set.seed(123)
B <- 1000
n <- 20
lambda <- 1
xbar <- replicate(B, mean(rexp(n, rate = lambda)))
hist(xbar, breaks = 30,
main = "Sampling distribution of x̄ (Exp(1), n=20)",
xlab = "x̄")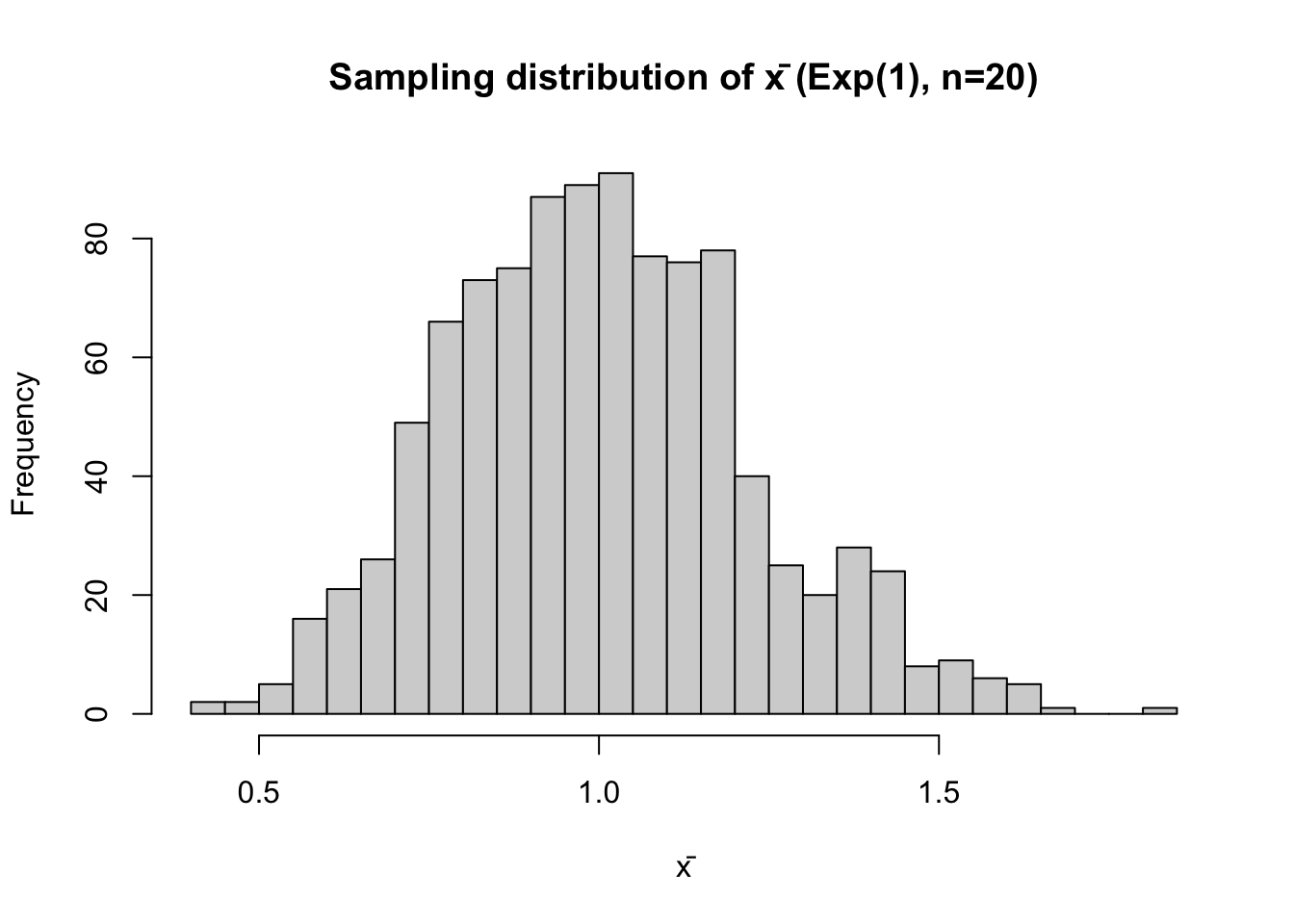
Suppose \(X_1, X_2, \dots, X_n\) are independent observations from an exponential distribution with rate \(\lambda = 1\).
Questions:
set.seed(123)
B <- 1000
n <- 20
lambda <- 1
xbar <- replicate(B, mean(rexp(n, rate = lambda)))
hist(xbar, breaks = 30,
main = "Sampling distribution of x̄ (Exp(1), n=20)",
xlab = "x̄")
The histogram looks approximately normal (CLT at work).
mean_xbar <- mean(xbar)
sd_xbar <- sd(xbar)
mean_theory <- 1 / lambda
sd_theory <- sqrt(1 / (lambda^2 * n))
# SD of x̄ for Exp(1): sqrt(Var)/sqrt(n), Var=1/lambda^2
mean_xbar; sd_xbar[1] 1.003465[1] 0.2220453mean_theory; sd_theory[1] 1[1] 0.2236068a,b,c. The simulated mean should be close to 1 (theoretical mean). The simulated SD should be close to theoretical SD calculated by
\[ \sqrt{\frac{1}{n}} = \frac{1}{\sqrt{20}} \approx 0.2236. \]
Let \(X_1, X_2, \dots, X_n \sim \text{Uniform}(0,1)\).
Two estimators of the mean \(\mu = 0.5\) are:
\[ \hat{\mu}_1 = \bar{X} \]
and
\[ \hat{\mu}_2 = \frac{n+1}{n}\bar{X}. \]
Questions:
B <- 1000
n <- 10
xbar <- replicate(B, mean(runif(n, 0, 1)))
mu_hat1 <- xbar
mu_hat2 <- ((n + 1) / n) * xbar
c(mean(mu_hat1), mean(mu_hat2)) # compare average estimates to 0.5[1] 0.4960166 0.5456182c(bias1 = mean(mu_hat1) - 0.5,
bias2 = mean(mu_hat2) - 0.5) bias1 bias2
-0.00398343 0.04561823 # Optional visual:
hist(mu_hat1, breaks = 30, main = "mu_hat1 = x̄", xlab = "Estimate")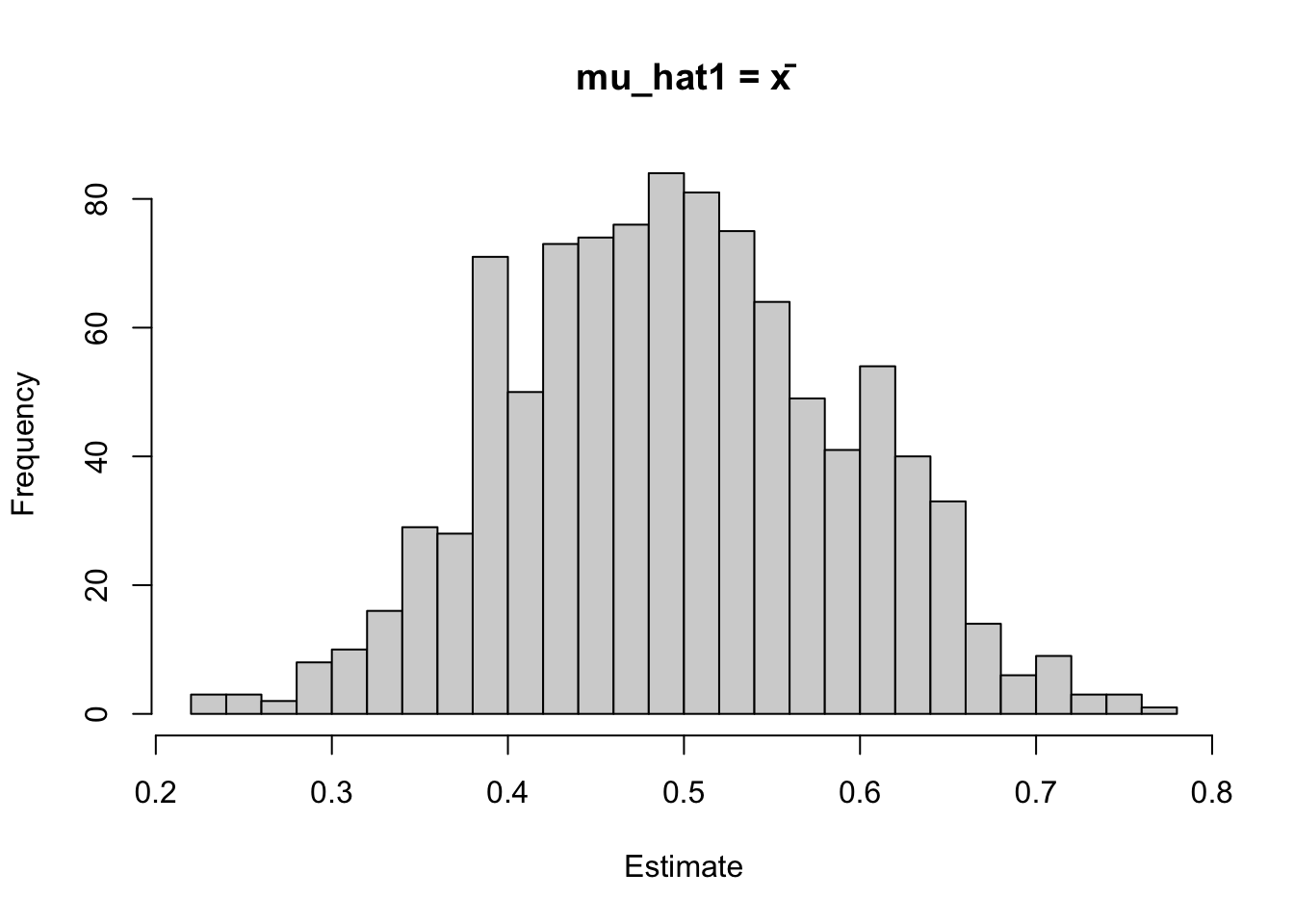
hist(mu_hat2, breaks = 30, main = "mu_hat2 = ((n+1)/n) x̄", xlab = "Estimate")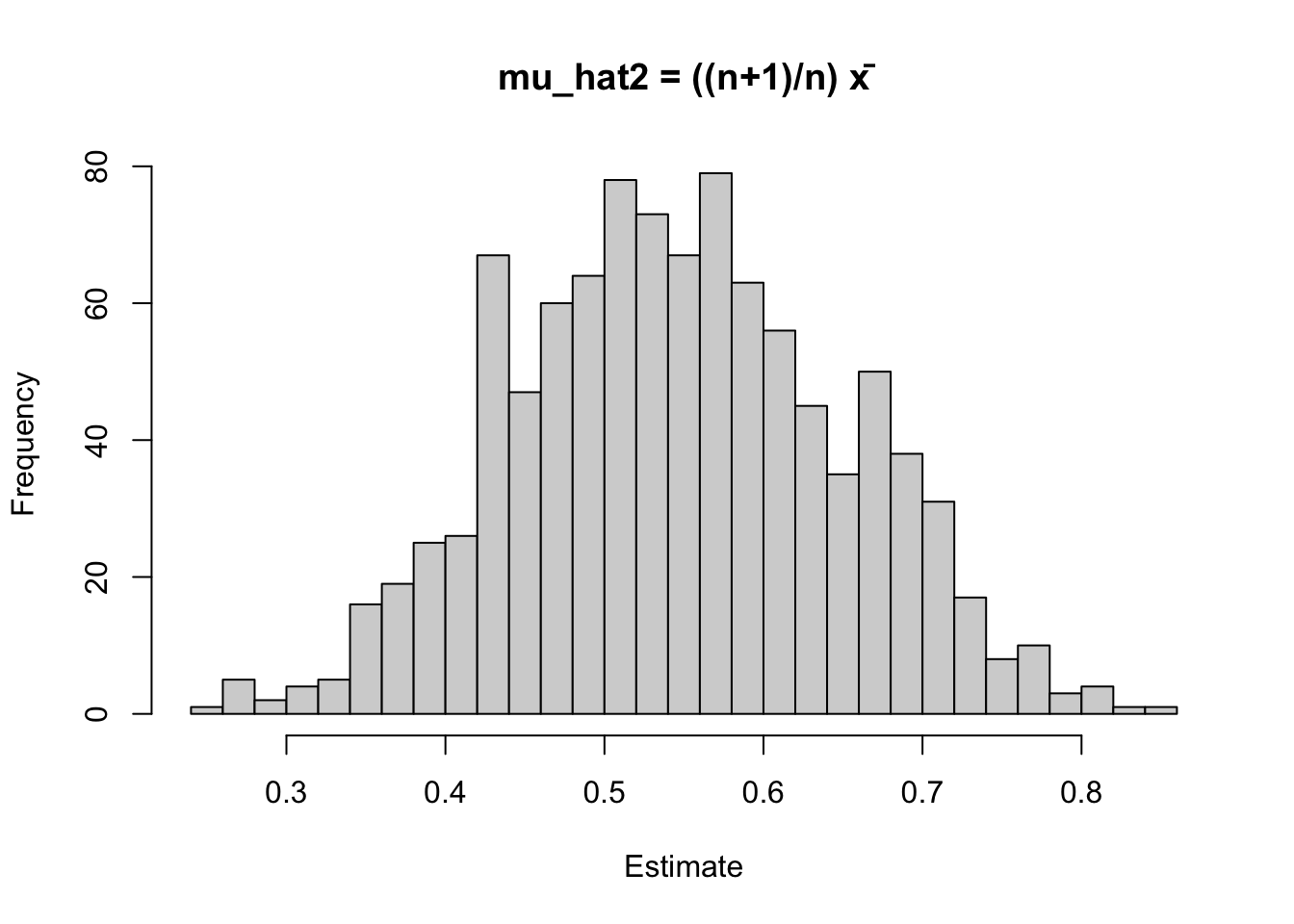
Suppose \(X_i \sim \text{Bernoulli}(p)\).
Questions:
B <- 1000
n <- 50
p <- 0.3
p_hat <- replicate(B, mean(rbinom(n, size = 1, prob = p)))
hist(p_hat, breaks = 30,
main = "Sampling distribution of p̂ (Bernoulli MLE)",
xlab = "p̂")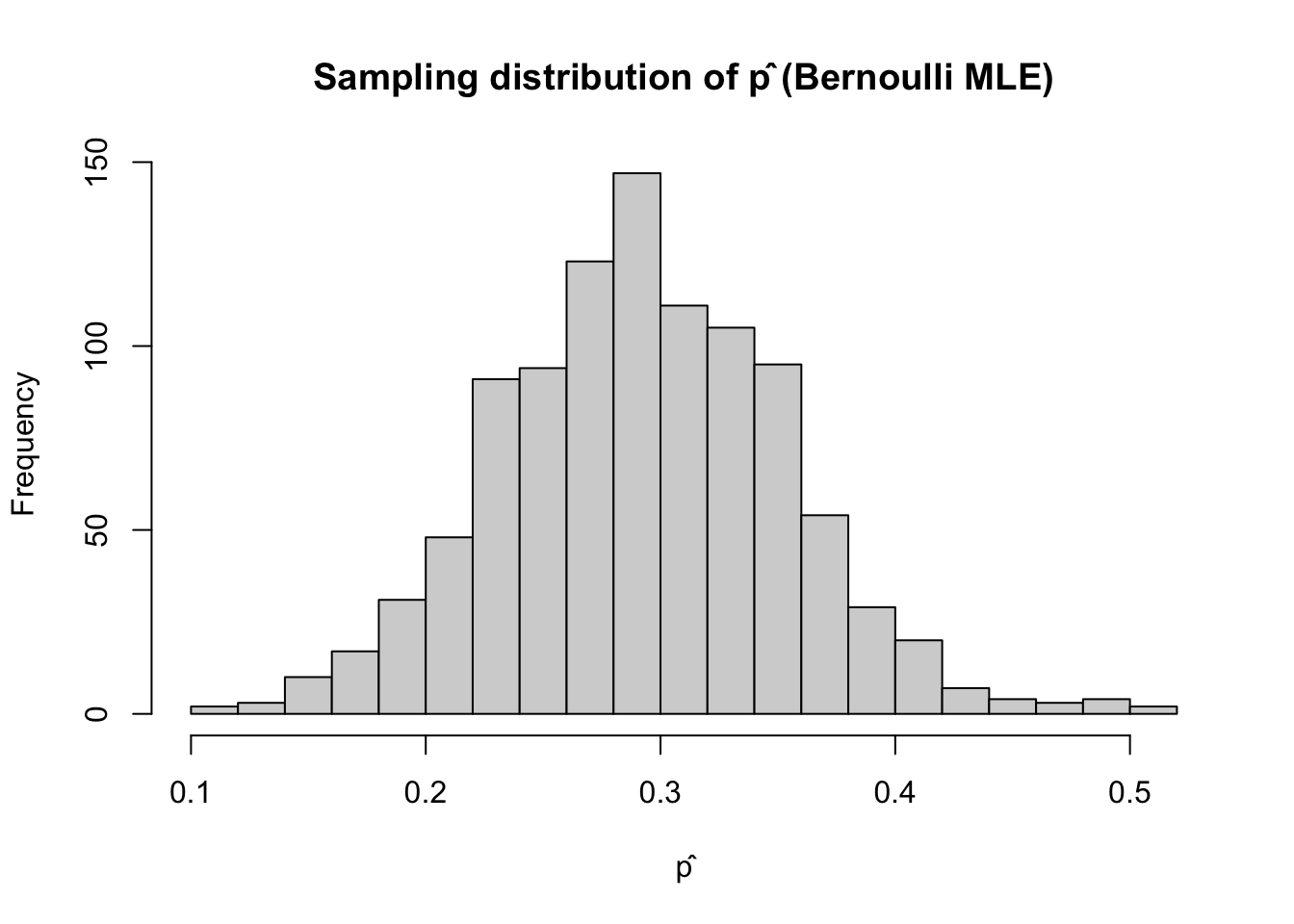
mean(p_hat) # should be close to 0.3[1] 0.30222sd(p_hat) # variability[1] 0.06168368Suppose
\[ X_i \sim N(\mu, \sigma^2), \]
where \(\sigma^2\) is known.
Questions:
\[ L(\mu) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi\sigma^2}} \exp\!\left\{-\frac{(x_i - \mu)^2}{2\sigma^2}\right\}. \]
\[ \begin{aligned} \ell(\mu) &= \log L(\mu) \\ &= \sum_{i=1}^n \left[-\frac{1}{2}\log(2\pi\sigma^2)-\frac{(x_i - \mu)^2}{2\sigma^2}\right] \\ &= -\frac{n}{2}\log(2\pi\sigma^2)-\frac{1}{2\sigma^2}\sum_{i=1}^n (x_i - \mu)^2. \end{aligned} \]
\[ \frac{\partial \ell(\mu)}{\partial \mu} = -\frac{1}{2\sigma^2} \cdot 2 \sum_{i=1}^n (x_i - \mu)(-1) = \frac{1}{\sigma^2} \sum_{i=1}^n (x_i - \mu) = 0. \]
\[ \Longrightarrow \sum_{i=1}^n x_i = n\mu \quad \Longrightarrow \quad \hat{\mu}_{\text{MLE}} = \bar{X} = \frac{1}{n}\sum_{i=1}^n X_i. \]
set.seed(123)
# Simulate
n <- 40
mu_true <- 5
sigma <- 1 # sd = 1, so variance = 1
x <- rnorm(n, mean = mu_true, sd = sigma)
# MLE for mu when sigma^2 known
mu_hat <- mean(x)
mu_hat[1] 5.045183# Repeat 1000 times and plot distribution of estimates
B <- 1000
mu_hats <- replicate(B, mean(rnorm(n, mean = mu_true, sd = sigma)))
hist(mu_hats, breaks = 30,
main = "Sampling distribution of MLE μ̂ (Normal mean), n=40",
xlab = expression(hat(mu)))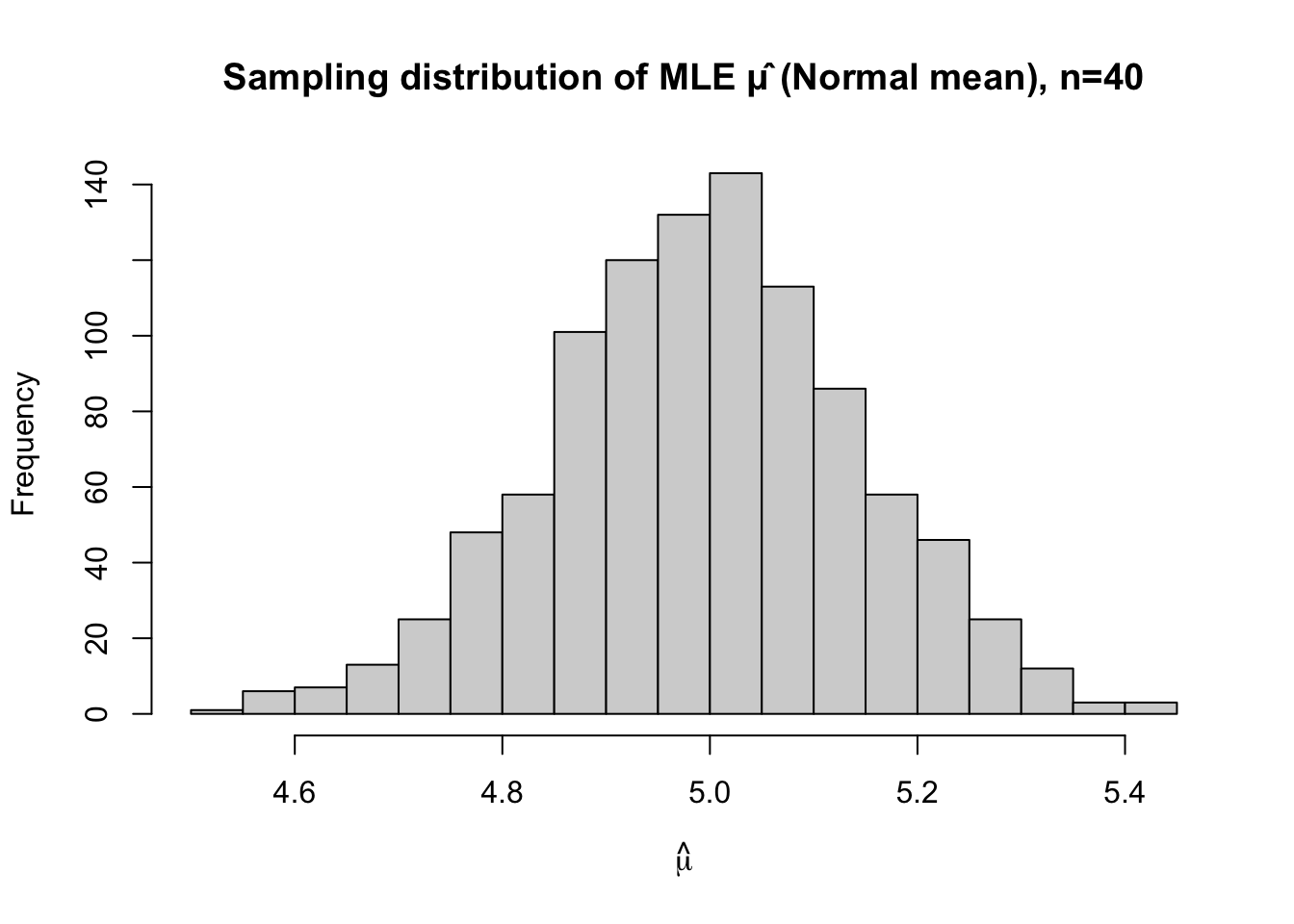
# Questions a–b
mean_est <- mean(mu_hats)
sd_est <- sd(mu_hats)
mean_est[1] 4.9942sd_est[1] 0.1489613# c. Variability vs sample size
ns <- c(40, 80, 200) # you can change / add sizes
summary_tbl <- data.frame(
n = ns,
mean_hat = NA_real_,
sd_hat = NA_real_
)
for (i in seq_along(ns)) {
n_i <- ns[i]
hats <- replicate(B, mean(rnorm(n_i, mean = mu_true, sd = sigma)))
summary_tbl$mean_hat[i] <- mean(hats)
summary_tbl$sd_hat[i] <- sd(hats)
}
summary_tbl n mean_hat sd_hat
1 40 5.008467 0.1552998
2 80 5.004284 0.1105658
3 200 5.000384 0.0698447# Optional: show how sd decreases ~ 1/sqrt(n)
plot(summary_tbl$n, summary_tbl$sd_hat,
xlab = "Sample size n", ylab = "SD of μ̂",
main = "Variability of μ̂ decreases with n")
lines(summary_tbl$n, sigma / sqrt(summary_tbl$n)) # theoretical SD of x̄ when sigma known
legend("topright", legend = c("Simulated SD", "Theoretical SD = σ/√n"),
lty = c(NA, 1), pch = c(1, NA), bty = "n")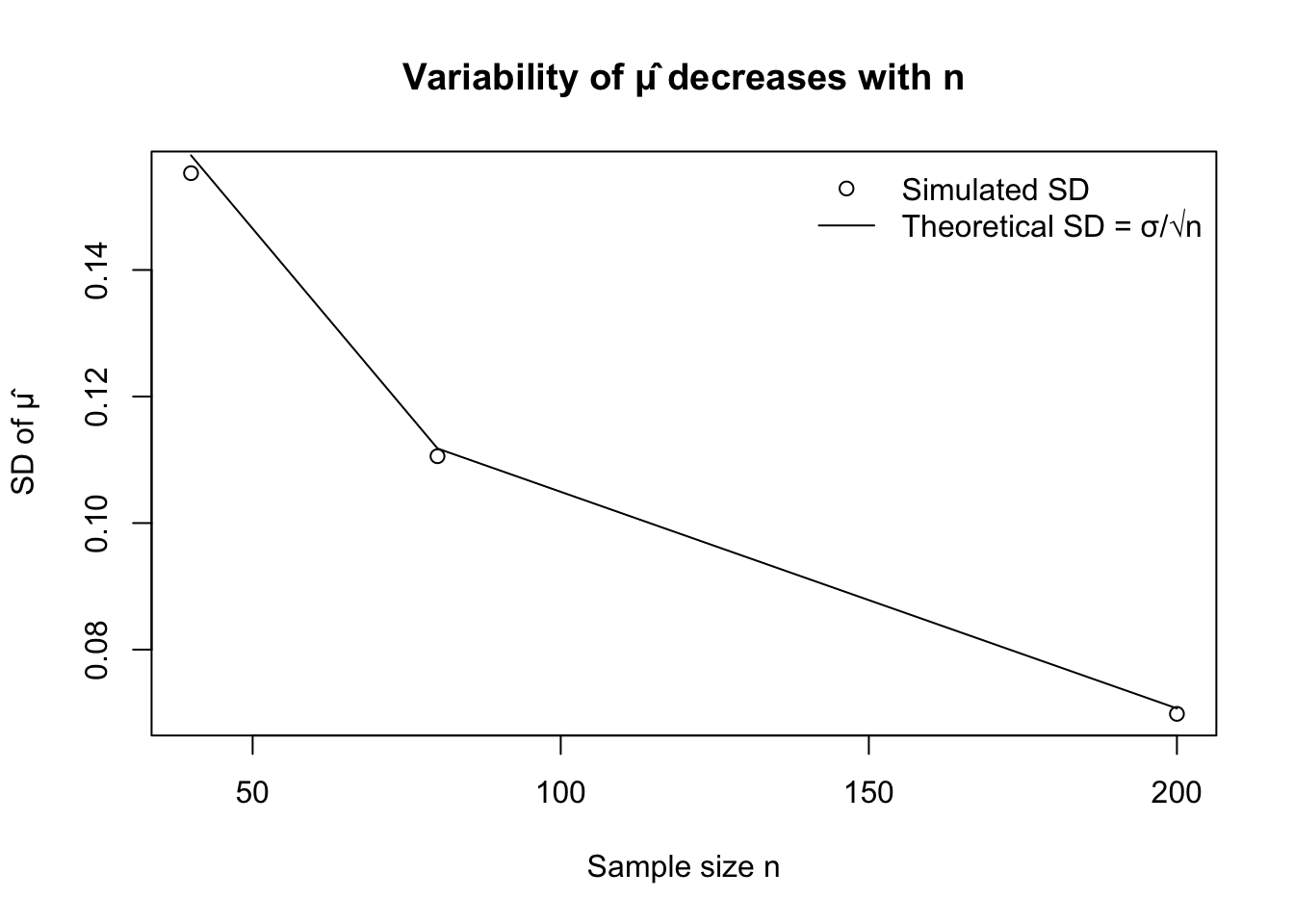
The empirical mean of the \(1000\) estimates is \[ \overline{\hat{\mu}} = \frac{1}{1000}\sum_{b=1}^{1000} \hat{\mu}^{(b)}. \] In large simulations, this will be very close to the true value \(5\).
Since the average of the simulated MLEs is close to \(5\), this suggests that \[ E[\hat{\mu}] = \mu, \]
i.e. \(\hat{\mu} = \bar{X}\) is an unbiased estimator of \(\mu\).
The variance of \(\bar{X}\) is \[ \operatorname{Var}(\bar{X}) = \frac{\sigma^2}{n}. \]
As \(n\) increases, \(\operatorname{Var}(\bar{X})\) decreases, so the sampling distribution of \(\hat{\mu}\) becomes more concentrated around \(\mu\). In simulation, this appears as a histogram that is more tightly clustered around \(5\) when \(n\) is larger (e.g. \(n=100\) vs. \(n=40\)).
Suppose the true distribution is Normal with
\[ \mu = 10, \quad \sigma = 2. \]
Questions:
Compute the proportion of intervals that contain the true mean.
set.seed(123)
# Known parameters
mu_true <- 10
sigma <- 2
n <- 40
### 1. Simulate one sample
x <- rnorm(n, mean = mu_true, sd = sigma)
### 2. Sample mean
xbar <- mean(x)
### 3. 95% confidence interval (sigma known)
z <- qnorm(0.975)
se <- sigma / sqrt(n)
CI_lower <- xbar - z * se
CI_upper <- xbar + z * se
c(CI_lower, CI_upper)[1] 9.470572 10.710162### a. Does the interval contain the true mean?
contains_mu <- (mu_true >= CI_lower) & (mu_true <= CI_upper)
contains_mu[1] TRUE### b. Repetition for 1000 simulations
B <- 1000
contains <- logical(B)
for (b in 1:B) {
x <- rnorm(n, mean = mu_true, sd = sigma)
xbar <- mean(x)
CI_lower <- xbar - z * se
CI_upper <- xbar + z * se
contains[b] <- (mu_true >= CI_lower) & (mu_true <= CI_upper)
}
### (b)–(c) Proportion of intervals containing the true mean
prop_contains <- mean(contains)
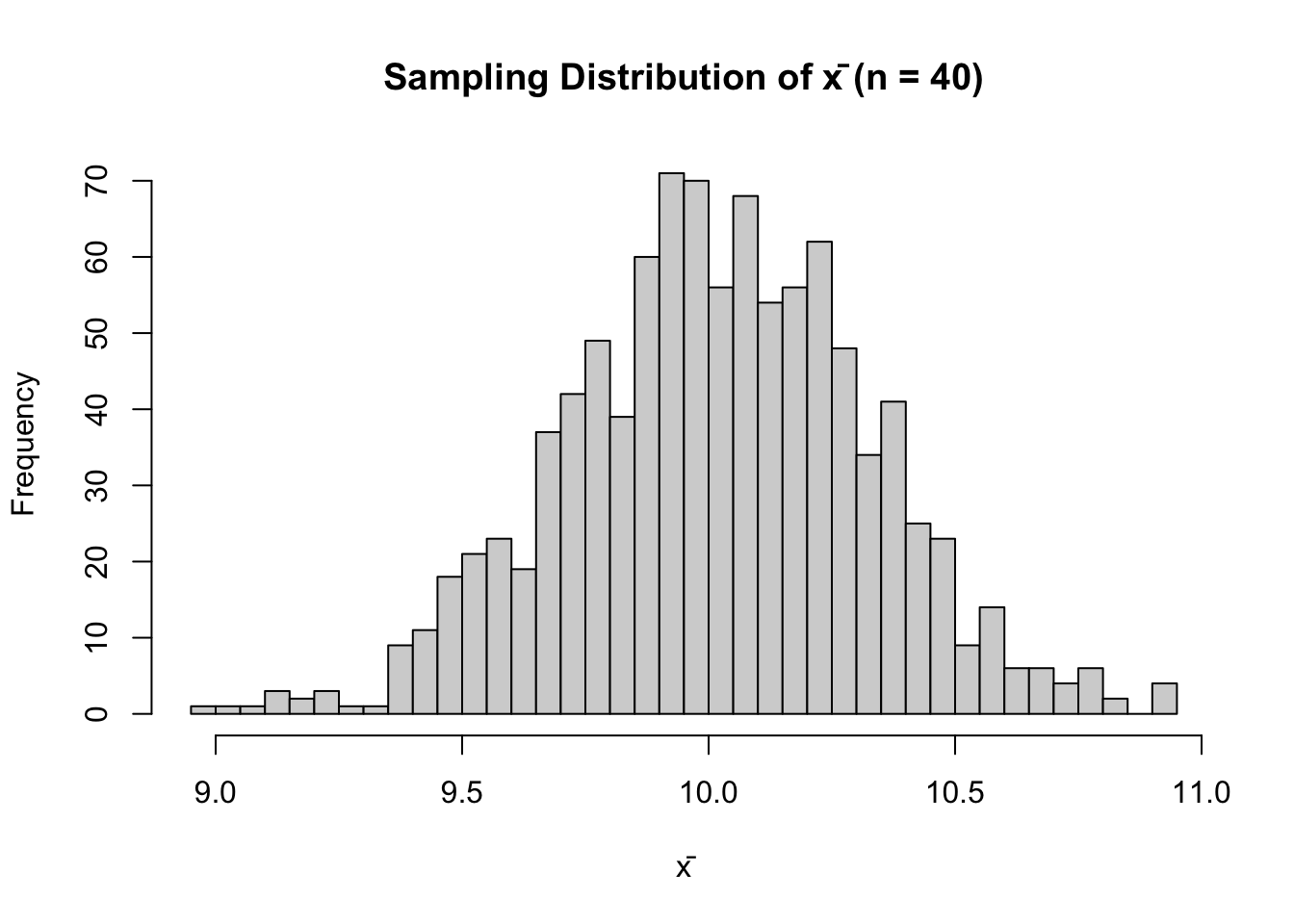
prop_contains # should be close to 0.95[1] 0.962### Optional: visualise sampling variability of xbar
hist(
replicate(B, mean(rnorm(n, mu_true, sigma))),
breaks = 30,
main = "Sampling Distribution of x̄ (n = 40)",
xlab = "x̄"
)
Suppose a test is 95% accurate when a disease is present and 97% accurate when the disease is absent. Suppose that 1% of the population has the disease. Let \(H\) be the event that a disease is present, \(T^+\) be the event of positive test result, and \(T^-\) be the event of negative test result.
flowchart LR
A[Start] --> B{H: Disease?}
B -->|Yes 1%| C[H]
B -->|No 99%| D[∼H]
C -->|Test Positive 95%| E[T+ ∣ H]
C -->|Test Negative 5%| F[T- ∣ H]
D -->|Test Positive 3%| G[T+ ∣ ∼H]
D -->|Test Negative 97%| K[T- ∣ ∼H]
linkStyle default stroke:#000,stroke-width:2px
\[ \begin{array}{c|cc} P(T? \mid ?H) & H & \neg H \\ \hline T+ & 95\% & 3\% \\ T- & 5\% & 97\% \\ \hline & 1\% & 99\% \end{array} \]
Bayes’ rule:
\[ P(H \mid T^+) = \frac{P(T^+ \mid H)P(H)} {P(T^+ \mid H)P(H) + P(T^+ \mid \neg H)P(\neg H)} \]
Plug in values:
\[ P(H \mid T^+) = \frac{0.95 \cdot 0.01} {0.95 \cdot 0.01 + 0.03 \cdot 0.99} \]
Compute numerator and denominator:
\[ P(H \mid T^+) = \frac{0.0095}{0.0392} \approx 0.242 \]
True positive probability ≈ 24.2%
Even with a “good” test, the disease is rare, so most positives are false positives.
\[ P(\neg H \mid T^+) = 1 - P(H \mid T^+) \]
\[ = 1 - 0.242 = 0.758 \]
False positive probability ≈ 75.8%
Bayes’ rule again:
\[ P(\neg H \mid T^-) = \frac{P(T^- \mid \neg H)P(\neg H)} {P(T^- \mid \neg H)P(\neg H) + P(T^- \mid H)P(H)} \]
\[ = \frac{0.97 \cdot 0.99} {0.97 \cdot 0.99 + 0.05 \cdot 0.01} \]
Compute:
\[ P(\neg H \mid T^-) \approx \frac{0.9603}{0.9608} \approx 0.9995 \]
True negative probability ≈ 99.95%
\[ P(H \mid T^-) = 1 - P(\neg H \mid T^-) \]
\[ = 1 - 0.9995 = 0.0005 \]
False negative probability ≈ 0.05%
(Albert et al., 2009, Chapter 4, Exercise 4.4)
A woman tells you she can predict the sex of a baby by how high it ‘rides’ in the mothers uterus. ‘High’ means a boy and ‘low’ means a girl. You suspect she is only guessing, but you are not completely sure;
x <- matrix(0,nrow=2, ncol=7)
x[1, ] <- c('Success rate p',0,0.25,0.5,0.75,0.9,1)
x[2, ] <- c('Pr(p) prior',0,0.1,0.75,0.1,0.04,0.01)
library(knitr)
kable(x)| Success rate p | 0 | 0.25 | 0.5 | 0.75 | 0.9 | 1 |
| Pr(p) prior | 0 | 0.1 | 0.75 | 0.1 | 0.04 | 0.01 |
This is a discrete prior with the following pmf \(Pr(p)\):
plot(x[1,2:7], x[2,2:7], xlab="p", ylab="prior")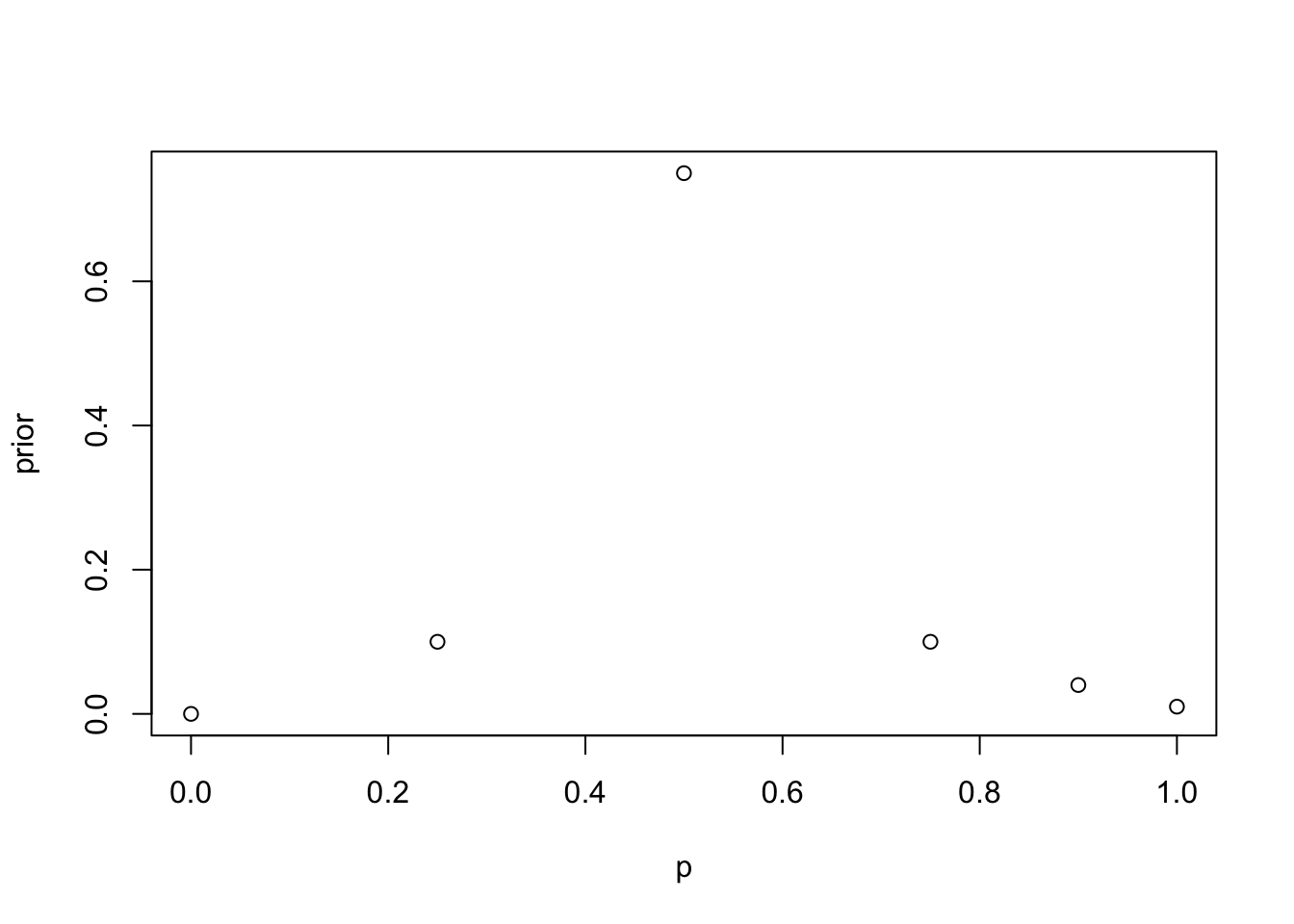
This is Binomial data (likelihood):
\[ X \mid p \sim \text{Binomial}(n=10, p) \]
\[ f(X \mid p) = {10\choose X} p^X (1-p)^{10-X} \]
The woman is correct 7 times out of 10 \(\rightarrow X = 7\).
\[ f(X \mid p) = {10\choose 7} p^7 (1-p)^{3} \]
Product:
\[ f(p \mid X) = Pr(p) \times f(X \mid p) \]
Normalising above gives the posterior:
p <- c(0,0.25,0.5,0.75,0.9,1)
prior <- c(0,0.1,0.75,0.1,0.04,0.01)
likelihood <- dbinom(7,10,p)
product <- prior * likelihood
posterior <- product / sum(product) # normalise
x <- matrix(0, nrow=4, ncol=7)
x[1, ] <- c('Success rate p',0,0.25,0.5,0.75,0.9,1)
x[2, ] <- c('Pr(p) prior',0,0.1,0.75,0.1,0.04,0.01)
x[3, ] <- c('Product', round(product,5))
x[4, ] <- c('Posterior', round(posterior,5))
library(knitr)
kable(x)| Success rate p | 0 | 0.25 | 0.5 | 0.75 | 0.9 | 1 |
| Pr(p) prior | 0 | 0.1 | 0.75 | 0.1 | 0.04 | 0.01 |
| Product | 0 | 0.00031 | 0.08789 | 0.02503 | 0.0023 | 0 |
| Posterior | 0 | 0.00267 | 0.7608 | 0.21665 | 0.01987 | 0 |
par(mfrow = c(3,1), mar=c(2,4,1,1))
plot(p,prior,type='l')
plot(p,likelihood,type='l', col=2)
plot(p,posterior,type='l', col=3)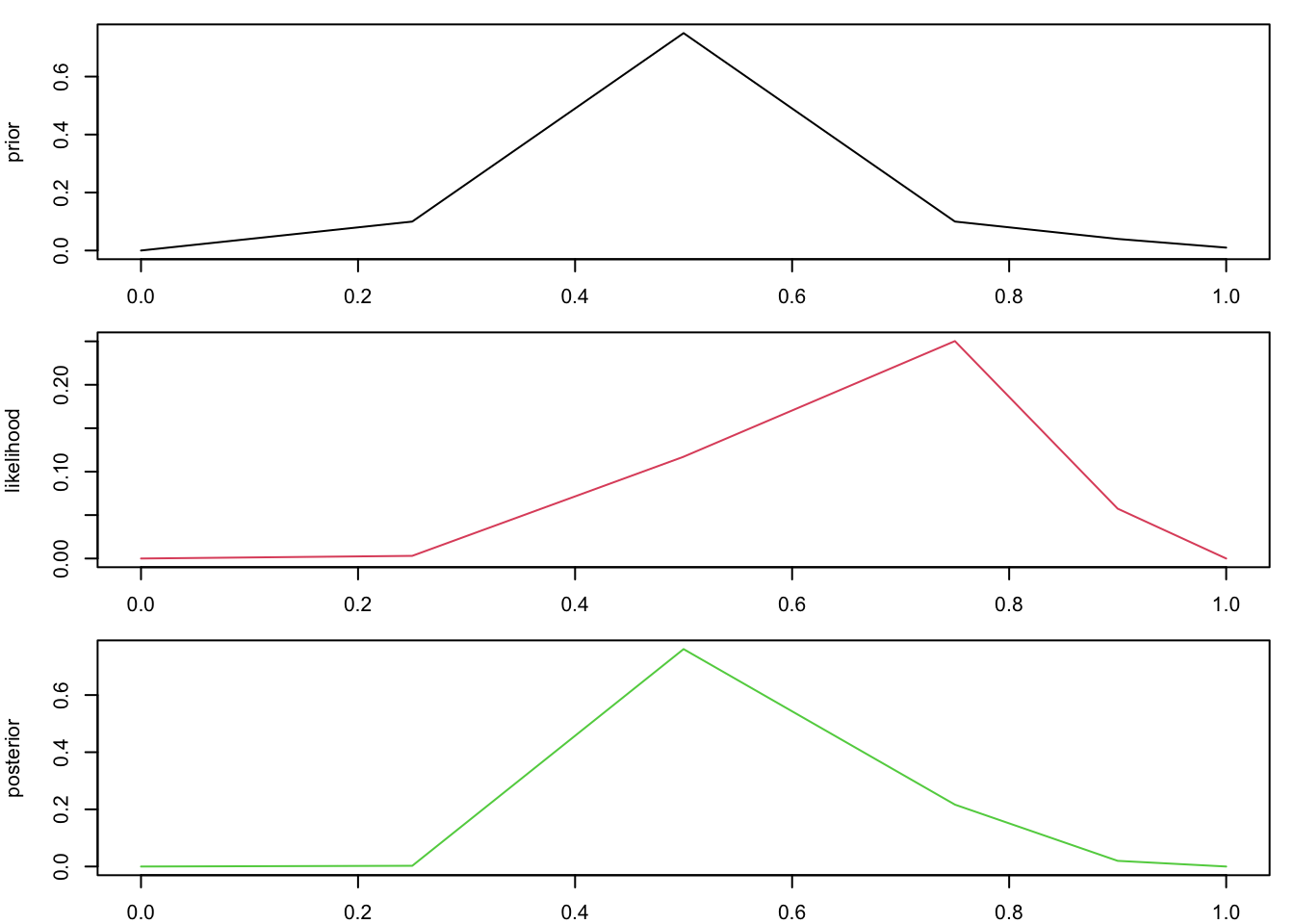
For a Binomial mode, the MLE is \[ \hat{p}_{\text{MLE}} = \frac{X}{n} = \frac{7}{10} = 0.7. \]
A 95% confidence interval is
\[ \hat{p} \pm 1.96 \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \approx 0.7 \pm 0.28, \]
so roughly (0.42, 0.98).
Let’s define
From the posterior:
\[ Pr(p=0.5 \mid X) \approx 0.7608 \]
\[ Pr(p>0.5 \mid X) \approx 0.2167 + 0.0199 \approx 0.2366 \]
The data nudges you toward “maybe some skill,” but your prior belief that she’s guessing still dominates.
p <- c(0,0.25,0.5,0.75,0.9,1)
prior1 <- rep(1/6, 6) # 1/6 for each
likelihood <- dbinom(7,10,p)
posterior <- (prior1 * likelihood) / sum(prior1 * likelihood)
x1 <- matrix(0,nrow=4, ncol=7)
x1[1, ] <- c('Success rate p', p)
x1[2, ] <- c('Pr(p) prior', round(prior1, 4))
x1[3, ] <- c('Likelihood', round(likelihood, 4))
x1[4, ] <- c('Posterior', round(posterior, 4))
kable(x1)| Success rate p | 0 | 0.25 | 0.5 | 0.75 | 0.9 | 1 |
| Pr(p) prior | 0.1667 | 0.1667 | 0.1667 | 0.1667 | 0.1667 | 0.1667 |
| Likelihood | 0 | 0.0031 | 0.1172 | 0.2503 | 0.0574 | 0 |
| Posterior | 0 | 0.0072 | 0.2738 | 0.5848 | 0.1341 | 0 |
\[ Pr(p=0.5 \mid X) \approx 0.2738 \]
\[ Pr(p>0.5 \mid X) \approx 0.5848 + 0.1341 \approx 0.7189 \]
With a flat prior, the same data makes “some skill” the more plausible story.
Same likelihood, different priors → different posterior stories.
Suppose the number of customers arriving at a service desk in one hour follows a Poisson distribution with unknown rate \(\lambda\):
\[ X_i \sim \text{Poisson}(\lambda), \quad i = 1, \dots, n. \]
A prior distribution is placed on \(\lambda\):
\[ \lambda \sim \text{Gamma}(\alpha, \beta), \]
where \(\alpha > 0\) and \(\beta > 0\).
Assume the prior parameters are
\[ \alpha = 3, \qquad \beta = 1. \]
During five observed hours, the number of arriving customers is recorded as
\[ 8,\; 6,\; 7,\; 9,\; 10. \]
Questions:
Hint:
For the Gamma distribution parameterised as \(\text{Gamma}(\alpha, \beta)\) with shape \(\alpha\) and rate \(\beta\): \[ E[\lambda] = \frac{\alpha}{\beta}. \]
For the Gamma–Poisson conjugate model, the posterior parameters are
\[ \alpha_{\text{post}} = \alpha + \sum x_i, \]
\[ \beta_{\text{post}} = \beta + n. \]
Given data \(x_1, \dots, x_n\) with \(x_i \sim \text{Poisson}(\lambda)\) independently, the likelihood is
\[
L(\lambda \mid x_1,\dots,x_n)
= \prod_{i=1}^n \frac{e^{-\lambda}\lambda^{x_i}}{x_i!}
= e^{-n\lambda}\lambda^{\sum_{i=1}^n x_i} \prod_{i=1}^n \frac{1}{x_i!}.
\]
For the specific data \(8,6,7,9,10\) with \(n=5\) and \(\sum x_i = 40\), \[ L(\lambda \mid \mathbf{x}) \propto e^{-5\lambda}\lambda^{40}. \]
Prior: \(\lambda \sim \text{Gamma}(\alpha,\beta)\) with \(\alpha=3\), \(\beta=1\).
Using conjugacy: \[ \alpha_{\text{post}} = \alpha + \sum x_i = 3 + 40 = 43, \] \[ \beta_{\text{post}} = \beta + n = 1 + 5 = 6. \]
So the posterior is \[ \lambda \mid \mathbf{x} \sim \text{Gamma}(43, 6). \]
For \(\lambda \sim \text{Gamma}(\alpha_{\text{post}}, \beta_{\text{post}})\), \[ E[\lambda \mid \mathbf{x}] = \frac{\alpha_{\text{post}}}{\beta_{\text{post}}} = \frac{43}{6} \approx 7.1667. \]
For Poisson data, the MLE is the sample mean: \[ \hat{\lambda}_{\text{MLE}} = \bar{x} = \frac{8+6+7+9+10}{5} = \frac{40}{5} = 8. \]
Comparison:
The posterior mean is shrunk toward the prior mean
\[
E[\lambda] = \frac{\alpha}{\beta} = \frac{3}{1} = 3,
\] reflecting prior information plus data, whereas the MLE uses only the data.
Posterior: \(\lambda \mid \mathbf{x} \sim \text{Gamma}(43, 6)\).
A 95% credible interval is given by the 2.5% and 97.5% quantiles:
alpha_post <- 43
beta_post <- 6
# Posterior mean
post_mean <- alpha_post / beta_post
post_mean[1] 7.166667# 95% credible interval
ci_lower <- qgamma(0.025, shape = alpha_post, rate = beta_post)
ci_upper <- qgamma(0.975, shape = alpha_post, rate = beta_post)
c(ci_lower, ci_upper)[1] 5.186552 9.461966This returns a 95% credible interval of the form
\[
[\lambda_{0.025},\; \lambda_{0.975}] = [5.1866, 9.4620].
\]
\[ L(\theta) = L(\theta \mid x_1, x_2, \dots, x_n) = f(x_1, x_2, \dots, x_n \mid \theta) \]
is the likelihood function.
In the following questions you are asked to specify the likelihood functions for given scenarios.
\[ L(\theta) = {100 \choose 55}\theta^55 (1-\theta)^{100-55} \]
\[ \begin{aligned} L(\theta \mid 1,3,2) &= \frac{6!}{1!\,3!\,2!}\,\theta^{1}\theta^{3}(1-2\theta)^{2} \\ &= \frac{6!}{1!\,3!\,2!}\,\theta^{4}(1-2\theta)^{2} \\ &\propto \theta^{4}(1-2\theta)^{2} \end{aligned} \]
\[ \begin{aligned} L(\theta \mid 2,2,2) &= \frac{6!}{2!\,2!\,2!}\,\theta^{2}\theta^{2}(1-2\theta)^{2} \\ &= \frac{6!}{2!\,2!\,2!}\,\theta^{4}(1-2\theta)^{2} \\ &\propto \theta^{4}(1-2\theta)^{2} \end{aligned} \]
Both have the same mathematical form.
\[ f_X(x) = \frac{x^2}{2\theta^3} e^{-x/\theta}, \qquad 0 < x < \infty, \quad \theta > 0 \]
Let \(x_1, x_2, \dots, x_n\) be a random sample of \(n\) claim sizes for such claims. Specify the likelihood function and the log-likelihood function.
\[ \begin{aligned} L(\theta) &= \prod_{i=1}^{n} f_X(x_i) \\ &= \prod_{i=1}^{n} \frac{x_i^2}{2\theta^3} \exp\!\left(-\frac{x_i}{\theta}\right) \\ &= \left( \frac{x_1^2}{2\theta^3} e^{-x_1/\theta} \right) \left( \frac{x_2^2}{2\theta^3} e^{-x_2/\theta} \right) \cdots \left( \frac{x_n^2}{2\theta^3} e^{-x_n/\theta} \right) \\ &= \frac{\displaystyle \prod_{i=1}^{n} x_i^2 \; \exp\!\left( -\sum_{i=1}^{n} \frac{x_i}{\theta} \right)} {2^n \theta^{3n}} \end{aligned} \]
\[ \begin{aligned} \ln(L(\theta)) &= \ln\!\left( \frac{\prod_{i=1}^{n} x_i^{2}\, e^{-\sum_{i=1}^{n} x_i/\theta}} {2^{n}\theta^{3n}} \right) \\[6pt] &= \ln\!\left(\prod_{i=1}^{n} x_i^{2} e^{-\sum_{i=1}^{n} x_i/\theta}\right) - \ln(2^{n}\theta^{3n}) \\[6pt] &= \sum_{i=1}^{n} \ln(x_i^{2}) - \sum_{i=1}^{n} \frac{x_i}{\theta} - n\ln(2) - 3n\ln(\theta) \\[6pt] &\propto -\sum_{i=1}^{n} \frac{x_i}{\theta} - 3n\ln(\theta) \end{aligned} \]
\[ \begin{aligned} l(p) &= k\, p^{x}(1-p)^{\,n-x} \\[6pt] \frac{\partial l(p)}{\partial p} &= \frac{x}{p} - \frac{n-x}{1-p} \\[6pt] \frac{\partial^{2} l(p)}{\partial p^{2}} &= \frac{x}{p^{2}} - \frac{n-x}{(1-p)^{2}} < 0 \\[6pt] \hat{p} &= \frac{x}{n} \end{aligned} \]
\[ \begin{aligned} \pi(p) &\propto p^{x}(1-p)^{\,n-x}\, p^{\alpha-1}(1-p)^{\beta-1} \\[6pt] &\propto p^{\,x+\alpha-1}(1-p)^{\,n-x+\beta-1} \\[6pt] &\sim \mathrm{Beta}(x+\alpha,\; n-x+\beta) \\[6pt] &\sim \mathrm{Beta}(x+\alpha,\; 1000-x+\beta) \end{aligned} \]
\[ \begin{aligned} \hat{p} &= \mathbb{E}[p \mid x] = \frac{x+\alpha}{n+\alpha+\beta} = \frac{x+\alpha}{1000+\alpha+\beta} \end{aligned} \]
Conjugate prior, same form of prior and posterior distribution.
The two estimators are the same.
While travelling through the Mushroom Kingdom, Mario and Luigi find some rather unusual coins. They agree on a prior of \(f(\theta) \sim \text{Beta}(5,5)\) for the probability of heads, though they disagree on what experiment to run to investigate \(\theta\) further.
Show that Mario and Luigi will arrive at the same posterior on \(\theta\), and calculate this posterior.
Mario
Prior is Beta(5,5):
\[ f(\theta) = \frac{\theta^4(1-\theta)^4}{B(5,5)} \]
Likelihood is Binomial(5, \(\theta\)):
\[ f(X \mid \theta) = {5 \choose 4}\theta^4(1-\theta)^1 \]
Posterior:
\[ \begin{aligned} f(\theta \mid X) &\propto \theta^8 (1-\theta)^5 \\ &\propto \theta^{9-1} (1-\theta)^{6-1} \\ &\sim \text{Beta}(9,6). \end{aligned} \]
Luigi
Prior is Beta(5,5):
\[ f(\theta) = \frac{\theta^4(1-\theta)^4}{B(5,5)} \]
Likelihood is Geometric(\(\theta\)):
\[ f(X \mid \theta) = \theta^4(1-\theta)^1 \]
Posterior:
\[ \begin{aligned} f(\theta \mid X) &\propto \theta^8 (1-\theta)^5 \\ &\propto \theta^{9-1} (1-\theta)^{6-1} \\ &\sim \text{Beta}(9,6). \end{aligned} \]
Both arrive at the same pposterior Beta(9, 5).