Air pollution is a major environmental and public health concern, particularly in urban areas where emissions from traffic, industry, and weather conditions interact in complex ways. Monitoring pollution levels across multiple locations is essential for understanding spatial patterns, assessing risk, and informing policy decisions.
In practice, pollution measurements at nearby locations are not independent. For example, wind direction, temperature, and regional emission sources can cause pollution levels at different monitoring stations to rise and fall together. As a result, modelling each location separately fails to capture the true joint behaviour of the system.
A natural way to model such data is through a multivariate normal distribution, where each component represents pollution levels at a different site, and the covariance matrix encodes the dependence between locations. This allows us to simulate realistic scenarios in which pollution levels co-vary across space.
In this example, we compare the differences between:
Frequentist MVN: treat \(\mu\) and \(\Sigma\) as fixed and known
Bayesian MVN: treat \(\mu\) and \(\Sigma\) as unknown and assign priors
Background
We consider pollution levels (e.g., PM2.5 concentration) measured at three nearby monitoring stations:
Site A:\(X_1\)
Site B:\(X_2\)
Site C:\(X_3\)
Because the sites are geographically close, pollution levels tend to move together due to shared weather conditions, traffic patterns, and regional emission sources. A multivariate normal model provides a natural way to describe this joint behaviour.
We assume that the vector of pollution levels follows a multivariate normal distribution:
simulate realistic pollution levels across the three sites while preserving both the marginal behaviour and the dependence structure between locations.
To achieve this, we will construct samples from the multivariate normal distribution using Cholesky decomposition, which allows us to transform independent standard normal variables into correlated variables with the desired covariance structure.
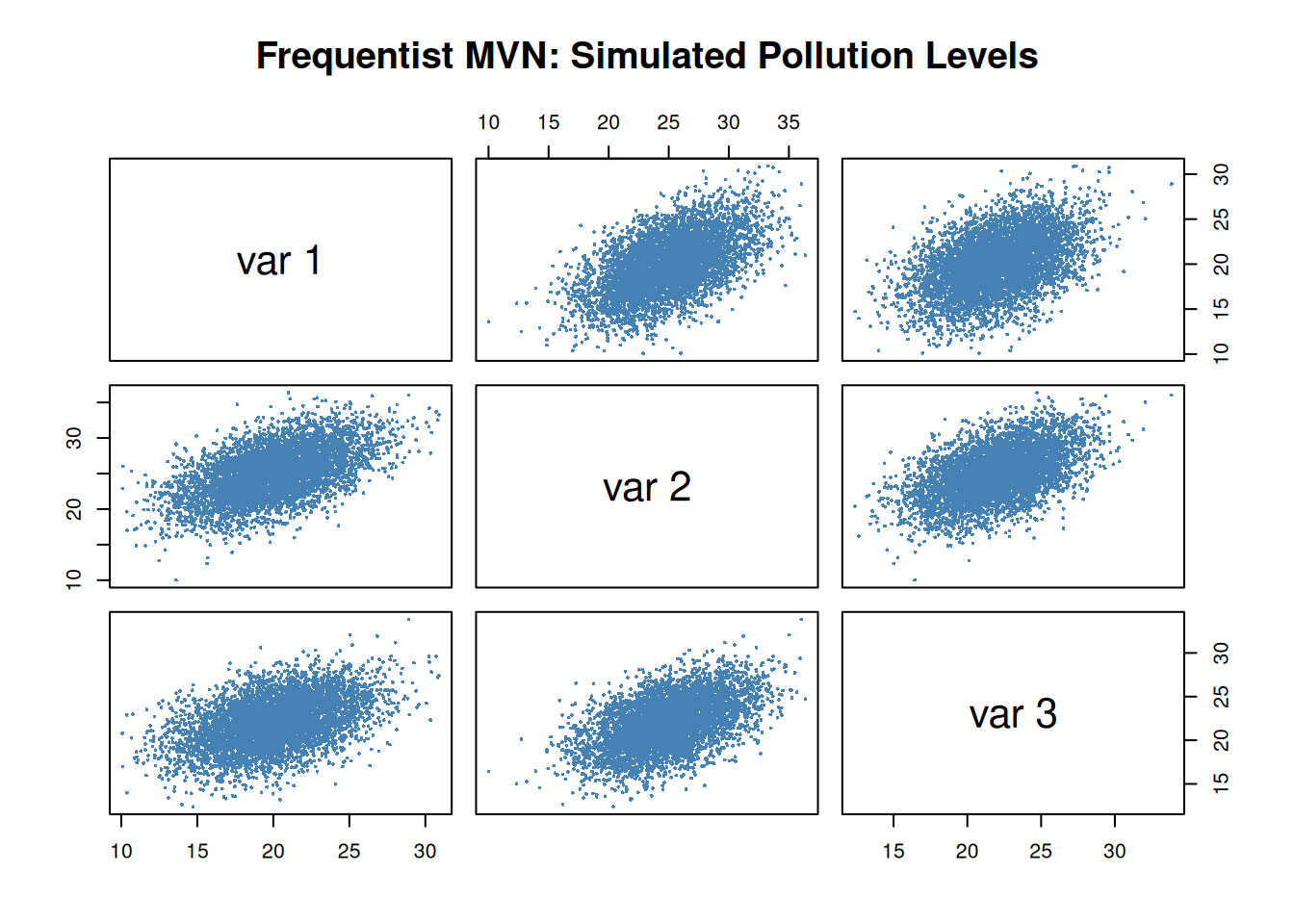
Frequentist MVN
In the frequentist version, we assume that the mean vector and covariance matrix are known constants. Our goal is simply to simulate pollution levels that have the required averages and dependence structure.
This is useful when:
parameters are given from historical estimates,
we want to generate synthetic data,
or we want to understand how covariance affects the joint behaviour.
\(\mu\) gives the average pollution level at each site,
\(\Sigma\) describes the variability and dependence.
Then, we simulate realistic pollution measurements at the three sites assuming the mean vector and covariance matrix are known. Use Cholesky decomposition to generate correlated samples from the multivariate normal distribution.
set.seed(123)# Mean vectormu <-c(20, 25, 22)# Covariance matrixSigma <-matrix(c(10, 6, 4,6, 12, 5,4, 5, 8), 3, 3)# Cholesky factorL <-chol(Sigma)# Simulate standard normalsn <-5000Z <-matrix(rnorm(3* n), n, 3)# Construct correlated MVN sampleX <- Z %*% L +matrix(mu, n, 3, byrow =TRUE)# Check resultscolMeans(X)
The sample covariance matrix should be close to \(\Sigma\).
The scatterplots should show positive dependence between sites.
In the frequentist MVN model, the parameters are fixed, and we simulate pollution levels conditional on those values.
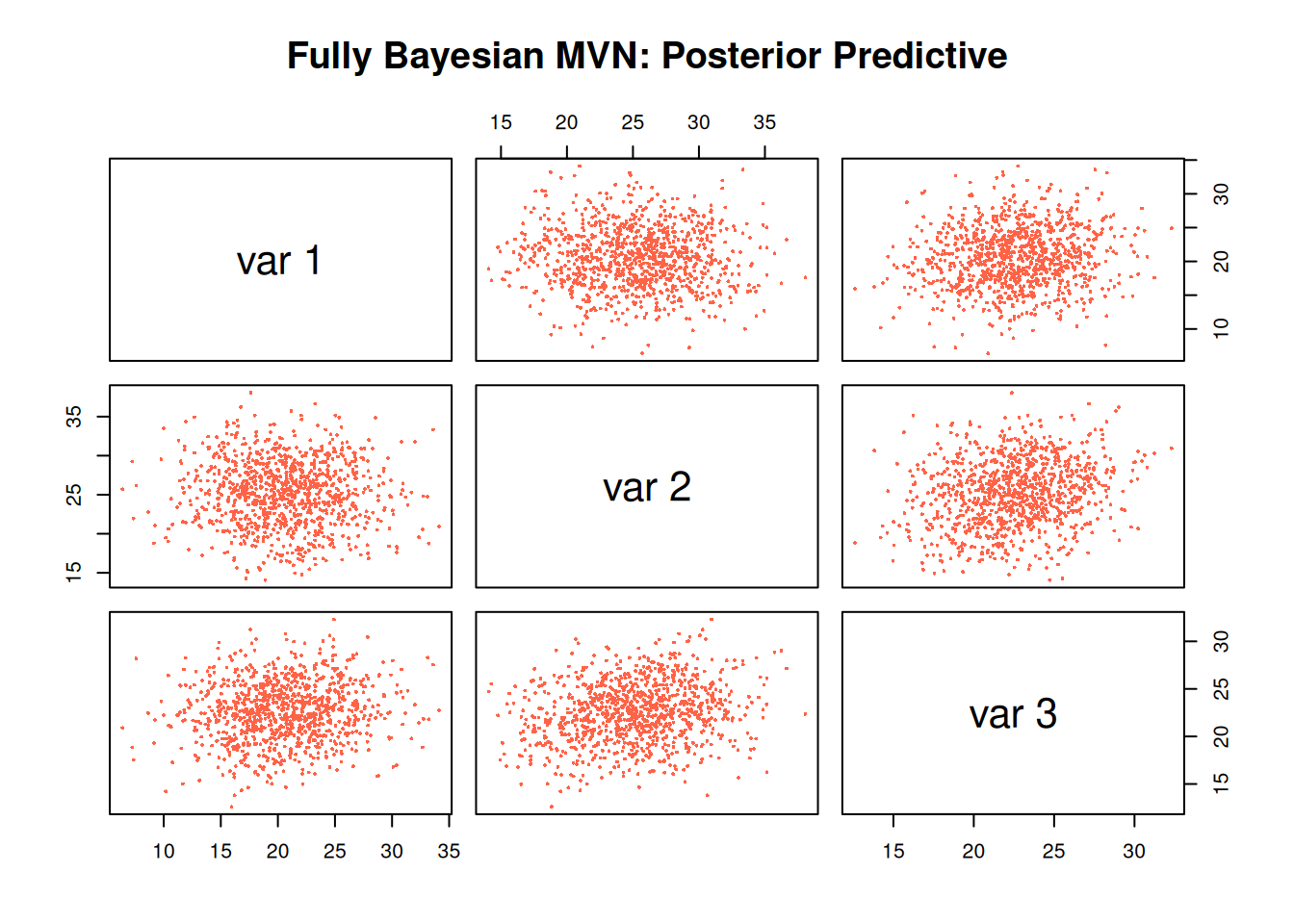
Bayesian MVN
In practice, the true mean pollution levels and covariance structure are usually unknown. A Bayesian approach treats these parameters as random variables and updates them using observed data.
This means we account for two layers of uncertainty:
uncertainty in the pollution measurements themselves,
uncertainty in the unknown parameters \(\mu\) and \(\Sigma\).
In practice, we do not know the true mean vector or covariance matrix. We only observe data and estimate these quantities using the sample mean and sample covariance. In this example, we simulate data using “true” parameters to illustrate the process, but in real applications these parameters must be inferred from data.
library(MASS)set.seed(1234)# Simulate synthetic pollution datamu_true <-c(20, 25, 22) # unknown in realitySigma_true <-matrix(c(10, 6, 4,6, 12, 5,4, 5, 8), 3, 3) # unknown in realityX_obs <-mvrnorm(100, mu = mu_true, Sigma = Sigma_true)# In practice, we estimate parameters from the observed datacolMeans(X_obs)