified Sampling
axs[1].scatter(x_strat, np.ones(n), s=100, color='blue')
axs[1].set_xlim(0, 1)
axs[1].set_ylim(0.8, 1.2)
axs[1].set_yticks([])
axs[1].set_xlabel("Sample Space")
axs[1].set_title("Stratified Sampling")
# Add strata boundaries
for i in range(k + 1):
axs[1].axvline(i / k, color='grey', linestyle='--')
plt.tight_layout()
plt.show()- The top plot shows the naive Monte Carlo samples, which may cluster in some regions and leave others sparsely sampled.
- The bottom plot shows the stratified samples, which are evenly distributed across the entire interval.
par(mfrow = c(1,2), mar = c(4,4,3,1))
plot(x_mc, y_mc, pch = 16, col = "steelblue",
xlab = "X", ylab = "Y", main = "Naive Monte Carlo",
xlim = c(0,1), ylim = c(0,1))
abline(v = c(0,1), col = "grey70", lty = 2)
abline(h = c(0,1), col = "grey70", lty = 2)
plot(x_strat, y_strat, pch = 16, col = "darkorange",
xlab = "X", ylab = "Y", main = "Stratified Sampling",
xlim = c(0,1), ylim = c(0,1))
abline(v = seq(0, 1, length.out = k+1), col = "grey70", lty = 2)
abline(h = seq(0, 1, length.out = k+1), col = "grey70", lty = 2)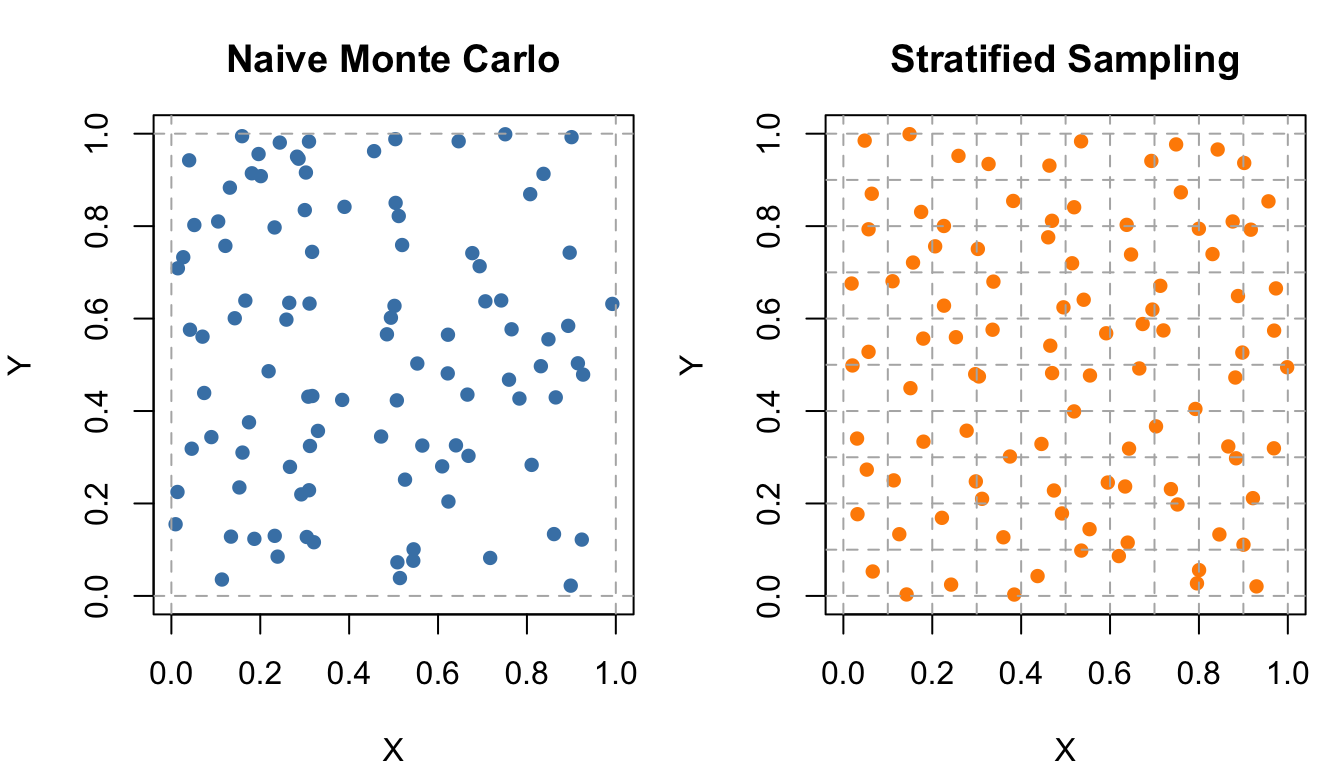
Example 5: Estimation of Area Under a Curve
Suppose we want to estimate the area under a curve defined by a function \(f(x)\) on the interval \([0,1]\),
\[ f(x) = \begin{cases} 1 & \text{if } 0 \leq x < 0.5, \\ 0.5 & \text{if } 0.5 \leq x \leq 1. \end{cases} \]
- Calculate the true area under the curve analytically.
- Compare the estimates obtained from naive Monte Carlo sampling and stratified sampling.
- Calculate variance of the two estimators and compare their efficiency.
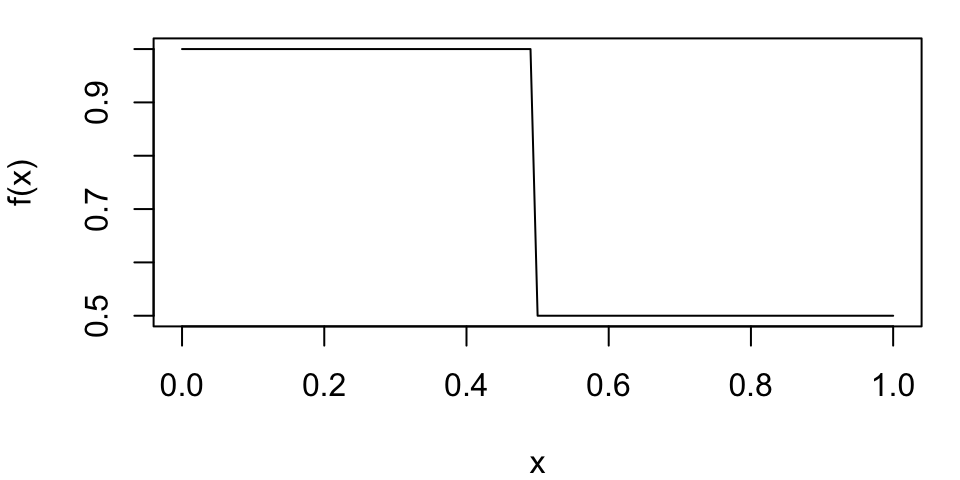
- The true area under the curve can be calculated analytically as
\[ I = \int_0^1 f(x) \, dx = \int_0^{0.5} 1 \, dx + \int_{0.5}^1 0.5 \, dx = 0.5 + 0.25 = 0.75. \]
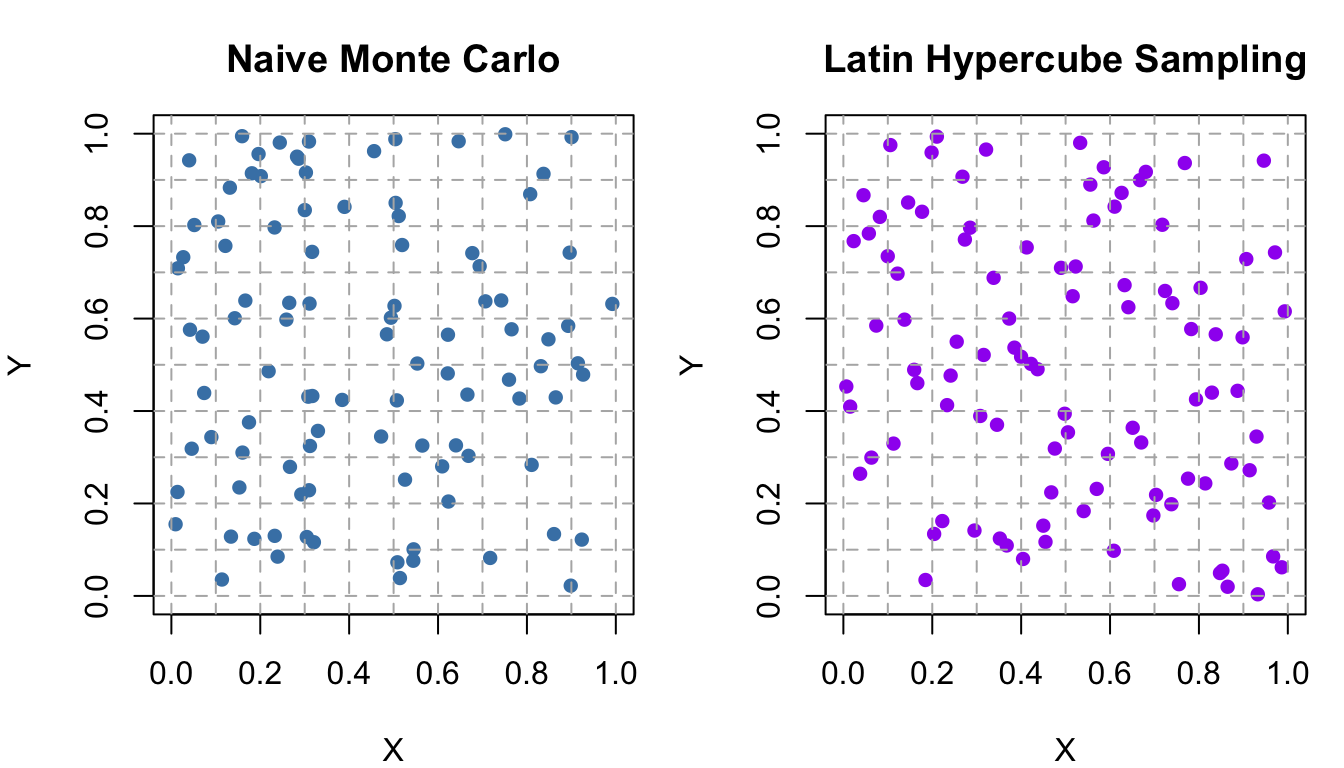
2.3 Latin Hypercube Sampling
- Latin Hypercube Sampling (LHS) extends the idea of stratified sampling to multiple dimensions.
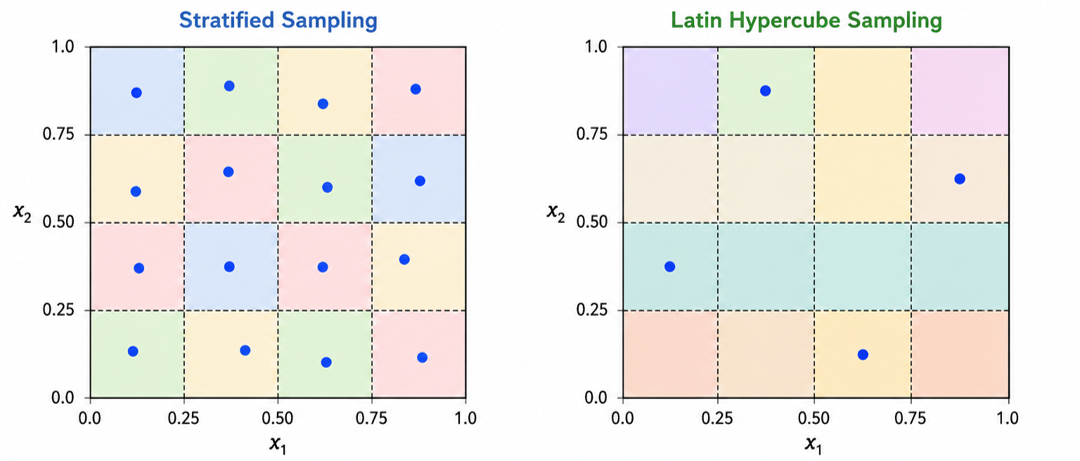
- The space is divided into 4x4 strata.
- One point is sampled from each stratum.
- Ensures uniform coverage of the sample space.
- The space is divided into 4 intervals along each dimension.
- One point is sampled from each interval along each axis.
- Ensures better coverage of the parameter space in each dimension.
par(mfrow = c(1,2), mar = c(4,4,3,1))
plot(x_mc, y_mc, pch = 16, col = "steelblue",
xlab = "X", ylab = "Y", main = "Naive Monte Carlo",
xlim = c(0,1), ylim = c(0,1))
abline(v = seq(0, 1, length.out = 11), col = "grey70", lty = 2)
abline(h = seq(0, 1, length.out = 11), col = "grey70", lty = 2)
plot(x_lhs, y_lhs, pch = 16, col = "purple",
xlab = "X", ylab = "Y", main = "Latin Hypercube Sampling",
xlim = c(0,1), ylim = c(0,1))
abline(v = seq(0, 1, length.out = 11), col = "grey70", lty = 2)
abline(h = seq(0, 1, length.out = 11), col = "grey70", lty = 2)