A mobile game awards players with different types of rewards when a treasure chest is opened. The reward type follows the probability distribution below.
Reward Type \(x\)
Coins
Gems
Energy
Rare Item
\(P(X=x)\)
0.50
0.25
0.15
0.10
Construct the cumulative distribution function (CDF) for this random variable and present it in a table.
import numpy as npimport pandas as pd# Define outcomes and probabilitiesx = np.array(["Coins", "Gems", "Energy", "Rare Item"])p = np.array([0.50, 0.25, 0.15, 0.10])# Check probabilities sum to 1p.sum()# Construct cumulative probabilitiesF = np.cumsum(p)# Create table for PMF and CDFpd.DataFrame({"outcome": x,"p": p,"F": F})
outcome
p
F
0
Coins
0.50
0.50
1
Gems
0.25
0.75
2
Energy
0.15
0.90
3
Rare Item
0.10
1.00
Intervals for the precision method
From the cumulative probabilities,
Coins: \(0 < U \le 0.50\)
Gems: \(0.50 < U \le 0.75\)
Energy: 0\(.75 < U \le 0.90\)
Rare Item: \(0.90 < U \le 1.00\)
So the rule is
\[
X =
\begin{cases}
\text{Coins} & \text{if } 0 < U \le 0.50 \\
\text{Gems} & \text{if } 0.50 < U \le 0.75 \\
\text{Energy} & \text{if } 0.75 < U \le 0.90 \\
\text{Rare Item} & \text{if } 0.90 < U \le 1.00
\end{cases}
\]
# Show intervals in a tablelower = np.concatenate(([0], F[:-1])) # F[:-1] excludes the last item in Fupper = Fpd.DataFrame({"outcome": x,"lower": lower,"upper": upper})
outcome
lower
upper
0
Coins
0.00
0.50
1
Gems
0.50
0.75
2
Energy
0.75
0.90
3
Rare Item
0.90
1.00
Classify the given random numbers
u_given = np.array([0.12, 0.63, 0.44, 0.91, 0.27])# Find the first cumulative probability >= uresult_given = np.array([x[np.where(u <= F)[0][0]] for u in u_given])pd.DataFrame({"u": u_given,"reward": result_given})
u
reward
0
0.12
Coins
1
0.63
Gems
2
0.44
Coins
3
0.91
Rare Item
4
0.27
Coins
for u in u_given applies the rule to each random number
u <= F checks which cumulative probabilities are at least as large as u
np.where(u <= F)[0] returns the indices where this is true
[0] takes the first such index
Equivalently:
def find_outcome(u): i = np.where(u <= F)[0][0]return x[i]result_given = np.array([find_outcome(u) for u in u_given])pd.DataFrame({"u": u_given,"reward": result_given})
u
reward
0
0.12
Coins
1
0.63
Gems
2
0.44
Coins
3
0.91
Rare Item
4
0.27
Coins
R function to simulate one reward
def simulate_reward(): u = np.random.uniform(0, 1)return x[np.where(u <= F)[0][0]]# Example: simulate 20 rewardsnp.random.seed(123)np.array([simulate_reward() for _ inrange(20)])
The empirical probabilities should be close to the theoretical probabilities, though not exactly equal, because the simulation uses a finite number of draws. With 10,000 replications, the discrepancies are usually small.
Why can the precision method be inefficient for large k?
A simple implementation checks the cumulative probabilities one by one until it finds the correct interval. When the number of outcomes k is large, this search can become slow, especially if repeated many times. More efficient methods or built-in algorithms are often preferred for large discrete distributions.
Optional: more compact R version using np.searchsorted()
def simulate_reward2(n=1): u = np.random.uniform(0, 1, size=n) idx = np.searchsorted(F, u, side="left")return x[idx]np.random.seed(123)simulate_reward2(10)# 10,000 simulated rewardssamples2 = simulate_reward2(10000)pd.Series(samples2).value_counts(normalize=True).reindex(x)
One small note: np.searchsorted() finds the insertion position of each value in the cumulative probability array, which corresponds exactly to the first index where \(F_i \ge u\). This makes it a compact Python version of the precision method.
Note
The precision method is essentially the discrete version of the inverse CDF method.
Exercise 2: Load on a bridge (CD 2014)
Consider the pdf for the random variable \(X\) which is the magnitude (in newtons) of a dynamic load on a bridge, given as
\[
f(x)= \left(\frac{1}{8} + \frac{3}{8} x \right), \quad 0 \le x \le 2
\]
Write a program to simulate values from this distribution using the inverse cdf method. Calculate the mean and variance and compare with the exact results.
Step 1. Firstly, we need to find the cdf \(F(x).\)\[
\begin{aligned}
F(x) &= \int_0^x f(t)\, dt \\
&= \int_0^x \left(\frac{1}{8} + \frac{3}{8} t \right)\,dt \\
F(x) &= \frac{x}{8} + \frac{3x^2}{16}
\end{aligned}
\]
Step 3. Simulate \(f(x)\) from \(U \sim \text{Uniform}(0,1)\)
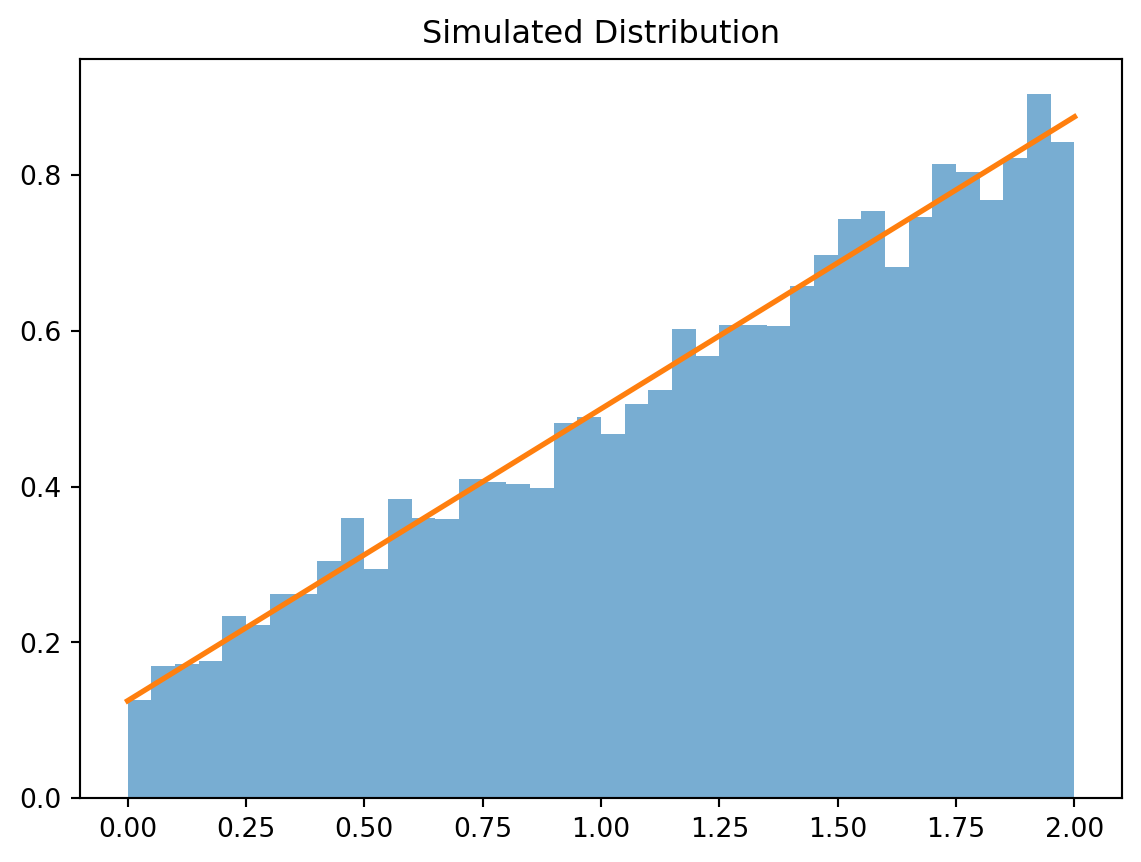
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(1234)u = np.random.rand(10000)# Inverse CDFx = (-1+ np.sqrt(1+48*u)) /3# Histogramplt.hist(x, bins=40, density=True, alpha=0.6)# Overlay true pdft = np.linspace(0, 2, 200)pdf =1/8+3*t/8plt.plot(t, pdf, linewidth=2)plt.title("Simulated Distribution")plt.show()# Compare mean and varianceprint("Theoretical mean =", EX, ", Empirical mean =", np.mean(x))print("Theoretical variance =", VarX, ", Empirical variance =", np.var(x, ddof=1))
Theoretical mean = 5/4 , Empirical mean = 1.2491798412911999
Theoretical variance = 13/48 , Empirical variance = 0.27390211327069786
The simulated distribution closely matches the theoretical probability density function, as shown by the histogram and overlaid curve Additionally, the empirical mean and variance from the simulated data are very close to the exact values \(E(X)=\frac{5}{4}\) and \(\mathrm{Var}(X)=\frac{13}{48}\), confirming that the simulation is accurate.
Exercise 3: Simulating the distribution of waiting time - Transportation
The article “A Model of Pedestrians’ Waiting Times for Street Crossings at Signalised Intersections” (Transportation Research, 2013: 17–28) suggested that under some circumstances the distribution of waiting time \(X\) could be modeled with the following pdf:
Write a function to simulate values from this distribution, implementing the inverse cdf method. Your function should have three inputs: the desired number of simulated values \(n\) and values for the two parameters for \(\theta\) and \(\tau.\)
Step 3. Write a function that accepts 3 inputs: \(n,\theta,\tau\)
def waittime(n, theta, tau): u = np.random.rand(n) x = tau * (1- (1- u)**(1/theta))return x
Use your function in part (a) to simulate 10,000 values from this wait time distribution with \(\theta=4\) and \(\tau=80.\) Estimate \(E(X)\) under these parameter settings.
How close is your estimate to the correct value of the exact \(E(X)=16\) and \(\mathrm{Var}(X)=170.67\)?
The empirical mean and variance from the simulated data are very close to the exact mean and variance, confirming that the simulation is accurate.
Part 2: Acceptance-Rejection Sampling
Exercise 4: Simulating Beta(2,2) distribution using Uniform distribution (Templ 2016)
Describe the steps. Hints: The pdf of \(Beta(\alpha,\beta)\) is \[
f(x)= \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} x^{\alpha-1}(1-x)^{\beta-1}, \quad 0 \le x \le 1
\]
The aim is to simulate \(n\) values from a Beta(2,2) distribution with pdf such that by substituting \(\alpha=2, \beta=2\) in the above, we have \[
f(x)= 6x(1-x), \quad 0 \le x \le 1.
\]
Let \(g(x)\) be Uniform(0,1) such that \[
g(x)= 1, \quad 0 \le x \le 1.
\]
and the ratio \(f/g\) is bounded, i.e., there exists a constant \(M\) such that \[
\frac{f(x)}{g(x)} = 6x(1-x) \le M, \quad \forall x.
\]
\[
\frac{d}{dx}6x(1-x) = 6 - 12x = 0
\]
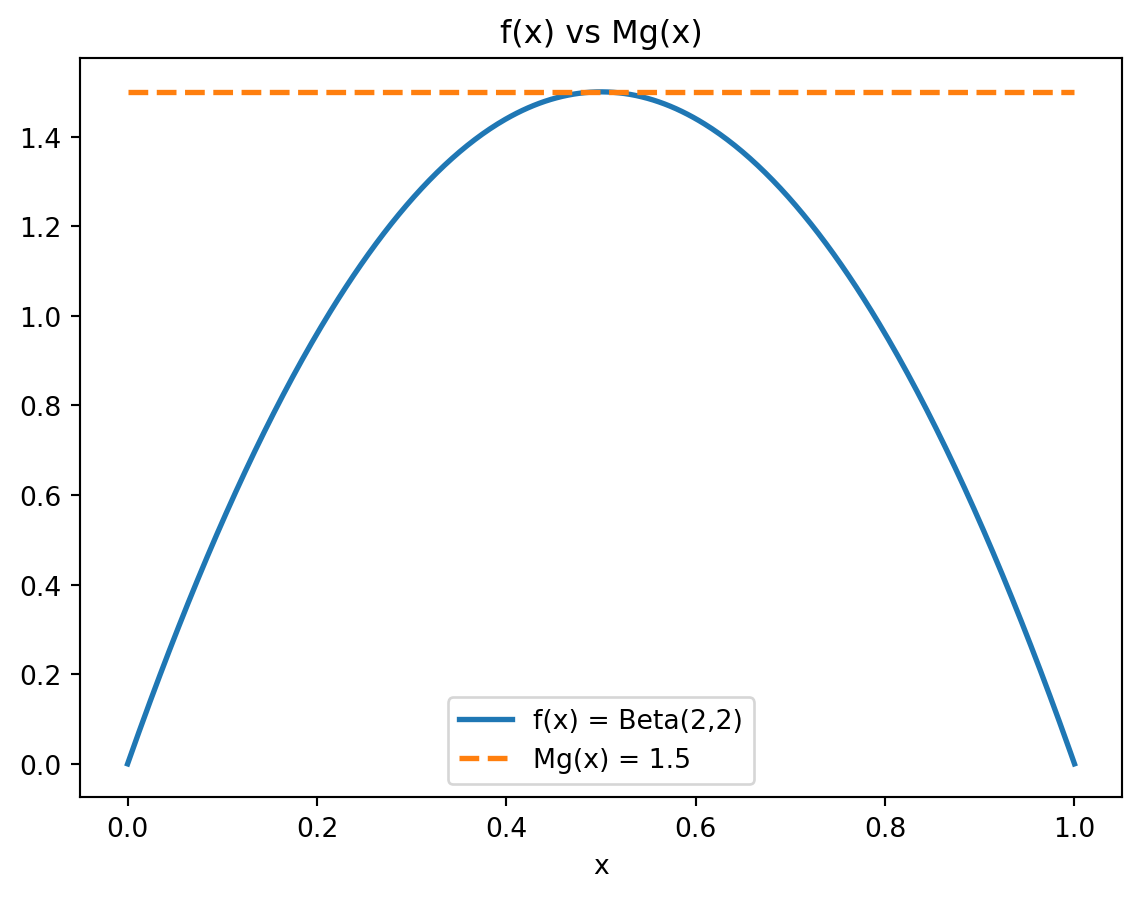
In this case, the function is maximised at \(x=0.5, f(x)=1.5\) so that we choose \(M = 1.5.\)
Therefore, the general rule is
\[
U \leq \frac{f(Y)}{Mg(Y)} = \frac{6y(1-y)}{1.5(1)} = 4y(1-y)
\]
Proceed as follows:
Generate \(Y \sim g \sim \text{Uniform}(0,1).\)
Generate a standard uniform variate, \(U \sim \text{Uniform}(0,1).\)
If \(u\le 4y(1-y),\) then assign \(x=y\) (i.e., “accept” the candidate). Otherwise, discard or reject \(y\) and return to step 1.
These steps are repeated until \(n\) candidate values have been accepted.
The resulting accepted values \(x_1, . . ., x_n\) form a simulation of a random variable with the original pdf, \(f(x).\)
Check visually the plots of \(f(x)\) and \(Mg(x).\)
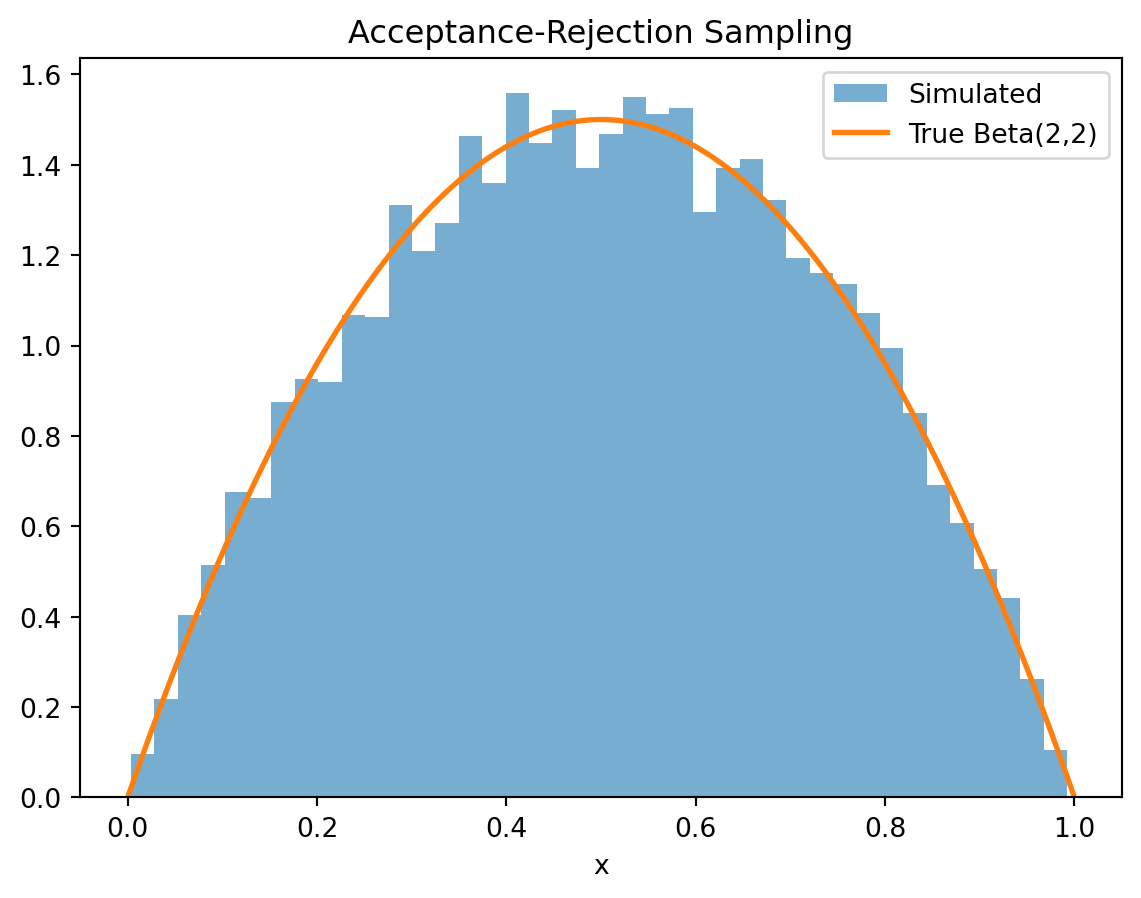
Perform Accept-Reject method to simulate Beta(2,2) distribution from Uniform distribution. Calculate the acceptance rate. Plot the simulating values of a Beta(2,2) using the accep rejection approach.
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(1234)n =10000x = []whilelen(x) < n: m = n -len(x) y = np.random.rand(m) u = np.random.rand(m) accept = u <=4* y * (1- y) x.extend(y[accept])x = np.array(x[:n])plt.hist(x, bins=40, density=True, alpha=0.6, label="Simulated")t = np.linspace(0, 1, 500)plt.plot(t, 6*t*(1-t), linewidth=2, label="True Beta(2,2)")plt.title("Acceptance-Rejection Sampling")plt.xlabel("x")plt.legend()plt.show()
Exercise 5: Simulating the half-normal distribution using Exponential
The half-normal distribution is defined as:
\[f(x) = \sqrt{\frac{2}{\pi}} \exp (-\frac{x^2}{2}), \quad x \ge 0.\]
Consider simulating values from this distribution using the accept–reject method with a candidate distribution of an Exponential random variable with parameter \(\lambda = 1\)
\[g(x)= e^{-x}, \quad x \ge 0.\]
Find the inverse cdf corresponding to \(g(x).\)
If \(X \sim Exp(\lambda=1)\) then the pdf and cdf are \[
g(x)= e^{-x}, \quad G(x)= 1- e^{-x}.
\]
On the average, how many candidate values will be required to generate 10,000 “accepted” values?
The expected number of candidate values required to generate a single accepted value is \(M,\) so the expected number required to generate 10,000 x-values is \(10,000M \approx 13,155.\)
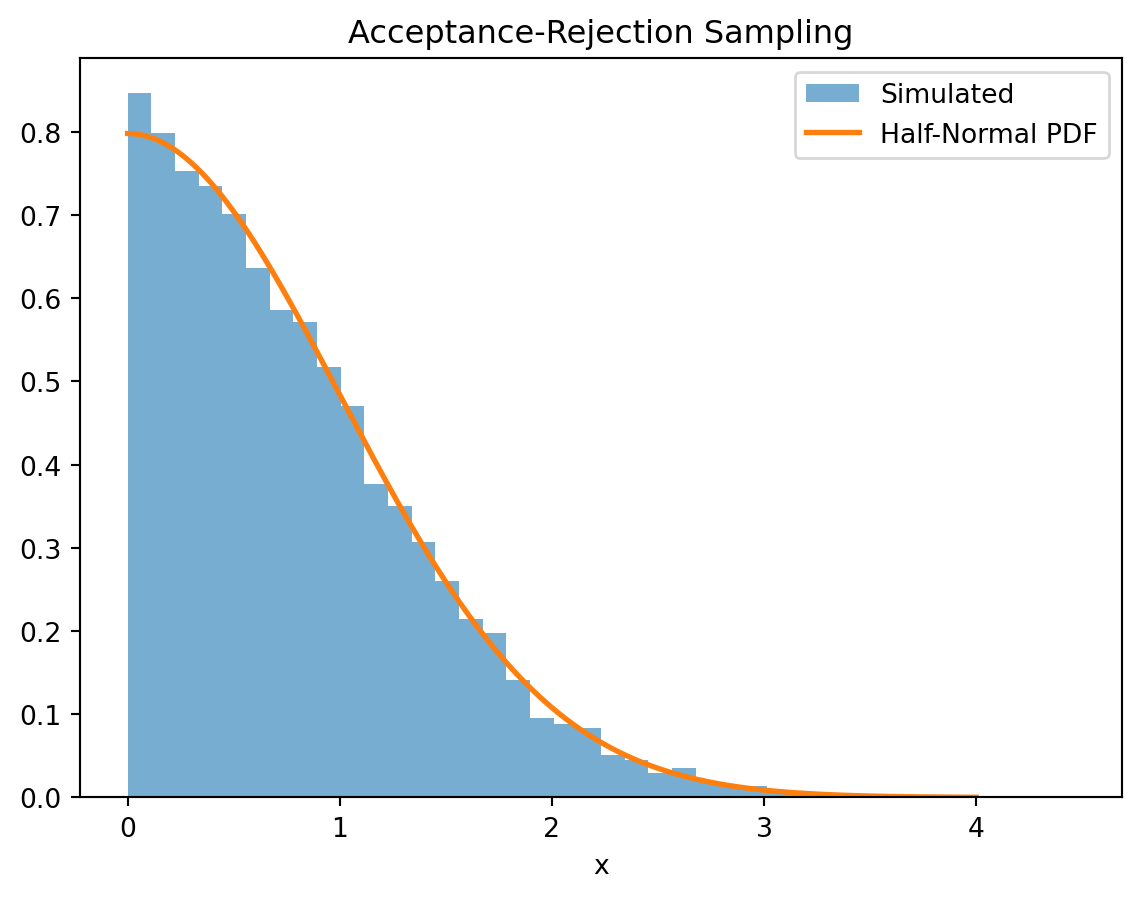
Write a program to construct 10,000 values from a half-normal distribution.
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(1234)n =10000M = np.sqrt(2* np.exp(1) / np.pi)x = []whilelen(x) < n: m = n -len(x) # how many more needed y = np.random.exponential(scale=1, size=m) # Exp(1) u = np.random.rand(m) # Uniform(0,1) fg_ratio = np.sqrt(2/ np.pi) * np.exp(-y**2/2+ y) accept = u <= fg_ratio / M x.extend(y[accept])# Trim to exactly n samplesx = np.array(x[:n])plt.hist(x, bins=40, density=True, alpha=0.6, label="Simulated")t = np.linspace(0, 4, 500)true_pdf = np.sqrt(2/ np.pi) * np.exp(-t**2/2)plt.plot(t, true_pdf, linewidth=2, label="Half-Normal PDF")plt.title("Acceptance-Rejection Sampling")plt.xlabel("x")plt.legend()plt.show()